 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaser: Governing Long-Horizon Agentic Search via Structured Protocol and Context Register
Dec 23, 2025Recent advances in Large Language Models (LLMs) and Large Reasoning Models (LRMs) have enabled agentic search systems that interleave multi-step reasoning with external tool use. However, existing frameworks largely rely on unstructured natural-language reasoning and accumulate raw intermediate traces in the context, which often leads to unstable reasoning trajectories, context overflow, and degraded performance on complex multi-hop queries. In this study, we introduce Laser, a general framework for stabilizing and scaling agentic search. Laser defines a symbolic action protocol that organizes agent behaviors into three spaces: planning, task-solving, and retrospection. Each action is specified with explicit semantics and a deterministic execution format, enabling structured and logical reasoning processes and reliable action parsing. This design makes intermediate decisions interpretable and traceable, enhancing explicit retrospection and fine-grained control over reasoning trajectories. In coordination with parsable actions, Laser further maintains a compact context register that stores only essential states of the reasoning process, allowing the agent to reason over long horizons without uncontrolled context expansion. Experiments on Qwen2.5/3-series models across challenging multi-hop QA datasets show that Laser consistently outperforms existing agentic search baselines under both prompting-only and fine-tuning settings, demonstrating that Laser provides a principled and effective foundation for robust, scalable agentic search.
Decoupled Geometric Parameterization and its Application in Deep Homography Estimation
May 22, 2025



Planar homography, with eight degrees of freedom (DOFs), is fundamental in numerous computer vision tasks. While the positional offsets of four corners are widely adopted (especially in neural network predictions), this parameterization lacks geometric interpretability and typically requires solving a linear system to compute the homography matrix. This paper presents a novel geometric parameterization of homographies, leveraging the similarity-kernel-similarity (SKS) decomposition for projective transformations. Two independent sets of four geometric parameters are decoupled: one for a similarity transformation and the other for the kernel transformation. Additionally, the geometric interpretation linearly relating the four kernel transformation parameters to angular offsets is derived. Our proposed parameterization allows for direct homography estimation through matrix multiplication, eliminating the need for solving a linear system, and achieves performance comparable to the four-corner positional offsets in deep homography estimation.
OmniEval: An Omnidirectional and Automatic RAG Evaluation Benchmark in Financial Domain
Dec 17, 2024As a typical and practical application of Large Language Models (LLMs), Retrieval-Augmented Generation (RAG) techniques have gained extensive attention, particularly in vertical domains where LLMs may lack domain-specific knowledge. In this paper, we introduce an omnidirectional and automatic RAG benchmark, OmniEval, in the financial domain. Our benchmark is characterized by its multi-dimensional evaluation framework, including (1) a matrix-based RAG scenario evaluation system that categorizes queries into five task classes and 16 financial topics, leading to a structured assessment of diverse query scenarios; (2) a multi-dimensional evaluation data generation approach, which combines GPT-4-based automatic generation and human annotation, achieving an 87.47\% acceptance ratio in human evaluations on generated instances; (3) a multi-stage evaluation system that evaluates both retrieval and generation performance, result in a comprehensive evaluation on the RAG pipeline; and (4) robust evaluation metrics derived from rule-based and LLM-based ones, enhancing the reliability of assessments through manual annotations and supervised fine-tuning of an LLM evaluator. Our experiments demonstrate the comprehensiveness of OmniEval, which includes extensive test datasets and highlights the performance variations of RAG systems across diverse topics and tasks, revealing significant opportunities for RAG models to improve their capabilities in vertical domains. We open source the code of our benchmark in \href{https://github.com/RUC-NLPIR/OmniEval}{https://github.com/RUC-NLPIR/OmniEval}.
LLMs + Persona-Plug = Personalized LLMs
Sep 18, 2024



Personalization plays a critical role in numerous language tasks and applications, since users with the same requirements may prefer diverse outputs based on their individual interests. This has led to the development of various personalized approaches aimed at adapting large language models (LLMs) to generate customized outputs aligned with user preferences. Some of them involve fine-tuning a unique personalized LLM for each user, which is too expensive for widespread application. Alternative approaches introduce personalization information in a plug-and-play manner by retrieving the user's relevant historical texts as demonstrations. However, this retrieval-based strategy may break the continuity of the user history and fail to capture the user's overall styles and patterns, hence leading to sub-optimal performance. To address these challenges, we propose a novel personalized LLM model, \ours{}. It constructs a user-specific embedding for each individual by modeling all her historical contexts through a lightweight plug-in user embedder module. By attaching this embedding to the task input, LLMs can better understand and capture user habits and preferences, thereby producing more personalized outputs without tuning their own parameters. Extensive experiments on various tasks in the language model personalization (LaMP) benchmark demonstrate that the proposed model significantly outperforms existing personalized LLM approaches.
OmniGen: Unified Image Generation
Sep 17, 2024
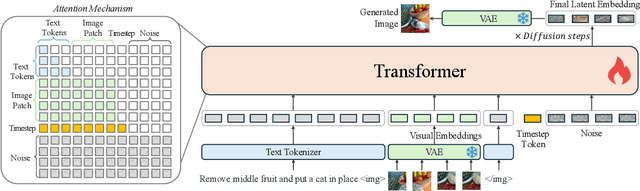
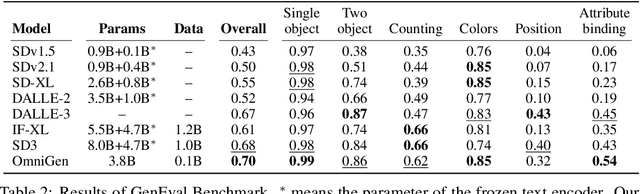

In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues. We will open-source the related resources at https://github.com/VectorSpaceLab/OmniGen to foster advancements in this field.
RichRAG: Crafting Rich Responses for Multi-faceted Queries in Retrieval-Augmented Generation
Jun 18, 2024



Retrieval-augmented generation (RAG) effectively addresses issues of static knowledge and hallucination in large language models. Existing studies mostly focus on question scenarios with clear user intents and concise answers. However, it is prevalent that users issue broad, open-ended queries with diverse sub-intents, for which they desire rich and long-form answers covering multiple relevant aspects. To tackle this important yet underexplored problem, we propose a novel RAG framework, namely RichRAG. It includes a sub-aspect explorer to identify potential sub-aspects of input questions, a multi-faceted retriever to build a candidate pool of diverse external documents related to these sub-aspects, and a generative list-wise ranker, which is a key module to provide the top-k most valuable documents for the final generator. These ranked documents sufficiently cover various query aspects and are aware of the generator's preferences, hence incentivizing it to produce rich and comprehensive responses for users. The training of our ranker involves a supervised fine-tuning stage to ensure the basic coverage of documents, and a reinforcement learning stage to align downstream LLM's preferences to the ranking of documents. Experimental results on two publicly available datasets prove that our framework effectively and efficiently provides comprehensive and satisfying responses to users.
DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Jun 09, 2024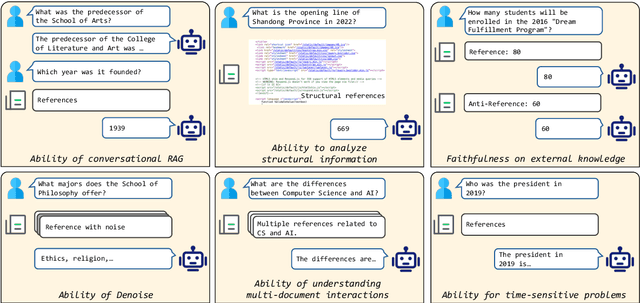
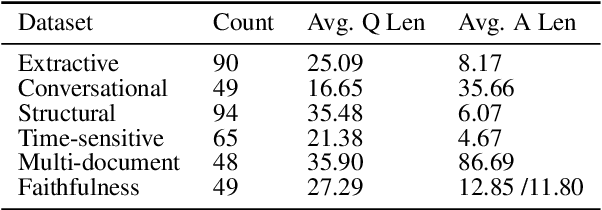
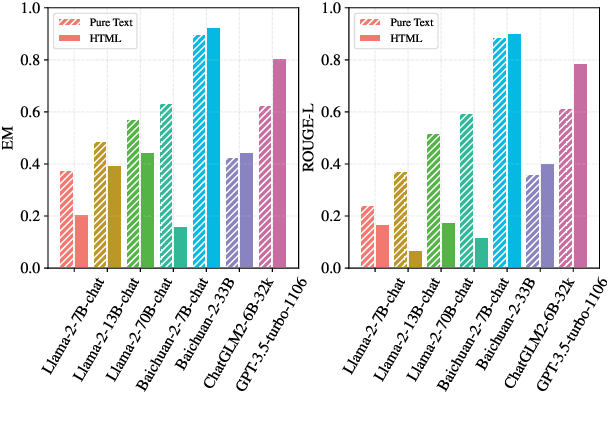
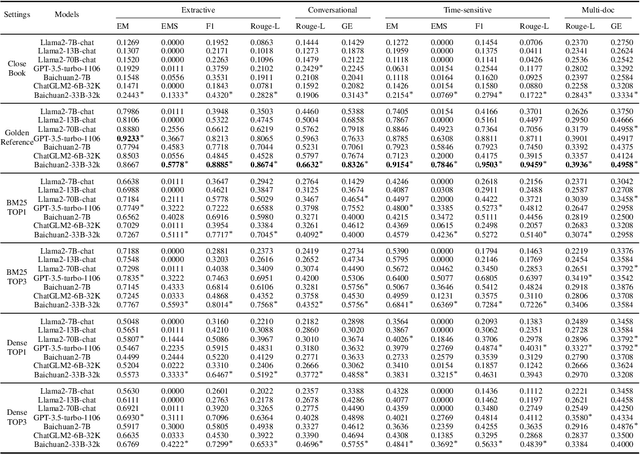
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
Large Language Models for Information Retrieval: A Survey
Aug 15, 2023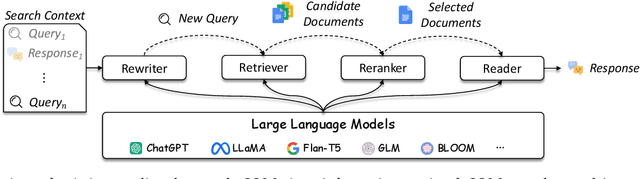
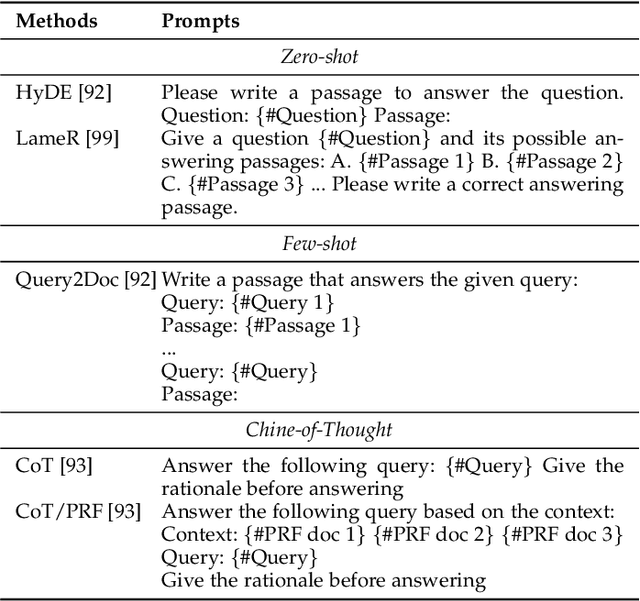
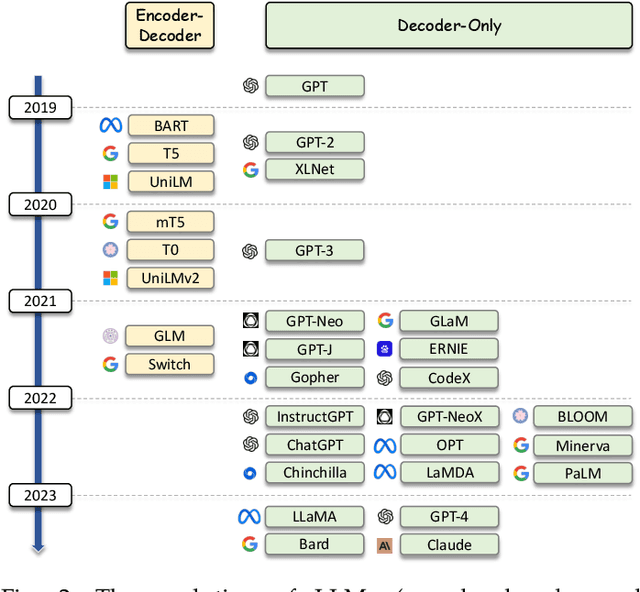
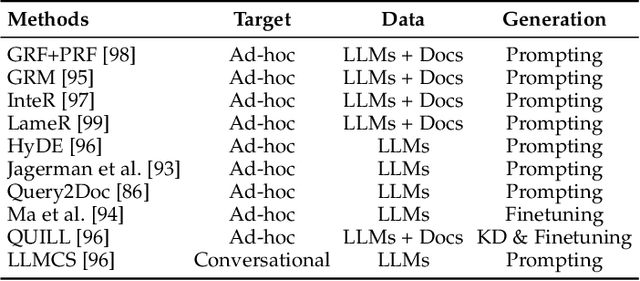
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions within this expanding field.