 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling World Model for Hierarchical Manipulation Policies
Feb 12, 2026Vision-Language-Action (VLA) models are promising for generalist robot manipulation but remain brittle in out-of-distribution (OOD) settings, especially with limited real-robot data. To resolve the generalization bottleneck, we introduce a hierarchical Vision-Language-Action framework \our{} that leverages the generalization of large-scale pre-trained world model for robust and generalizable VIsual Subgoal TAsk decomposition VISTA. Our hierarchical framework \our{} consists of a world model as the high-level planner and a VLA as the low-level executor. The high-level world model first divides manipulation tasks into subtask sequences with goal images, and the low-level policy follows the textual and visual guidance to generate action sequences. Compared to raw textual goal specification, these synthesized goal images provide visually and physically grounded details for low-level policies, making it feasible to generalize across unseen objects and novel scenarios. We validate both visual goal synthesis and our hierarchical VLA policies in massive out-of-distribution scenarios, and the performance of the same-structured VLA in novel scenarios could boost from 14% to 69% with the guidance generated by the world model. Results demonstrate that our method outperforms previous baselines with a clear margin, particularly in out-of-distribution scenarios. Project page: \href{https://vista-wm.github.io/}{https://vista-wm.github.io}
OpenSubject: Leveraging Video-Derived Identity and Diversity Priors for Subject-driven Image Generation and Manipulation
Dec 10, 2025Despite the promising progress in subject-driven image generation, current models often deviate from the reference identities and struggle in complex scenes with multiple subjects. To address this challenge, we introduce OpenSubject, a video-derived large-scale corpus with 2.5M samples and 4.35M images for subject-driven generation and manipulation. The dataset is built with a four-stage pipeline that exploits cross-frame identity priors. (i) Video Curation. We apply resolution and aesthetic filtering to obtain high-quality clips. (ii) Cross-Frame Subject Mining and Pairing. We utilize vision-language model (VLM)-based category consensus, local grounding, and diversity-aware pairing to select image pairs. (iii) Identity-Preserving Reference Image Synthesis. We introduce segmentation map-guided outpainting to synthesize the input images for subject-driven generation and box-guided inpainting to generate input images for subject-driven manipulation, together with geometry-aware augmentations and irregular boundary erosion. (iv) Verification and Captioning. We utilize a VLM to validate synthesized samples, re-synthesize failed samples based on stage (iii), and then construct short and long captions. In addition, we introduce a benchmark covering subject-driven generation and manipulation, and then evaluate identity fidelity, prompt adherence, manipulation consistency, and background consistency with a VLM judge. Extensive experiments show that training with OpenSubject improves generation and manipulation performance, particularly in complex scenes.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
MomentSeeker: A Comprehensive Benchmark and A Strong Baseline For Moment Retrieval Within Long Videos
Feb 18, 2025Retrieval augmented generation (RAG) holds great promise in addressing challenges associated with long video understanding. These methods retrieve useful moments from long videos for their presented tasks, thereby enabling multimodal large language models (MLLMs) to generate high-quality answers in a cost-effective way. In this work, we present MomentSeeker, a comprehensive benchmark to evaluate retrieval models' performance in handling general long-video moment retrieval (LVMR) tasks. MomentSeeker offers three key advantages. First, it incorporates long videos of over 500 seconds on average, making it the first benchmark specialized for long-video moment retrieval. Second, it covers a wide range of task categories (including Moment Search, Caption Alignment, Image-conditioned Moment Search, and Video-conditioned Moment Search) and diverse application scenarios (e.g., sports, movies, cartoons, and ego), making it a comprehensive tool for assessing retrieval models' general LVMR performance. Additionally, the evaluation tasks are carefully curated through human annotation, ensuring the reliability of assessment. We further fine-tune an MLLM-based LVMR retriever on synthetic data, which demonstrates strong performance on our benchmark. We perform extensive experiments with various popular multimodal retrievers based on our benchmark, whose results highlight the challenges of LVMR and limitations for existing methods. Our created resources will be shared with community to advance future research in this field.
EVEv2: Improved Baselines for Encoder-Free Vision-Language Models
Feb 10, 2025



Existing encoder-free vision-language models (VLMs) are rapidly narrowing the performance gap with their encoder-based counterparts, highlighting the promising potential for unified multimodal systems with structural simplicity and efficient deployment. We systematically clarify the performance gap between VLMs using pre-trained vision encoders, discrete tokenizers, and minimalist visual layers from scratch, deeply excavating the under-examined characteristics of encoder-free VLMs. We develop efficient strategies for encoder-free VLMs that rival mainstream encoder-based ones. After an in-depth investigation, we launch EVEv2.0, a new and improved family of encoder-free VLMs. We show that: (i) Properly decomposing and hierarchically associating vision and language within a unified model reduces interference between modalities. (ii) A well-designed training strategy enables effective optimization for encoder-free VLMs. Through extensive evaluation, our EVEv2.0 represents a thorough study for developing a decoder-only architecture across modalities, demonstrating superior data efficiency and strong vision-reasoning capability. Code is publicly available at: https://github.com/baaivision/EVE.
MegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval
Dec 19, 2024Despite the rapidly growing demand for multimodal retrieval, progress in this field remains severely constrained by a lack of training data. In this paper, we introduce MegaPairs, a novel data synthesis method that leverages vision language models (VLMs) and open-domain images, together with a massive synthetic dataset generated from this method. Our empirical analysis shows that MegaPairs generates high-quality data, enabling the multimodal retriever to significantly outperform the baseline model trained on 70$\times$ more data from existing datasets. Moreover, since MegaPairs solely relies on general image corpora and open-source VLMs, it can be easily scaled up, enabling continuous improvements in retrieval performance. In this stage, we produced more than 26 million training instances and trained several models of varying sizes using this data. These new models achieve state-of-the-art zero-shot performance across 4 popular composed image retrieval (CIR) benchmarks and the highest overall performance on the 36 datasets provided by MMEB. They also demonstrate notable performance improvements with additional downstream fine-tuning. Our produced dataset, well-trained models, and data synthesis pipeline will be made publicly available to facilitate the future development of this field.
Emu3: Next-Token Prediction is All You Need
Sep 27, 2024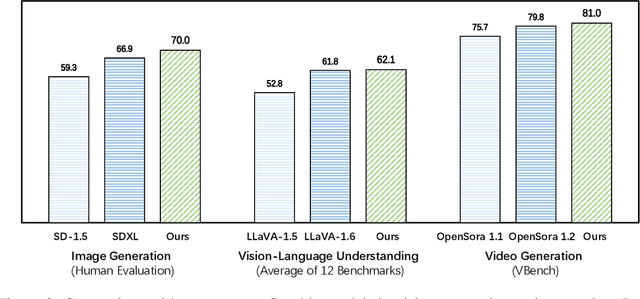


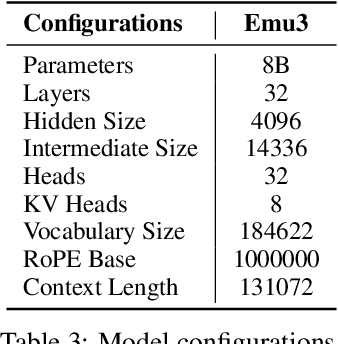
While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.
OmniGen: Unified Image Generation
Sep 17, 2024
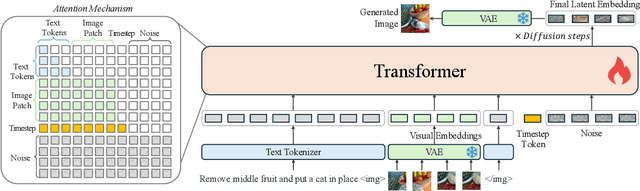
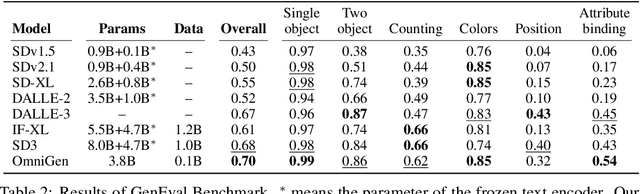

In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues. We will open-source the related resources at https://github.com/VectorSpaceLab/OmniGen to foster advancements in this field.
DenseFusion-1M: Merging Vision Experts for Comprehensive Multimodal Perception
Jul 11, 2024



Existing Multimodal Large Language Models (MLLMs) increasingly emphasize complex understanding of various visual elements, including multiple objects, text information, and spatial relations. Their development for comprehensive visual perception hinges on the availability of high-quality image-text datasets that offer diverse visual elements and throughout image descriptions. However, the scarcity of such hyper-detailed datasets currently hinders progress within the MLLM community. The bottleneck stems from the limited perceptual capabilities of current caption engines, which fall short in providing complete and accurate annotations. To facilitate the cutting-edge research of MLLMs on comprehensive vision perception, we thereby propose Perceptual Fusion, using a low-budget but highly effective caption engine for complete and accurate image descriptions. Specifically, Perceptual Fusion integrates diverse perception experts as image priors to provide explicit information on visual elements and adopts an efficient MLLM as a centric pivot to mimic advanced MLLMs' perception abilities. We carefully select 1M highly representative images from uncurated LAION dataset and generate dense descriptions using our engine, dubbed DenseFusion-1M. Extensive experiments validate that our engine outperforms its counterparts, where the resulting dataset significantly improves the perception and cognition abilities of existing MLLMs across diverse vision-language benchmarks, especially with high-resolution images as inputs. The dataset and code are publicly available at https://github.com/baaivision/DenseFusion.