 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Horizon GUI Agents via Training-Free KV Cache Compression
Feb 27, 2026Large Vision-Language Models (VLMs) have emerged as powerful engines for autonomous GUI agents, yet their deployment is severely constrained by the substantial memory footprint and latency of the Key-Value (KV) cache during long-horizon interactions. While existing cache compression methods have proven effective for LLMs, we empirically demonstrate that they suffer from suboptimal performance in GUI scenarios due to a fundamental misalignment: unlike general visual tasks where attention sparsity varies across layers, GUI attention patterns exhibit uniform high-sparsity across all transformer layers. Motivated by this insight, we propose ST-Lite, a training-free KV cache compression framework tailored for efficient GUI agents that explicitly addresses the dynamic spatio-trajectory dependencies within GUI data streams. ST-Lite introduces a novel dual-branch scoring policy incorporating Component-centric Spatial Saliency (CSS) and Trajectory-aware Semantic Gating (TSG). Specifically, CSS preserves the structural integrity of interactive UI elements by evaluating local neighborhood saliency, while TSG mitigates historical redundancy by dynamically filtering visually repetitive KV pairs within the interaction trajectory. Extensive evaluations demonstrate that with only a 10-20% cache budget, ST-Lite achieves a 2.45x decoding acceleration while maintaining comparable or even superior performance compared to full-cache baselines, offering a scalable solution for resource-constrained GUI agents.
SAIL: Self-Amplified Iterative Learning for Diffusion Model Alignment with Minimal Human Feedback
Feb 05, 2026Aligning diffusion models with human preferences remains challenging, particularly when reward models are unavailable or impractical to obtain, and collecting large-scale preference datasets is prohibitively expensive. \textit{This raises a fundamental question: can we achieve effective alignment using only minimal human feedback, without auxiliary reward models, by unlocking the latent capabilities within diffusion models themselves?} In this paper, we propose \textbf{SAIL} (\textbf{S}elf-\textbf{A}mplified \textbf{I}terative \textbf{L}earning), a novel framework that enables diffusion models to act as their own teachers through iterative self-improvement. Starting from a minimal seed set of human-annotated preference pairs, SAIL operates in a closed-loop manner where the model progressively generates diverse samples, self-annotates preferences based on its evolving understanding, and refines itself using this self-augmented dataset. To ensure robust learning and prevent catastrophic forgetting, we introduce a ranked preference mixup strategy that carefully balances exploration with adherence to initial human priors. Extensive experiments demonstrate that SAIL consistently outperforms state-of-the-art methods across multiple benchmarks while using merely 6\% of the preference data required by existing approaches, revealing that diffusion models possess remarkable self-improvement capabilities that, when properly harnessed, can effectively replace both large-scale human annotation and external reward models.
MetaToolAgent: Towards Generalizable Tool Usage in LLMs through Meta-Learning
Jan 19, 2026Tool learning is increasingly important for large language models (LLMs) to effectively coordinate and utilize a diverse set of tools in order to solve complex real-world tasks. By selecting and integrating appropriate tools, LLMs extend their capabilities beyond pure language understanding to perform specialized functions. However, existing methods for tool selection often focus on limited tool sets and struggle to generalize to novel tools encountered in practical deployments. To address these challenges, we introduce a comprehensive dataset spanning 7 domains, containing 155 tools and 9,377 question-answer pairs, which simulates realistic integration scenarios. Additionally, we propose MetaToolAgent (MTA), a meta-learning approach designed to improve cross-tool generalization. Experimental results show that MTA significantly outperforms baseline methods on unseen tools, demonstrating its promise for building flexible and scalable systems that require dynamic tool coordination.
OmniGen2: Exploration to Advanced Multimodal Generation
Jun 23, 2025In this work, we introduce OmniGen2, a versatile and open-source generative model designed to provide a unified solution for diverse generation tasks, including text-to-image, image editing, and in-context generation. Unlike OmniGen v1, OmniGen2 features two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. This design enables OmniGen2 to build upon existing multimodal understanding models without the need to re-adapt VAE inputs, thereby preserving the original text generation capabilities. To facilitate the training of OmniGen2, we developed comprehensive data construction pipelines, encompassing image editing and in-context generation data. Additionally, we introduce a reflection mechanism tailored for image generation tasks and curate a dedicated reflection dataset based on OmniGen2. Despite its relatively modest parameter size, OmniGen2 achieves competitive results on multiple task benchmarks, including text-to-image and image editing. To further evaluate in-context generation, also referred to as subject-driven tasks, we introduce a new benchmark named OmniContext. OmniGen2 achieves state-of-the-art performance among open-source models in terms of consistency. We will release our models, training code, datasets, and data construction pipeline to support future research in this field. Project Page: https://vectorspacelab.github.io/OmniGen2; GitHub Link: https://github.com/VectorSpaceLab/OmniGen2
DropEdge not Foolproof: Effective Augmentation Method for Signed Graph Neural Networks
Sep 29, 2024



The paper discusses signed graphs, which model friendly or antagonistic relationships using edges marked with positive or negative signs, focusing on the task of link sign prediction. While Signed Graph Neural Networks (SGNNs) have advanced, they face challenges like graph sparsity and unbalanced triangles. The authors propose using data augmentation (DA) techniques to address these issues, although many existing methods are not suitable for signed graphs due to a lack of side information. They highlight that the random DropEdge method, a rare DA approach applicable to signed graphs, does not enhance link sign prediction performance. In response, they introduce the Signed Graph Augmentation (SGA) framework, which includes a structure augmentation module to identify candidate edges and a strategy for selecting beneficial candidates, ultimately improving SGNN training. Experimental results show that SGA significantly boosts the performance of SGNN models, with a notable 32.3% improvement in F1-micro for SGCN on the Slashdot dataset.
Generative Meta-Learning for Zero-Shot Relation Triplet Extraction
May 03, 2023



The zero-shot relation triplet extraction (ZeroRTE) task aims to extract relation triplets from a piece of text with unseen relation types. The seminal work adopts the pre-trained generative model to generate synthetic samples for new relations. However, current generative models lack the optimization process of model generalization on different tasks during training, and thus have limited generalization capability. For this reason, we propose a novel generative meta-learning framework which exploits the `learning-to-learn' ability of meta-learning to boost the generalization capability of generative models. Specifically, we first design a task-aware generative model which can learn the general knowledge by forcing the optimization process to be conducted across multiple tasks. Based on it, we then present three generative meta-learning approaches designated for three typical meta-learning categories. Extensive experimental results demonstrate that our framework achieves a new state-of-the-art performance for the ZeroRTE task.
From Consensus to Disagreement: Multi-Teacher Distillation for Semi-Supervised Relation Extraction
Dec 02, 2021


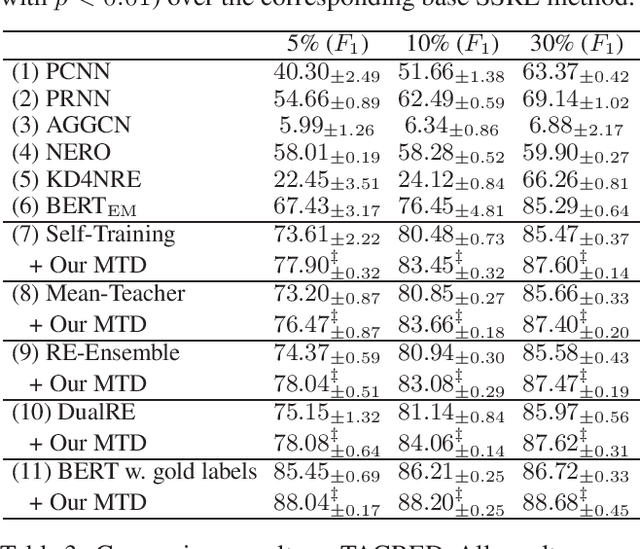
Lack of labeled data is a main obstacle in relation extraction. Semi-supervised relation extraction (SSRE) has been proven to be a promising way for this problem through annotating unlabeled samples as additional training data. Almost all prior researches along this line adopt multiple models to make the annotations more reliable by taking the intersection set of predicted results from these models. However, the difference set, which contains rich information about unlabeled data, has been long neglected by prior studies. In this paper, we propose to learn not only from the consensus but also the disagreement among different models in SSRE. To this end, we develop a simple and general multi-teacher distillation (MTD) framework, which can be easily integrated into any existing SSRE methods. Specifically, we first let the teachers correspond to the multiple models and select the samples in the intersection set of the last iteration in SSRE methods to augment labeled data as usual. We then transfer the class distributions for samples in the difference set as soft labels to guide the student. We finally perform prediction using the trained student model. Experimental results on two public datasets demonstrate that our framework significantly promotes the performance of the base SSRE methods with pretty low computational cost.
Exploit Multiple Reference Graphs for Semi-supervised Relation Extraction
Oct 22, 2020



Manual annotation of the labeled data for relation extraction is time-consuming and labor-intensive. Semi-supervised methods can offer helping hands for this problem and have aroused great research interests. Existing work focuses on mapping the unlabeled samples to the classes to augment the labeled dataset. However, it is hard to find an overall good mapping function, especially for the samples with complicated syntactic components in one sentence. To tackle this limitation, we propose to build the connection between the unlabeled data and the labeled ones rather than directly mapping the unlabeled samples to the classes. Specifically, we first use three kinds of information to construct reference graphs, including entity reference, verb reference, and semantics reference. The goal is to semantically or lexically connect the unlabeled sample(s) to the labeled one(s). Then, we develop a Multiple Reference Graph (MRefG) model to exploit the reference information for better recognizing high-quality unlabeled samples. The effectiveness of our method is demonstrated by extensive comparison experiments with the state-of-the-art baselines on two public datasets.