 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropEdge not Foolproof: Effective Augmentation Method for Signed Graph Neural Networks
Sep 29, 2024



The paper discusses signed graphs, which model friendly or antagonistic relationships using edges marked with positive or negative signs, focusing on the task of link sign prediction. While Signed Graph Neural Networks (SGNNs) have advanced, they face challenges like graph sparsity and unbalanced triangles. The authors propose using data augmentation (DA) techniques to address these issues, although many existing methods are not suitable for signed graphs due to a lack of side information. They highlight that the random DropEdge method, a rare DA approach applicable to signed graphs, does not enhance link sign prediction performance. In response, they introduce the Signed Graph Augmentation (SGA) framework, which includes a structure augmentation module to identify candidate edges and a strategy for selecting beneficial candidates, ultimately improving SGNN training. Experimental results show that SGA significantly boosts the performance of SGNN models, with a notable 32.3% improvement in F1-micro for SGCN on the Slashdot dataset.
Assessing Phrase Break of ESL Speech with Pre-trained Language Models and Large Language Models
Jun 08, 2023



This work introduces approaches to assessing phrase breaks in ESL learners' speech using pre-trained language models (PLMs) and large language models (LLMs). There are two tasks: overall assessment of phrase break for a speech clip and fine-grained assessment of every possible phrase break position. To leverage NLP models, speech input is first force-aligned with texts, and then pre-processed into a token sequence, including words and phrase break information. To utilize PLMs, we propose a pre-training and fine-tuning pipeline with the processed tokens. This process includes pre-training with a replaced break token detection module and fine-tuning with text classification and sequence labeling. To employ LLMs, we design prompts for ChatGPT. The experiments show that with the PLMs, the dependence on labeled training data has been greatly reduced, and the performance has improved. Meanwhile, we verify that ChatGPT, a renowned LLM, has potential for further advancement in this area.
Assessing Phrase Break of ESL speech with Pre-trained Language Models
Oct 28, 2022


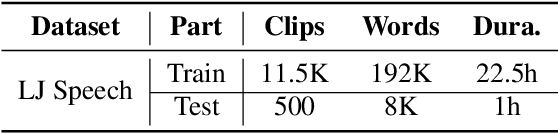
This work introduces an approach to assessing phrase break in ESL learners' speech with pre-trained language models (PLMs). Different with traditional methods, this proposal converts speech to token sequences, and then leverages the power of PLMs. There are two sub-tasks: overall assessment of phrase break for a speech clip; fine-grained assessment of every possible phrase break position. Speech input is first force-aligned with texts, then pre-processed to a token sequence, including words and associated phrase break information. The token sequence is then fed into the pre-training and fine-tuning pipeline. In pre-training, a replaced break token detection module is trained with token data where each token has a certain percentage chance to be randomly replaced. In fine-tuning, overall and fine-grained scoring are optimized with text classification and sequence labeling pipeline, respectively. With the introduction of PLMs, the dependence on labeled training data has been greatly reduced, and performance has improved.
A free lunch from ViT:Adaptive Attention Multi-scale Fusion Transformer for Fine-grained Visual Recognition
Oct 11, 2021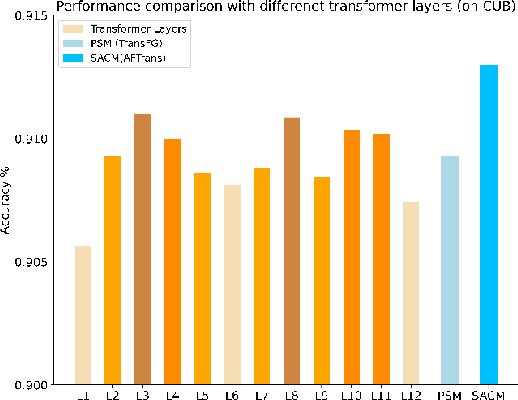
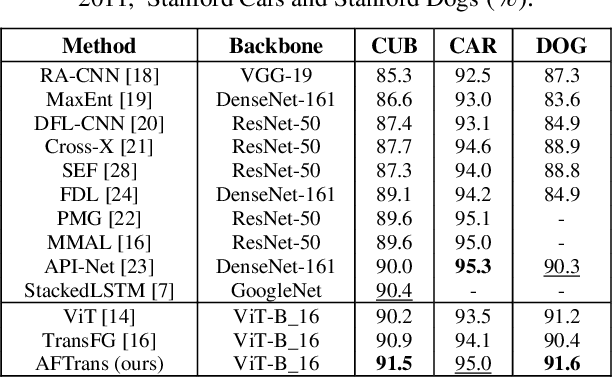
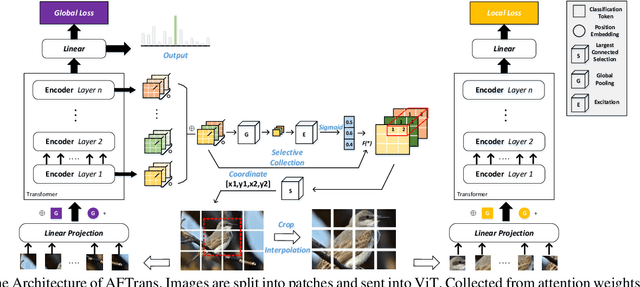

Learning subtle representation about object parts plays a vital role in fine-grained visual recognition (FGVR) field. The vision transformer (ViT) achieves promising results on computer vision due to its attention mechanism. Nonetheless, with the fixed size of patches in ViT, the class token in deep layer focuses on the global receptive field and cannot generate multi-granularity features for FGVR. To capture region attention without box annotations and compensate for ViT shortcomings in FGVR, we propose a novel method named Adaptive attention multi-scale Fusion Transformer (AFTrans). The Selective Attention Collection Module (SACM) in our approach leverages attention weights in ViT and filters them adaptively to correspond with the relative importance of input patches. The multiple scales (global and local) pipeline is supervised by our weights sharing encoder and can be easily trained end-to-end. Comprehensive experiments demonstrate that AFTrans can achieve SOTA performance on three published fine-grained benchmarks: CUB-200-2011, Stanford Dogs and iNat2017.