 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
A Call for New Recipes to Enhance Spatial Reasoning in MLLMs
Apr 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in general vision-language tasks. However, recent studies have exposed critical limitations in their spatial reasoning capabilities. This deficiency in spatial reasoning significantly constrains MLLMs' ability to interact effectively with the physical world, thereby limiting their broader applications. We argue that spatial reasoning capabilities will not naturally emerge from merely scaling existing architectures and training methodologies. Instead, this challenge demands dedicated attention to fundamental modifications in the current MLLM development approach. In this position paper, we first establish a comprehensive framework for spatial reasoning within the context of MLLMs. We then elaborate on its pivotal role in real-world applications. Through systematic analysis, we examine how individual components of the current methodology-from training data to reasoning mechanisms-influence spatial reasoning capabilities. This examination reveals critical limitations while simultaneously identifying promising avenues for advancement. Our work aims to direct the AI research community's attention toward these crucial yet underexplored aspects. By highlighting these challenges and opportunities, we seek to catalyze progress toward achieving human-like spatial reasoning capabilities in MLLMs.
FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation
Mar 09, 2025Implementing new features in repository-level codebases is a crucial application of code generation models. However, current benchmarks lack a dedicated evaluation framework for this capability. To fill this gap, we introduce FEA-Bench, a benchmark designed to assess the ability of large language models (LLMs) to perform incremental development within code repositories. We collect pull requests from 83 GitHub repositories and use rule-based and intent-based filtering to construct task instances focused on new feature development. Each task instance containing code changes is paired with relevant unit test files to ensure that the solution can be verified. The feature implementation requires LLMs to simultaneously possess code completion capabilities for new components and code editing abilities for other relevant parts in the code repository, providing a more comprehensive evaluation method of LLMs' automated software engineering capabilities. Experimental results show that LLMs perform significantly worse in the FEA-Bench, highlighting considerable challenges in such repository-level incremental code development.
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Jan 13, 2025



Chain-of-Thought (CoT) prompting has proven highly effective for enhancing complex reasoning in Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Yet, it struggles in complex spatial reasoning tasks. Nonetheless, human cognition extends beyond language alone, enabling the remarkable capability to think in both words and images. Inspired by this mechanism, we propose a new reasoning paradigm, Multimodal Visualization-of-Thought (MVoT). It enables visual thinking in MLLMs by generating image visualizations of their reasoning traces. To ensure high-quality visualization, we introduce token discrepancy loss into autoregressive MLLMs. This innovation significantly improves both visual coherence and fidelity. We validate this approach through several dynamic spatial reasoning tasks. Experimental results reveal that MVoT demonstrates competitive performance across tasks. Moreover, it exhibits robust and reliable improvements in the most challenging scenarios where CoT fails. Ultimately, MVoT establishes new possibilities for complex reasoning tasks where visual thinking can effectively complement verbal reasoning.
MMLU-CF: A Contamination-free Multi-task Language Understanding Benchmark
Dec 19, 2024Multiple-choice question (MCQ) datasets like Massive Multitask Language Understanding (MMLU) are widely used to evaluate the commonsense, understanding, and problem-solving abilities of large language models (LLMs). However, the open-source nature of these benchmarks and the broad sources of training data for LLMs have inevitably led to benchmark contamination, resulting in unreliable evaluation results. To alleviate this issue, we propose a contamination-free and more challenging MCQ benchmark called MMLU-CF. This benchmark reassesses LLMs' understanding of world knowledge by averting both unintentional and malicious data leakage. To avoid unintentional data leakage, we source data from a broader domain and design three decontamination rules. To prevent malicious data leakage, we divide the benchmark into validation and test sets with similar difficulty and subject distributions. The test set remains closed-source to ensure reliable results, while the validation set is publicly available to promote transparency and facilitate independent verification. Our evaluation of mainstream LLMs reveals that the powerful GPT-4o achieves merely a 5-shot score of 73.4% and a 0-shot score of 71.9% on the test set, which indicates the effectiveness of our approach in creating a more rigorous and contamination-free evaluation standard. The GitHub repository is available at https://github.com/microsoft/MMLU-CF and the dataset refers to https://huggingface.co/datasets/microsoft/MMLU-CF.
1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
Oct 21, 2024Recent advances in 1-bit Large Language Models (LLMs), such as BitNet and BitNet b1.58, present a promising approach to enhancing the efficiency of LLMs in terms of speed and energy consumption. These developments also enable local LLM deployment across a broad range of devices. In this work, we introduce bitnet.cpp, a tailored software stack designed to unlock the full potential of 1-bit LLMs. Specifically, we develop a set of kernels to support fast and lossless inference of ternary BitNet b1.58 LLMs on CPUs. Extensive experiments demonstrate that bitnet.cpp achieves significant speedups, ranging from 2.37x to 6.17x on x86 CPUs and from 1.37x to 5.07x on ARM CPUs, across various model sizes. The code is available at https://github.com/microsoft/BitNet.
One Language, Many Gaps: Evaluating Dialect Fairness and Robustness of Large Language Models in Reasoning Tasks
Oct 14, 2024


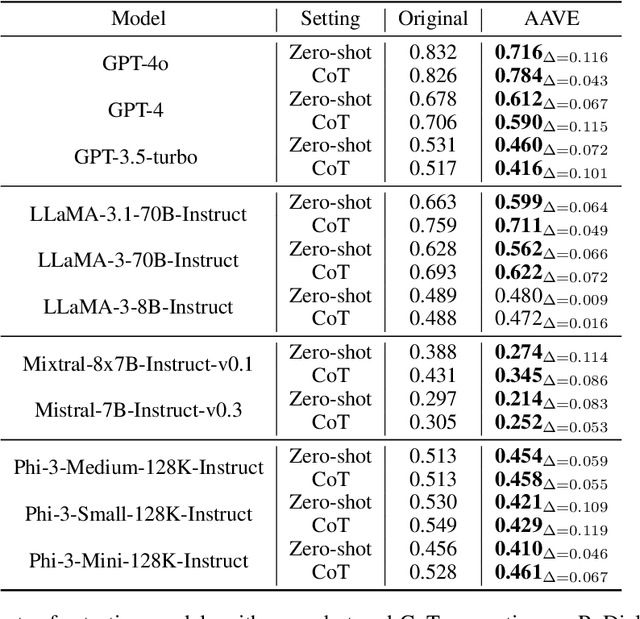
Language is not monolithic. While many benchmarks are used as proxies to systematically estimate Large Language Models' (LLM) performance in real-life tasks, they tend to ignore the nuances of within-language variation and thus fail to model the experience of speakers of minority dialects. Focusing on African American Vernacular English (AAVE), we present the first study on LLMs' fairness and robustness to a dialect in canonical reasoning tasks (algorithm, math, logic, and comprehensive reasoning). We hire AAVE speakers, including experts with computer science backgrounds, to rewrite seven popular benchmarks, such as HumanEval and GSM8K. The result of this effort is ReDial, a dialectal benchmark comprising $1.2K+$ parallel query pairs in Standardized English and AAVE. We use ReDial to evaluate state-of-the-art LLMs, including GPT-4o/4/3.5-turbo, LLaMA-3.1/3, Mistral, and Phi-3. We find that, compared to Standardized English, almost all of these widely used models show significant brittleness and unfairness to queries in AAVE. Furthermore, AAVE queries can degrade performance more substantially than misspelled texts in Standardized English, even when LLMs are more familiar with the AAVE queries. Finally, asking models to rephrase questions in Standardized English does not close the performance gap but generally introduces higher costs. Overall, our findings indicate that LLMs provide unfair service to dialect users in complex reasoning tasks. Code can be found at https://github.com/fangru-lin/redial_dialect_robustness_fairness.git.
CERD: A Comprehensive Chinese Rhetoric Dataset for Rhetorical Understanding and Generation in Essays
Sep 29, 2024



Existing rhetorical understanding and generation datasets or corpora primarily focus on single coarse-grained categories or fine-grained categories, neglecting the common interrelations between different rhetorical devices by treating them as independent sub-tasks. In this paper, we propose the Chinese Essay Rhetoric Dataset (CERD), consisting of 4 commonly used coarse-grained categories including metaphor, personification, hyperbole and parallelism and 23 fine-grained categories across both form and content levels. CERD is a manually annotated and comprehensive Chinese rhetoric dataset with five interrelated sub-tasks. Unlike previous work, our dataset aids in understanding various rhetorical devices, recognizing corresponding rhetorical components, and generating rhetorical sentences under given conditions, thereby improving the author's writing proficiency and language usage skills. Extensive experiments are conducted to demonstrate the interrelations between multiple tasks in CERD, as well as to establish a benchmark for future research on rhetoric. The experimental results indicate that Large Language Models achieve the best performance across most tasks, and jointly fine-tuning with multiple tasks further enhances performance.
Refining Corpora from a Model Calibration Perspective for Chinese Spelling Correction
Jul 22, 2024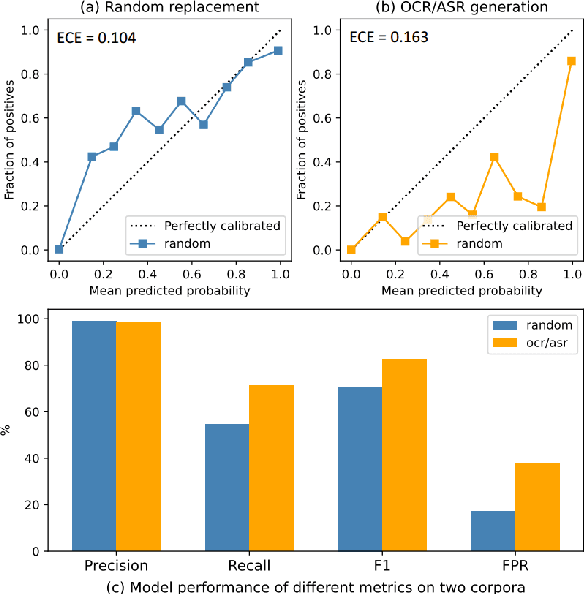

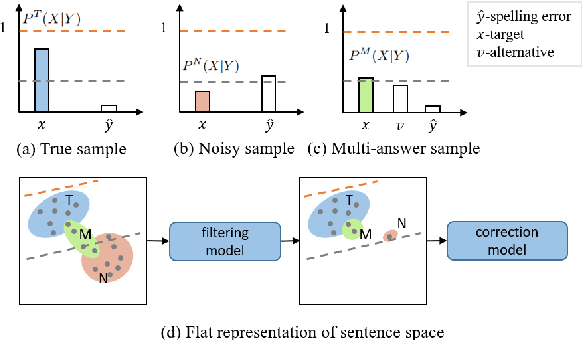
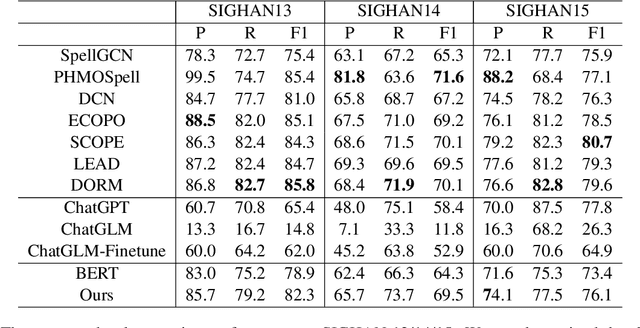
Chinese Spelling Correction (CSC) commonly lacks large-scale high-quality corpora, due to the labor-intensive labeling of spelling errors in real-life human writing or typing scenarios. Two data augmentation methods are widely adopted: (1) \textit{Random Replacement} with the guidance of confusion sets and (2) \textit{OCR/ASR-based Generation} that simulates character misusing. However, both methods inevitably introduce noisy data (e.g., false spelling errors), potentially leading to over-correction. By carefully analyzing the two types of corpora, we find that though the latter achieves more robust generalization performance, the former yields better-calibrated CSC models. We then provide a theoretical analysis of this empirical observation, based on which a corpus refining strategy is proposed. Specifically, OCR/ASR-based data samples are fed into a well-calibrated CSC model trained on random replacement-based corpora and then filtered based on prediction confidence. By learning a simple BERT-based model on the refined OCR/ASR-based corpus, we set up impressive state-of-the-art performance on three widely-used benchmarks, while significantly alleviating over-correction (e.g., lowering false positive predictions).