 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCiV: A Benchmark for Structure, Rhythm and Quality in LLM-Generated Chinese \textit{Ci} Poetry
Feb 15, 2026The generation of classical Chinese \textit{Ci} poetry, a form demanding a sophisticated blend of structural rigidity, rhythmic harmony, and artistic quality, poses a significant challenge for large language models (LLMs). To systematically evaluate and advance this capability, we introduce \textbf{C}hinese \textbf{Ci}pai \textbf{V}ariants (\textbf{CCiV}), a benchmark designed to assess LLM-generated \textit{Ci} poetry across these three dimensions: structure, rhythm, and quality. Our evaluation of 17 LLMs on 30 \textit{Cipai} reveals two critical phenomena: models frequently generate valid but unexpected historical variants of a poetic form, and adherence to tonal patterns is substantially harder than structural rules. We further show that form-aware prompting can improve structural and tonal control for stronger models, while potentially degrading weaker ones. Finally, we observe weak and inconsistent alignment between formal correctness and literary quality in our sample. CCiV highlights the need for variant-aware evaluation and more holistic constrained creative generation methods.
Protein Design with Dynamic Protein Vocabulary
May 25, 2025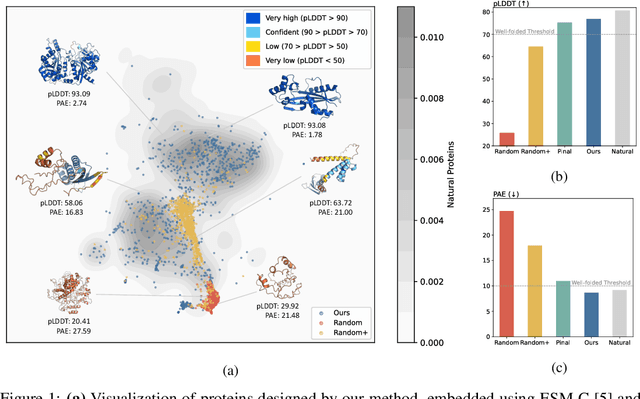
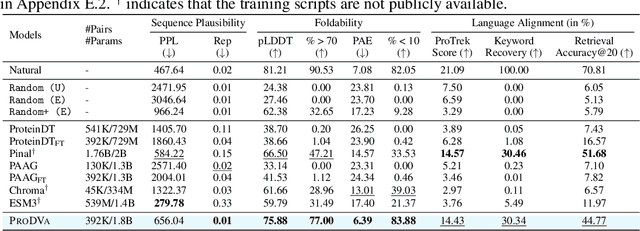
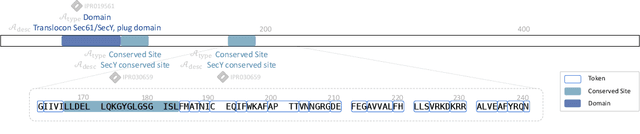
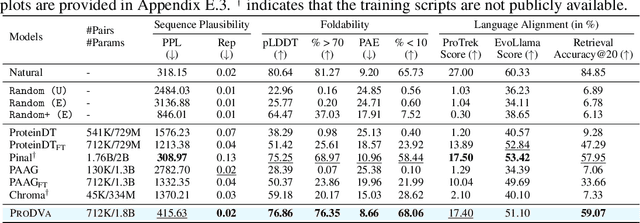
Protein design is a fundamental challenge in biotechnology, aiming to design novel sequences with specific functions within the vast space of possible proteins. Recent advances in deep generative models have enabled function-based protein design from textual descriptions, yet struggle with structural plausibility. Inspired by classical protein design methods that leverage natural protein structures, we explore whether incorporating fragments from natural proteins can enhance foldability in generative models. Our empirical results show that even random incorporation of fragments improves foldability. Building on this insight, we introduce ProDVa, a novel protein design approach that integrates a text encoder for functional descriptions, a protein language model for designing proteins, and a fragment encoder to dynamically retrieve protein fragments based on textual functional descriptions. Experimental results demonstrate that our approach effectively designs protein sequences that are both functionally aligned and structurally plausible. Compared to state-of-the-art models, ProDVa achieves comparable function alignment using less than 0.04% of the training data, while designing significantly more well-folded proteins, with the proportion of proteins having pLDDT above 70 increasing by 7.38% and those with PAE below 10 increasing by 9.6%.
Towards Comprehensive Argument Analysis in Education: Dataset, Tasks, and Method
May 17, 2025



Argument mining has garnered increasing attention over the years, with the recent advancement of Large Language Models (LLMs) further propelling this trend. However, current argument relations remain relatively simplistic and foundational, struggling to capture the full scope of argument information, particularly when it comes to representing complex argument structures in real-world scenarios. To address this limitation, we propose 14 fine-grained relation types from both vertical and horizontal dimensions, thereby capturing the intricate interplay between argument components for a thorough understanding of argument structure. On this basis, we conducted extensive experiments on three tasks: argument component detection, relation prediction, and automated essay grading. Additionally, we explored the impact of writing quality on argument component detection and relation prediction, as well as the connections between discourse relations and argumentative features. The findings highlight the importance of fine-grained argumentative annotations for argumentative writing quality assessment and encourage multi-dimensional argument analysis.
Fùxì: A Benchmark for Evaluating Language Models on Ancient Chinese Text Understanding and Generation
Mar 20, 2025



Ancient Chinese text processing presents unique challenges for large language models (LLMs) due to its distinct linguistic features, complex structural constraints, and rich cultural context. While existing benchmarks have primarily focused on evaluating comprehension through multiple-choice questions, there remains a critical gap in assessing models' generative capabilities in classical Chinese. We introduce F\`ux\`i, a comprehensive benchmark that evaluates both understanding and generation capabilities across 21 diverse tasks. Our benchmark distinguishes itself through three key contributions: (1) balanced coverage of both comprehension and generation tasks, including novel tasks like poetry composition and couplet completion, (2) specialized evaluation metrics designed specifically for classical Chinese text generation, combining rule-based verification with fine-tuned LLM evaluators, and (3) a systematic assessment framework that considers both linguistic accuracy and cultural authenticity. Through extensive evaluation of state-of-the-art LLMs, we reveal significant performance gaps between understanding and generation tasks, with models achieving promising results in comprehension but struggling considerably in generation tasks, particularly those requiring deep cultural knowledge and adherence to classical formats. Our findings highlight the current limitations in ancient Chinese text processing and provide insights for future model development. The benchmark, evaluation toolkit, and baseline results are publicly available to facilitate research in this domain.
EvoLlama: Enhancing LLMs' Understanding of Proteins via Multimodal Structure and Sequence Representations
Dec 16, 2024



Current Large Language Models (LLMs) for understanding proteins primarily treats amino acid sequences as a text modality. Meanwhile, Protein Language Models (PLMs), such as ESM-2, have learned massive sequential evolutionary knowledge from the universe of natural protein sequences. Furthermore, structure-based encoders like ProteinMPNN learn the structural information of proteins through Graph Neural Networks. However, whether the incorporation of protein encoders can enhance the protein understanding of LLMs has not been explored. To bridge this gap, we propose EvoLlama, a multimodal framework that connects a structure-based encoder, a sequence-based protein encoder and an LLM for protein understanding. EvoLlama consists of a ProteinMPNN structure encoder, an ESM-2 protein sequence encoder, a multimodal projector to align protein and text representations and a Llama-3 text decoder. To train EvoLlama, we fine-tune it on protein-oriented instructions and protein property prediction datasets verbalized via natural language instruction templates. Our experiments show that EvoLlama's protein understanding capabilities have been significantly enhanced, outperforming other fine-tuned protein-oriented LLMs in zero-shot settings by an average of 1%-8% and surpassing the state-of-the-art baseline with supervised fine-tuning by an average of 6%. On protein property prediction datasets, our approach achieves promising results that are competitive with state-of-the-art task-specific baselines. We will release our code in a future version.
CERD: A Comprehensive Chinese Rhetoric Dataset for Rhetorical Understanding and Generation in Essays
Sep 29, 2024



Existing rhetorical understanding and generation datasets or corpora primarily focus on single coarse-grained categories or fine-grained categories, neglecting the common interrelations between different rhetorical devices by treating them as independent sub-tasks. In this paper, we propose the Chinese Essay Rhetoric Dataset (CERD), consisting of 4 commonly used coarse-grained categories including metaphor, personification, hyperbole and parallelism and 23 fine-grained categories across both form and content levels. CERD is a manually annotated and comprehensive Chinese rhetoric dataset with five interrelated sub-tasks. Unlike previous work, our dataset aids in understanding various rhetorical devices, recognizing corresponding rhetorical components, and generating rhetorical sentences under given conditions, thereby improving the author's writing proficiency and language usage skills. Extensive experiments are conducted to demonstrate the interrelations between multiple tasks in CERD, as well as to establish a benchmark for future research on rhetoric. The experimental results indicate that Large Language Models achieve the best performance across most tasks, and jointly fine-tuning with multiple tasks further enhances performance.
Cause-Aware Empathetic Response Generation via Chain-of-Thought Fine-Tuning
Aug 21, 2024



Empathetic response generation endows agents with the capability to comprehend dialogue contexts and react to expressed emotions. Previous works predominantly focus on leveraging the speaker's emotional labels, but ignore the importance of emotion cause reasoning in empathetic response generation, which hinders the model's capacity for further affective understanding and cognitive inference. In this paper, we propose a cause-aware empathetic generation approach by integrating emotions and causes through a well-designed Chain-of-Thought (CoT) prompt on Large Language Models (LLMs). Our approach can greatly promote LLMs' performance of empathy by instruction tuning and enhancing the role awareness of an empathetic listener in the prompt. Additionally, we propose to incorporate cause-oriented external knowledge from COMET into the prompt, which improves the diversity of generation and alleviates conflicts between internal and external knowledge at the same time. Experimental results on the benchmark dataset demonstrate that our approach on LLaMA-7b achieves state-of-the-art performance in both automatic and human evaluations.
Enhancing Language Model Rationality with Bi-Directional Deliberation Reasoning
Jul 08, 2024



This paper introduces BI-Directional DEliberation Reasoning (BIDDER), a novel reasoning approach to enhance the decision rationality of language models. Traditional reasoning methods typically rely on historical information and employ uni-directional (left-to-right) reasoning strategy. This lack of bi-directional deliberation reasoning results in limited awareness of potential future outcomes and insufficient integration of historical context, leading to suboptimal decisions. BIDDER addresses this gap by incorporating principles of rational decision-making, specifically managing uncertainty and predicting expected utility. Our approach involves three key processes: Inferring hidden states to represent uncertain information in the decision-making process from historical data; Using these hidden states to predict future potential states and potential outcomes; Integrating historical information (past contexts) and long-term outcomes (future contexts) to inform reasoning. By leveraging bi-directional reasoning, BIDDER ensures thorough exploration of both past and future contexts, leading to more informed and rational decisions. We tested BIDDER's effectiveness in two well-defined scenarios: Poker (Limit Texas Hold'em) and Negotiation. Our experiments demonstrate that BIDDER significantly improves the decision-making capabilities of LLMs and LLM agents.
LLM as a Mastermind: A Survey of Strategic Reasoning with Large Language Models
Apr 01, 2024



This paper presents a comprehensive survey of the current status and opportunities for Large Language Models (LLMs) in strategic reasoning, a sophisticated form of reasoning that necessitates understanding and predicting adversary actions in multi-agent settings while adjusting strategies accordingly. Strategic reasoning is distinguished by its focus on the dynamic and uncertain nature of interactions among multi-agents, where comprehending the environment and anticipating the behavior of others is crucial. We explore the scopes, applications, methodologies, and evaluation metrics related to strategic reasoning with LLMs, highlighting the burgeoning development in this area and the interdisciplinary approaches enhancing their decision-making performance. It aims to systematize and clarify the scattered literature on this subject, providing a systematic review that underscores the importance of strategic reasoning as a critical cognitive capability and offers insights into future research directions and potential improvements.
Temporal Knowledge Graph Completion with Time-sensitive Relations in Hypercomplex Space
Mar 02, 2024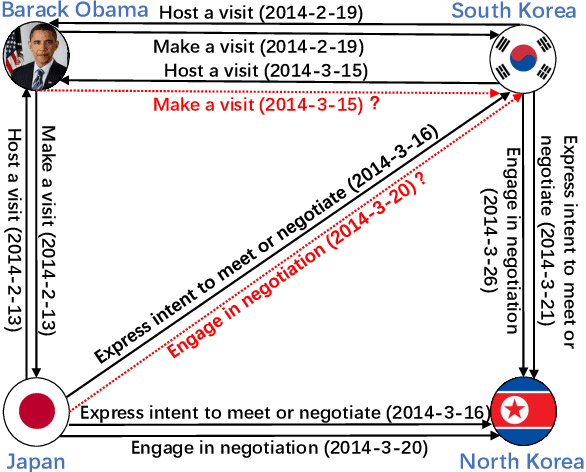

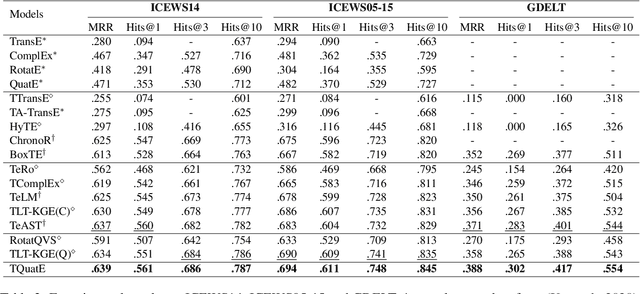
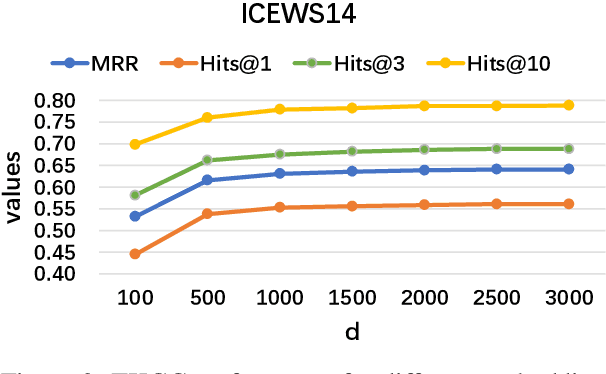
Temporal knowledge graph completion (TKGC) aims to fill in missing facts within a given temporal knowledge graph at a specific time. Existing methods, operating in real or complex spaces, have demonstrated promising performance in this task. This paper advances beyond conventional approaches by introducing more expressive quaternion representations for TKGC within hypercomplex space. Unlike existing quaternion-based methods, our study focuses on capturing time-sensitive relations rather than time-aware entities. Specifically, we model time-sensitive relations through time-aware rotation and periodic time translation, effectively capturing complex temporal variability. Furthermore, we theoretically demonstrate our method's capability to model symmetric, asymmetric, inverse, compositional, and evolutionary relation patterns. Comprehensive experiments on public datasets validate that our proposed approach achieves state-of-the-art performance in the field of TKGC.