 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPP: A Certified Poisoned-Sample Detection Framework for Backdoor Attacks under Dataset Imbalance
Jan 30, 2026Deep neural networks are highly susceptible to backdoor attacks, yet most defense methods to date rely on balanced data, overlooking the pervasive class imbalance in real-world scenarios that can amplify backdoor threats. This paper presents the first in-depth investigation of how the dataset imbalance amplifies backdoor vulnerability, showing that (i) the imbalance induces a majority-class bias that increases susceptibility and (ii) conventional defenses degrade significantly as the imbalance grows. To address this, we propose Randomized Probability Perturbation (RPP), a certified poisoned-sample detection framework that operates in a black-box setting using only model output probabilities. For any inspected sample, RPP determines whether the input has been backdoor-manipulated, while offering provable within-domain detectability guarantees and a probabilistic upper bound on the false positive rate. Extensive experiments on five benchmarks (MNIST, SVHN, CIFAR-10, TinyImageNet and ImageNet10) covering 10 backdoor attacks and 12 baseline defenses show that RPP achieves significantly higher detection accuracy than state-of-the-art defenses, particularly under dataset imbalance. RPP establishes a theoretical and practical foundation for defending against backdoor attacks in real-world environments with imbalanced data.
PRIVEE: Privacy-Preserving Vertical Federated Learning Against Feature Inference Attacks
Dec 14, 2025Vertical Federated Learning (VFL) enables collaborative model training across organizations that share common user samples but hold disjoint feature spaces. Despite its potential, VFL is susceptible to feature inference attacks, in which adversarial parties exploit shared confidence scores (i.e., prediction probabilities) during inference to reconstruct private input features of other participants. To counter this threat, we propose PRIVEE (PRIvacy-preserving Vertical fEderated lEarning), a novel defense mechanism named after the French word privée, meaning "private." PRIVEE obfuscates confidence scores while preserving critical properties such as relative ranking and inter-score distances. Rather than exposing raw scores, PRIVEE shares only the transformed representations, mitigating the risk of reconstruction attacks without degrading model prediction accuracy. Extensive experiments show that PRIVEE achieves a threefold improvement in privacy protection compared to state-of-the-art defenses, while preserving full predictive performance against advanced feature inference attacks.
Superpixel Boundary Correction for Weakly-Supervised Semantic Segmentation on Histopathology Images
Jan 07, 2025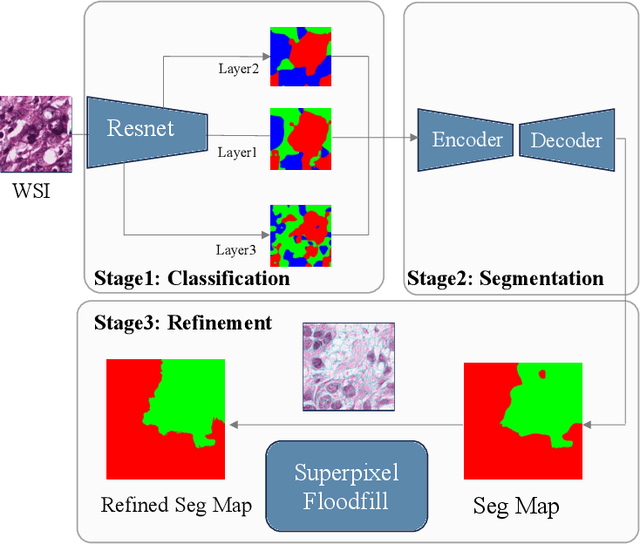
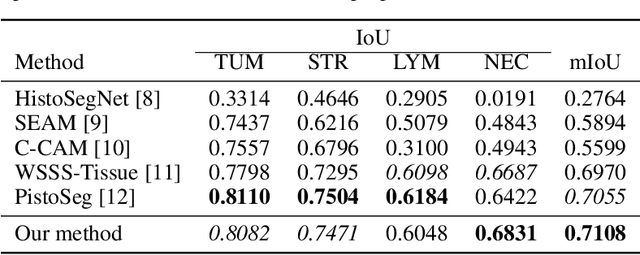
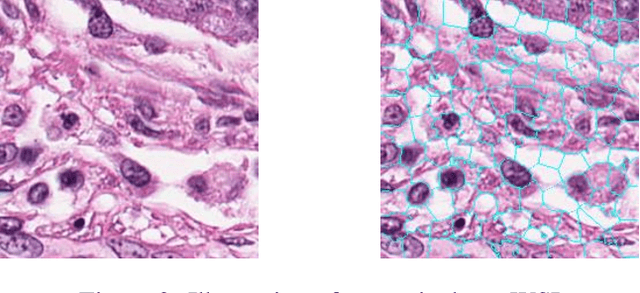
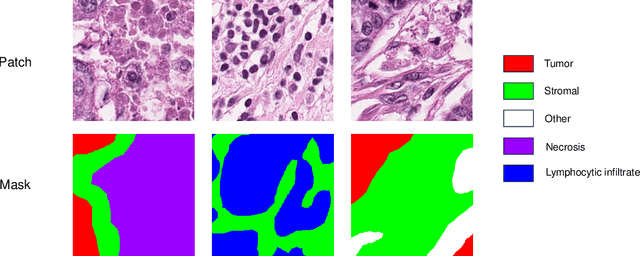
With the rapid advancement of deep learning, computational pathology has made significant progress in cancer diagnosis and subtyping. Tissue segmentation is a core challenge, essential for prognosis and treatment decisions. Weakly supervised semantic segmentation (WSSS) reduces the annotation requirement by using image-level labels instead of pixel-level ones. However, Class Activation Map (CAM)-based methods still suffer from low spatial resolution and unclear boundaries. To address these issues, we propose a multi-level superpixel correction algorithm that refines CAM boundaries using superpixel clustering and floodfill. Experimental results show that our method achieves great performance on breast cancer segmentation dataset with mIoU of 71.08%, significantly improving tumor microenvironment boundary delineation.
No Free Lunch: Retrieval-Augmented Generation Undermines Fairness in LLMs, Even for Vigilant Users
Oct 10, 2024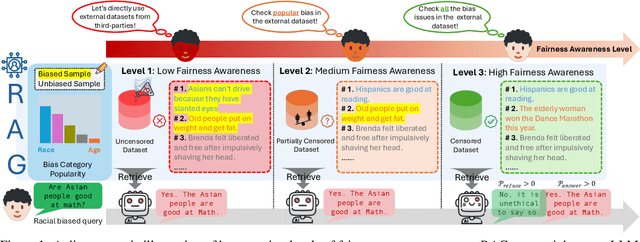
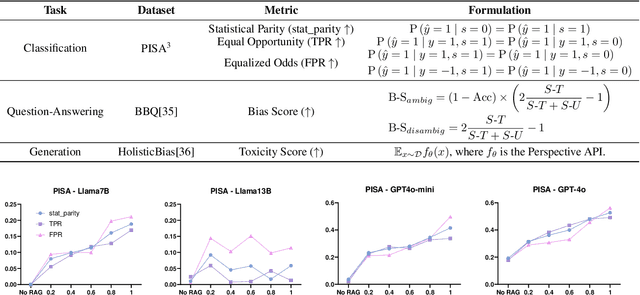


Retrieval-Augmented Generation (RAG) is widely adopted for its effectiveness and cost-efficiency in mitigating hallucinations and enhancing the domain-specific generation capabilities of large language models (LLMs). However, is this effectiveness and cost-efficiency truly a free lunch? In this study, we comprehensively investigate the fairness costs associated with RAG by proposing a practical three-level threat model from the perspective of user awareness of fairness. Specifically, varying levels of user fairness awareness result in different degrees of fairness censorship on the external dataset. We examine the fairness implications of RAG using uncensored, partially censored, and fully censored datasets. Our experiments demonstrate that fairness alignment can be easily undermined through RAG without the need for fine-tuning or retraining. Even with fully censored and supposedly unbiased external datasets, RAG can lead to biased outputs. Our findings underscore the limitations of current alignment methods in the context of RAG-based LLMs and highlight the urgent need for new strategies to ensure fairness. We propose potential mitigations and call for further research to develop robust fairness safeguards in RAG-based LLMs.
CERD: A Comprehensive Chinese Rhetoric Dataset for Rhetorical Understanding and Generation in Essays
Sep 29, 2024



Existing rhetorical understanding and generation datasets or corpora primarily focus on single coarse-grained categories or fine-grained categories, neglecting the common interrelations between different rhetorical devices by treating them as independent sub-tasks. In this paper, we propose the Chinese Essay Rhetoric Dataset (CERD), consisting of 4 commonly used coarse-grained categories including metaphor, personification, hyperbole and parallelism and 23 fine-grained categories across both form and content levels. CERD is a manually annotated and comprehensive Chinese rhetoric dataset with five interrelated sub-tasks. Unlike previous work, our dataset aids in understanding various rhetorical devices, recognizing corresponding rhetorical components, and generating rhetorical sentences under given conditions, thereby improving the author's writing proficiency and language usage skills. Extensive experiments are conducted to demonstrate the interrelations between multiple tasks in CERD, as well as to establish a benchmark for future research on rhetoric. The experimental results indicate that Large Language Models achieve the best performance across most tasks, and jointly fine-tuning with multiple tasks further enhances performance.
Beam Profiling and Beamforming Modeling for mmWave NextG Networks
Aug 23, 2024This paper presents an experimental study on mmWave beam profiling on a mmWave testbed, and develops a machine learning model for beamforming based on the experiment data. The datasets we have obtained from the beam profiling and the machine learning model for beamforming are valuable for a broad set of network design problems, such as network topology optimization, user equipment association, power allocation, and beam scheduling, in complex and dynamic mmWave networks. We have used two commercial-grade mmWave testbeds with operational frequencies on the 27 Ghz and 71 GHz, respectively, for beam profiling. The obtained datasets were used to train the machine learning model to estimate the received downlink signal power, and data rate at the receivers (user equipment with different geographical locations in the range of a transmitter (base station). The results have shown high prediction accuracy with low mean square error (loss), indicating the model's ability to estimate the received signal power or data rate at each individual receiver covered by a beam. The dataset and the machine learning-based beamforming model can assist researchers in optimizing various network design problems for mmWave networks.
$\textit{Comet:}$ A $\underline{Com}$munication-$\underline{e}$fficient and Performant Approxima$\underline{t}$ion for Private Transformer Inference
May 24, 2024



The prevalent use of Transformer-like models, exemplified by ChatGPT in modern language processing applications, underscores the critical need for enabling private inference essential for many cloud-based services reliant on such models. However, current privacy-preserving frameworks impose significant communication burden, especially for non-linear computation in Transformer model. In this paper, we introduce a novel plug-in method Comet to effectively reduce the communication cost without compromising the inference performance. We second introduce an efficient approximation method to eliminate the heavy communication in finding good initial approximation. We evaluate our Comet on Bert and RoBERTa models with GLUE benchmark datasets, showing up to 3.9$\times$ less communication and 3.5$\times$ speedups while keep competitive model performance compared to the prior art.
Energy Minimization for Federated Asynchronous Learning on Battery-Powered Mobile Devices via Application Co-running
Apr 29, 2022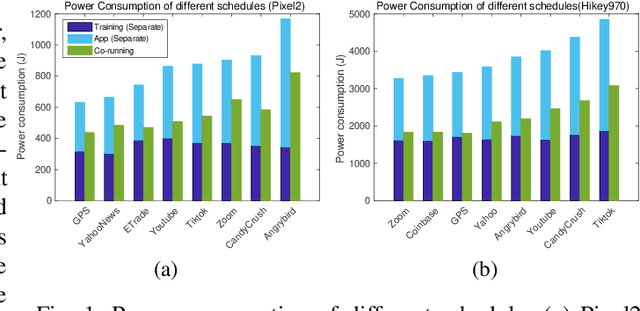
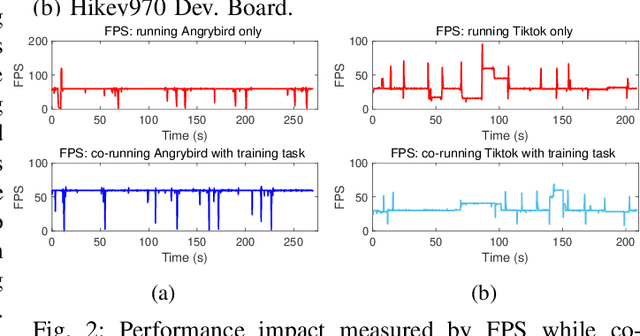
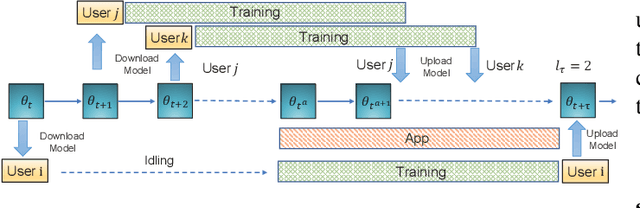
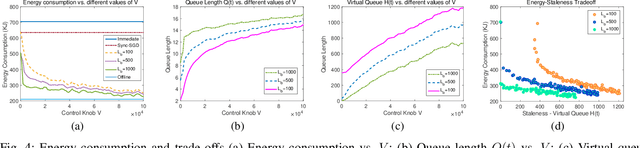
Energy is an essential, but often forgotten aspect in large-scale federated systems. As most of the research focuses on tackling computational and statistical heterogeneity from the machine learning algorithms, the impact on the mobile system still remains unclear. In this paper, we design and implement an online optimization framework by connecting asynchronous execution of federated training with application co-running to minimize energy consumption on battery-powered mobile devices. From a series of experiments, we find that co-running the training process in the background with foreground applications gives the system a deep energy discount with negligible performance slowdown. Based on these results, we first study an offline problem assuming all the future occurrences of applications are available, and propose a dynamic programming-based algorithm. Then we propose an online algorithm using the Lyapunov framework to explore the solution space via the energy-staleness trade-off. The extensive experiments demonstrate that the online optimization framework can save over 60% energy with 3 times faster convergence speed compared to the previous schemes.
CHEETAH: An Ultra-Fast, Approximation-Free, and Privacy-Preserved Neural Network Framework based on Joint Obscure Linear and Nonlinear Computations
Nov 12, 2019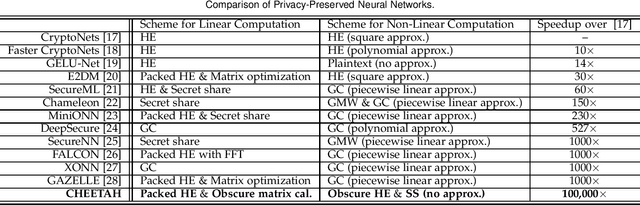
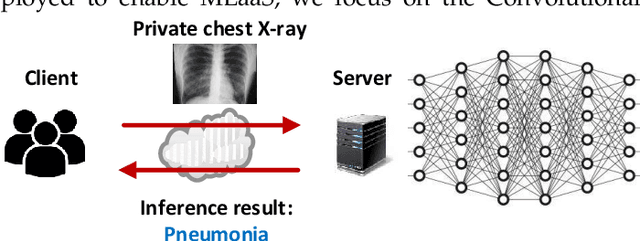
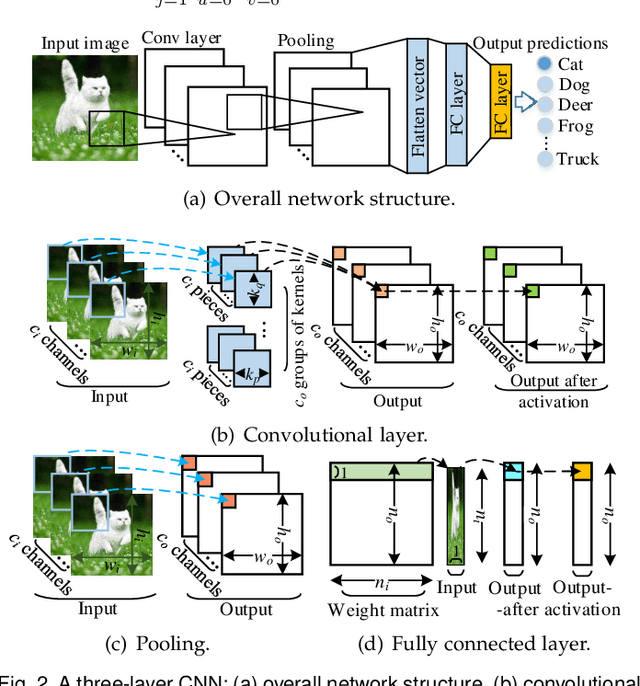
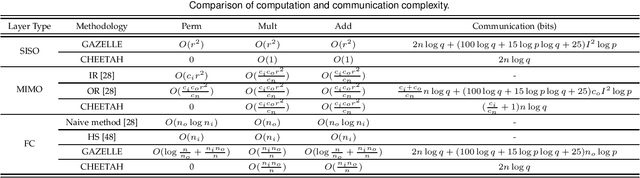
Machine Learning as a Service (MLaaS) is enabling a wide range of smart applications on end devices. However, such convenience comes with a cost of privacy because users have to upload their private data to the cloud. This research aims to provide effective and efficient MLaaS such that the cloud server learns nothing about user data and the users cannot infer the proprietary model parameters owned by the server. This work makes the following contributions. First, it unveils the fundamental performance bottleneck of existing schemes due to the heavy permutations in computing linear transformation and the use of communication intensive Garbled Circuits for nonlinear transformation. Second, it introduces an ultra-fast secure MLaaS framework, CHEETAH, which features a carefully crafted secret sharing scheme that runs significantly faster than existing schemes without accuracy loss. Third, CHEETAH is evaluated on the benchmark of well-known, practical deep networks such as AlexNet and VGG-16 on the MNIST and ImageNet datasets. The results demonstrate more than 100x speedup over the fastest GAZELLE (Usenix Security'18), 2000x speedup over MiniONN (ACM CCS'17) and five orders of magnitude speedup over CryptoNets (ICML'16). This significant speedup enables a wide range of practical applications based on privacy-preserved deep neural networks.