 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Risk to Resilience: Towards Assessing and Mitigating the Risk of Data Reconstruction Attacks in Federated Learning
Dec 17, 2025Data Reconstruction Attacks (DRA) pose a significant threat to Federated Learning (FL) systems by enabling adversaries to infer sensitive training data from local clients. Despite extensive research, the question of how to characterize and assess the risk of DRAs in FL systems remains unresolved due to the lack of a theoretically-grounded risk quantification framework. In this work, we address this gap by introducing Invertibility Loss (InvLoss) to quantify the maximum achievable effectiveness of DRAs for a given data instance and FL model. We derive a tight and computable upper bound for InvLoss and explore its implications from three perspectives. First, we show that DRA risk is governed by the spectral properties of the Jacobian matrix of exchanged model updates or feature embeddings, providing a unified explanation for the effectiveness of defense methods. Second, we develop InvRE, an InvLoss-based DRA risk estimator that offers attack method-agnostic, comprehensive risk evaluation across data instances and model architectures. Third, we propose two adaptive noise perturbation defenses that enhance FL privacy without harming classification accuracy. Extensive experiments on real-world datasets validate our framework, demonstrating its potential for systematic DRA risk evaluation and mitigation in FL systems.
X-VFL: A New Vertical Federated Learning Framework with Cross Completion and Decision Subspace Alignment
Aug 07, 2025



Vertical Federated Learning (VFL) enables collaborative learning by integrating disjoint feature subsets from multiple clients/parties. However, VFL typically faces two key challenges: i) the requirement for perfectly aligned data samples across all clients (missing features are not allowed); ii) the requirement for joint collaborative inference/prediction involving all clients (it does not support locally independent inference on a single client). To address these challenges, we propose X-VFL, a new VFL framework designed to deal with the non-aligned data samples with (partially) missing features and to support locally independent inference of new data samples for each client. In particular, we design two novel modules in X-VFL: Cross Completion (XCom) and Decision Subspace Alignment (DS-Align). XCom can complete/reconstruct missing features for non-aligned data samples by leveraging information from other clients. DS-Align aligns local features with completed and global features across all clients within the decision subspace, thus enabling locally independent inference at each client. Moreover, we provide convergence theorems for different algorithms used in training X-VFL, showing an $O(1/\sqrt{T})$ convergence rate for SGD-type algorithms and an $O(1/T)$ rate for PAGE-type algorithms, where $T$ denotes the number of training update steps. Extensive experiments on real-world datasets demonstrate that X-VFL significantly outperforms existing methods, e.g., achieving a 15% improvement in accuracy on the image CIFAR-10 dataset and a 43% improvement on the medical MIMIC-III dataset. These results validate the practical effectiveness and superiority of X-VFL, particularly in scenarios involving partially missing features and locally independent inference.
AdaFlow: Opportunistic Inference on Asynchronous Mobile Data with Generalized Affinity Control
Oct 31, 2024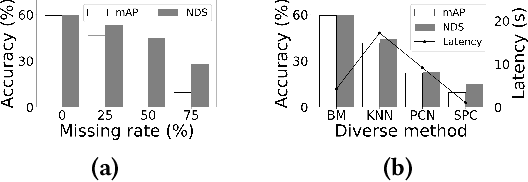


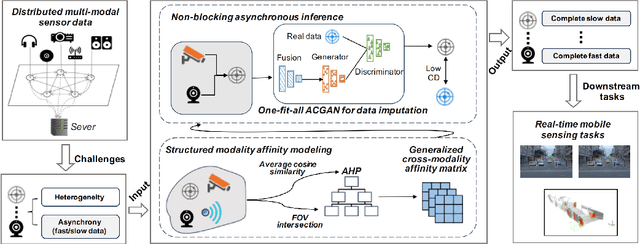
The rise of mobile devices equipped with numerous sensors, such as LiDAR and cameras, has spurred the adoption of multi-modal deep intelligence for distributed sensing tasks, such as smart cabins and driving assistance. However, the arrival times of mobile sensory data vary due to modality size and network dynamics, which can lead to delays (if waiting for slower data) or accuracy decline (if inference proceeds without waiting). Moreover, the diversity and dynamic nature of mobile systems exacerbate this challenge. In response, we present a shift to \textit{opportunistic} inference for asynchronous distributed multi-modal data, enabling inference as soon as partial data arrives. While existing methods focus on optimizing modality consistency and complementarity, known as modal affinity, they lack a \textit{computational} approach to control this affinity in open-world mobile environments. AdaFlow pioneers the formulation of structured cross-modality affinity in mobile contexts using a hierarchical analysis-based normalized matrix. This approach accommodates the diversity and dynamics of modalities, generalizing across different types and numbers of inputs. Employing an affinity attention-based conditional GAN (ACGAN), AdaFlow facilitates flexible data imputation, adapting to various modalities and downstream tasks without retraining. Experiments show that AdaFlow significantly reduces inference latency by up to 79.9\% and enhances accuracy by up to 61.9\%, outperforming status quo approaches.
$\textit{Comet:}$ A $\underline{Com}$munication-$\underline{e}$fficient and Performant Approxima$\underline{t}$ion for Private Transformer Inference
May 24, 2024The prevalent use of Transformer-like models, exemplified by ChatGPT in modern language processing applications, underscores the critical need for enabling private inference essential for many cloud-based services reliant on such models. However, current privacy-preserving frameworks impose significant communication burden, especially for non-linear computation in Transformer model. In this paper, we introduce a novel plug-in method Comet to effectively reduce the communication cost without compromising the inference performance. We second introduce an efficient approximation method to eliminate the heavy communication in finding good initial approximation. We evaluate our Comet on Bert and RoBERTa models with GLUE benchmark datasets, showing up to 3.9$\times$ less communication and 3.5$\times$ speedups while keep competitive model performance compared to the prior art.
Conditional Image Generation with One-Vs-All Classifier
Sep 18, 2020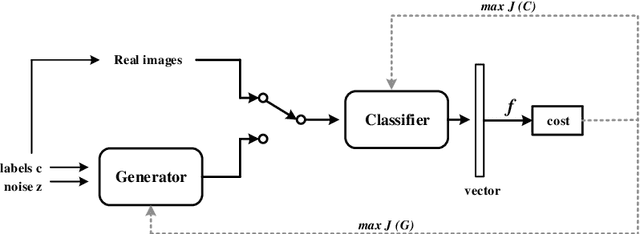
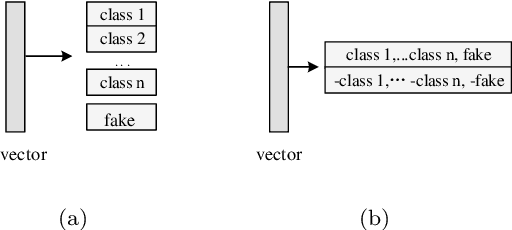


This paper explores conditional image generation with a One-Vs-All classifier based on the Generative Adversarial Networks (GANs). Instead of the real/fake discriminator used in vanilla GANs, we propose to extend the discriminator to a One-Vs-All classifier (GAN-OVA) that can distinguish each input data to its category label. Specifically, we feed certain additional information as conditions to the generator and take the discriminator as a One-Vs-All classifier to identify each conditional category. Our model can be applied to different divergence or distances used to define the objective function, such as Jensen-Shannon divergence and Earth-Mover (or called Wasserstein-1) distance. We evaluate GAN-OVAs on MNIST and CelebA-HQ datasets, and the experimental results show that GAN-OVAs make progress toward stable training over regular conditional GANs. Furthermore, GAN-OVAs effectively accelerate the generation process of different classes and improves generation quality.