 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
On the Expressive Power of Subgraph Graph Neural Networks for Graphs with Bounded Cycles
Feb 06, 2025



Graph neural networks (GNNs) have been widely used in graph-related contexts. It is known that the separation power of GNNs is equivalent to that of the Weisfeiler-Lehman (WL) test; hence, GNNs are imperfect at identifying all non-isomorphic graphs, which severely limits their expressive power. This work investigates $k$-hop subgraph GNNs that aggregate information from neighbors with distances up to $k$ and incorporate the subgraph structure. We prove that under appropriate assumptions, the $k$-hop subgraph GNNs can approximate any permutation-invariant/equivariant continuous function over graphs without cycles of length greater than $2k+1$ within any error tolerance. We also provide an extension to $k$-hop GNNs without incorporating the subgraph structure. Our numerical experiments on established benchmarks and novel architectures validate our theory on the relationship between the information aggregation distance and the cycle size.
$\textit{Comet:}$ A $\underline{Com}$munication-$\underline{e}$fficient and Performant Approxima$\underline{t}$ion for Private Transformer Inference
May 24, 2024The prevalent use of Transformer-like models, exemplified by ChatGPT in modern language processing applications, underscores the critical need for enabling private inference essential for many cloud-based services reliant on such models. However, current privacy-preserving frameworks impose significant communication burden, especially for non-linear computation in Transformer model. In this paper, we introduce a novel plug-in method Comet to effectively reduce the communication cost without compromising the inference performance. We second introduce an efficient approximation method to eliminate the heavy communication in finding good initial approximation. We evaluate our Comet on Bert and RoBERTa models with GLUE benchmark datasets, showing up to 3.9$\times$ less communication and 3.5$\times$ speedups while keep competitive model performance compared to the prior art.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Interpretable Models for Detecting and Monitoring Elevated Intracranial Pressure
Mar 04, 2024


Detecting elevated intracranial pressure (ICP) is crucial in diagnosing and managing various neurological conditions. These fluctuations in pressure are transmitted to the optic nerve sheath (ONS), resulting in changes to its diameter, which can then be detected using ultrasound imaging devices. However, interpreting sonographic images of the ONS can be challenging. In this work, we propose two systems that actively monitor the ONS diameter throughout an ultrasound video and make a final prediction as to whether ICP is elevated. To construct our systems, we leverage subject matter expert (SME) guidance, structuring our processing pipeline according to their collection procedure, while also prioritizing interpretability and computational efficiency. We conduct a number of experiments, demonstrating that our proposed systems are able to outperform various baselines. One of our SMEs then manually validates our top system's performance, lending further credibility to our approach while demonstrating its potential utility in a clinical setting.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
MobilePTX: Sparse Coding for Pneumothorax Detection Given Limited Training Examples
Dec 08, 2022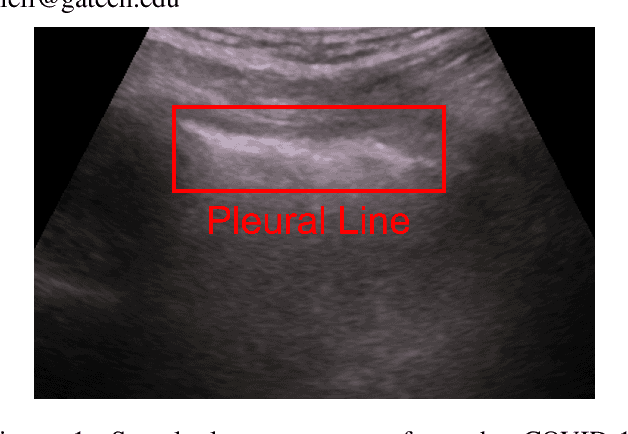
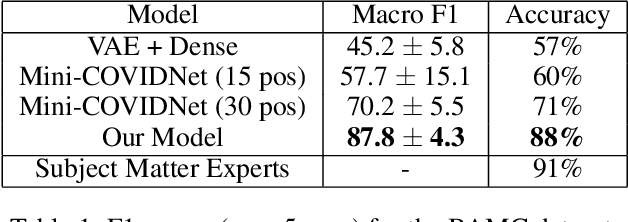
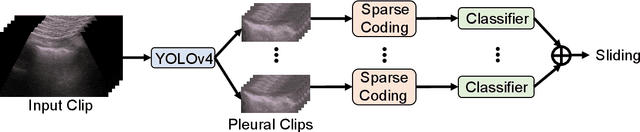

Point-of-Care Ultrasound (POCUS) refers to clinician-performed and interpreted ultrasonography at the patient's bedside. Interpreting these images requires a high level of expertise, which may not be available during emergencies. In this paper, we support POCUS by developing classifiers that can aid medical professionals by diagnosing whether or not a patient has pneumothorax. We decomposed the task into multiple steps, using YOLOv4 to extract relevant regions of the video and a 3D sparse coding model to represent video features. Given the difficulty in acquiring positive training videos, we trained a small-data classifier with a maximum of 15 positive and 32 negative examples. To counteract this limitation, we leveraged subject matter expert (SME) knowledge to limit the hypothesis space, thus reducing the cost of data collection. We present results using two lung ultrasound datasets and demonstrate that our model is capable of achieving performance on par with SMEs in pneumothorax identification. We then developed an iOS application that runs our full system in less than 4 seconds on an iPad Pro, and less than 8 seconds on an iPhone 13 Pro, labeling key regions in the lung sonogram to provide interpretable diagnoses.
Do it Like the Doctor: How We Can Design a Model That Uses Domain Knowledge to Diagnose Pneumothorax
May 24, 2022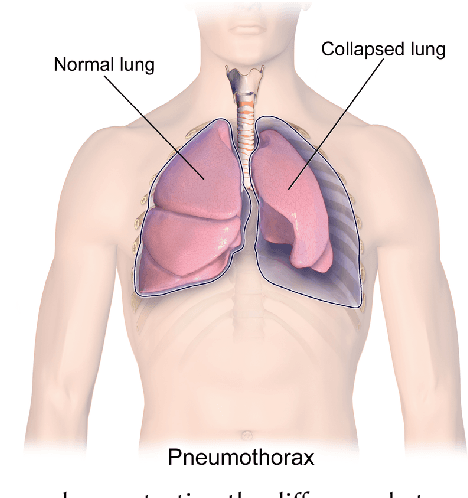
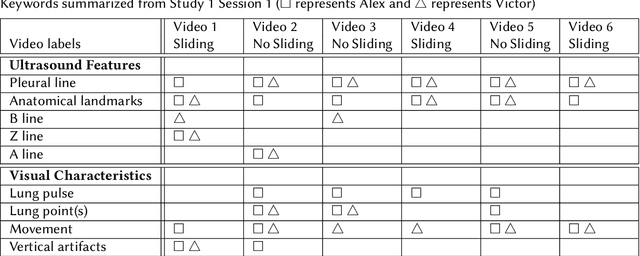
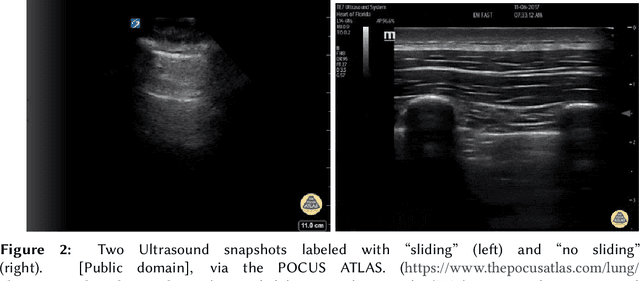
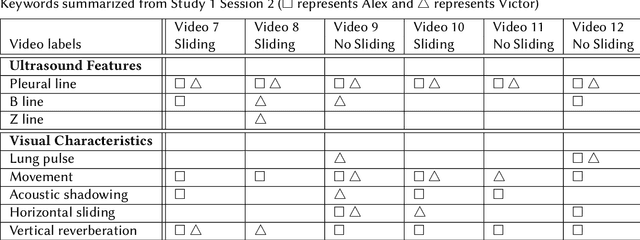
Computer-aided diagnosis for medical imaging is a well-studied field that aims to provide real-time decision support systems for physicians. These systems attempt to detect and diagnose a plethora of medical conditions across a variety of image diagnostic technologies including ultrasound, x-ray, MRI, and CT. When designing AI models for these systems, we are often limited by little training data, and for rare medical conditions, positive examples are difficult to obtain. These issues often cause models to perform poorly, so we needed a way to design an AI model in light of these limitations. Thus, our approach was to incorporate expert domain knowledge into the design of an AI model. We conducted two qualitative think-aloud studies with doctors trained in the interpretation of lung ultrasound diagnosis to extract relevant domain knowledge for the condition Pneumothorax. We extracted knowledge of key features and procedures used to make a diagnosis. With this knowledge, we employed knowledge engineering concepts to make recommendations for an AI model design to automatically diagnose Pneumothorax.