 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPP: A Certified Poisoned-Sample Detection Framework for Backdoor Attacks under Dataset Imbalance
Jan 30, 2026Deep neural networks are highly susceptible to backdoor attacks, yet most defense methods to date rely on balanced data, overlooking the pervasive class imbalance in real-world scenarios that can amplify backdoor threats. This paper presents the first in-depth investigation of how the dataset imbalance amplifies backdoor vulnerability, showing that (i) the imbalance induces a majority-class bias that increases susceptibility and (ii) conventional defenses degrade significantly as the imbalance grows. To address this, we propose Randomized Probability Perturbation (RPP), a certified poisoned-sample detection framework that operates in a black-box setting using only model output probabilities. For any inspected sample, RPP determines whether the input has been backdoor-manipulated, while offering provable within-domain detectability guarantees and a probabilistic upper bound on the false positive rate. Extensive experiments on five benchmarks (MNIST, SVHN, CIFAR-10, TinyImageNet and ImageNet10) covering 10 backdoor attacks and 12 baseline defenses show that RPP achieves significantly higher detection accuracy than state-of-the-art defenses, particularly under dataset imbalance. RPP establishes a theoretical and practical foundation for defending against backdoor attacks in real-world environments with imbalanced data.
Deep Incomplete Multi-View Clustering via Hierarchical Imputation and Alignment
Jan 14, 2026Incomplete multi-view clustering (IMVC) aims to discover shared cluster structures from multi-view data with partial observations. The core challenges lie in accurately imputing missing views without introducing bias, while maintaining semantic consistency across views and compactness within clusters. To address these challenges, we propose DIMVC-HIA, a novel deep IMVC framework that integrates hierarchical imputation and alignment with four key components: (1) view-specific autoencoders for latent feature extraction, coupled with a view-shared clustering predictor to produce soft cluster assignments; (2) a hierarchical imputation module that first estimates missing cluster assignments based on cross-view contrastive similarity, and then reconstructs missing features using intra-view, intra-cluster statistics; (3) an energy-based semantic alignment module, which promotes intra-cluster compactness by minimizing energy variance around low-energy cluster anchors; and (4) a contrastive assignment alignment module, which enhances cross-view consistency and encourages confident, well-separated cluster predictions. Experiments on benchmarks demonstrate that our framework achieves superior performance under varying levels of missingness.
PRIVEE: Privacy-Preserving Vertical Federated Learning Against Feature Inference Attacks
Dec 14, 2025Vertical Federated Learning (VFL) enables collaborative model training across organizations that share common user samples but hold disjoint feature spaces. Despite its potential, VFL is susceptible to feature inference attacks, in which adversarial parties exploit shared confidence scores (i.e., prediction probabilities) during inference to reconstruct private input features of other participants. To counter this threat, we propose PRIVEE (PRIvacy-preserving Vertical fEderated lEarning), a novel defense mechanism named after the French word privée, meaning "private." PRIVEE obfuscates confidence scores while preserving critical properties such as relative ranking and inter-score distances. Rather than exposing raw scores, PRIVEE shares only the transformed representations, mitigating the risk of reconstruction attacks without degrading model prediction accuracy. Extensive experiments show that PRIVEE achieves a threefold improvement in privacy protection compared to state-of-the-art defenses, while preserving full predictive performance against advanced feature inference attacks.
FlashForge: Ultra-Efficient Prefix-Aware Attention for LLM Decoding
May 23, 2025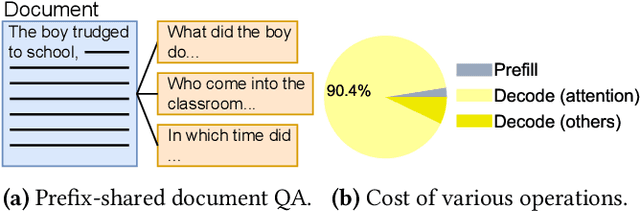
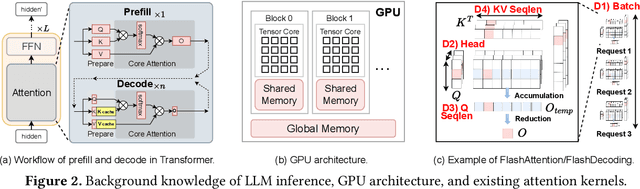
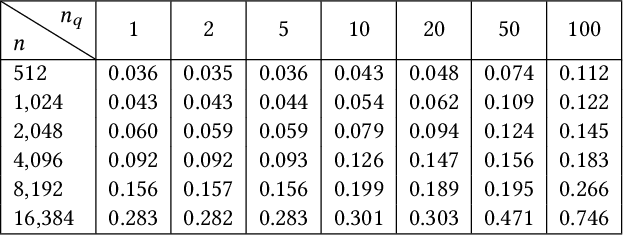
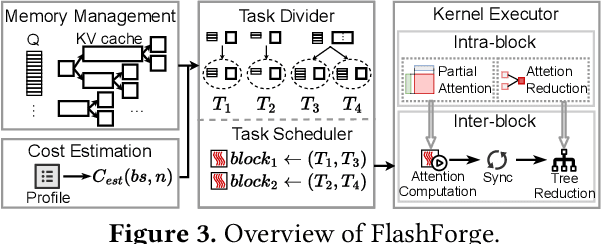
Prefix-sharing among multiple prompts presents opportunities to combine the operations of the shared prefix, while attention computation in the decode stage, which becomes a critical bottleneck with increasing context lengths, is a memory-intensive process requiring heavy memory access on the key-value (KV) cache of the prefixes. Therefore, in this paper, we explore the potential of prefix-sharing in the attention computation of the decode stage. However, the tree structure of the prefix-sharing mechanism presents significant challenges for attention computation in efficiently processing shared KV cache access patterns while managing complex dependencies and balancing irregular workloads. To address the above challenges, we propose a dedicated attention kernel to combine the memory access of shared prefixes in the decoding stage, namely FlashForge. FlashForge delivers two key innovations: a novel shared-prefix attention kernel that optimizes memory hierarchy and exploits both intra-block and inter-block parallelism, and a comprehensive workload balancing mechanism that efficiently estimates cost, divides tasks, and schedules execution. Experimental results show that FlashForge achieves an average 1.9x speedup and 120.9x memory access reduction compared to the state-of-the-art FlashDecoding kernel regarding attention computation in the decode stage and 3.8x end-to-end time per output token compared to the vLLM.
$\textit{Comet:}$ A $\underline{Com}$munication-$\underline{e}$fficient and Performant Approxima$\underline{t}$ion for Private Transformer Inference
May 24, 2024The prevalent use of Transformer-like models, exemplified by ChatGPT in modern language processing applications, underscores the critical need for enabling private inference essential for many cloud-based services reliant on such models. However, current privacy-preserving frameworks impose significant communication burden, especially for non-linear computation in Transformer model. In this paper, we introduce a novel plug-in method Comet to effectively reduce the communication cost without compromising the inference performance. We second introduce an efficient approximation method to eliminate the heavy communication in finding good initial approximation. We evaluate our Comet on Bert and RoBERTa models with GLUE benchmark datasets, showing up to 3.9$\times$ less communication and 3.5$\times$ speedups while keep competitive model performance compared to the prior art.