 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclic-Prefix OFDM Probing for Spatial-ISI-Free Distributed Acoustic Sensing via Frequency-Domain Channel Reconstruction
Jun 18, 2026Matched-filter-based pulse-compression distributed acoustic sensing (DAS) suffers from nonzero compression sidelobes that cause deterministic inter-range-bin leakage, i.e., spatial inter-symbol interference (ISI), and false responses in reconstructed Rayleigh-backscatter traces. We propose a cyclic-prefix orthogonal frequency-division multiplexing (CP-OFDM) DAS system for $φ$-OTDR, using a data-bearing CP-OFDM waveform as the sensing probe. It also recovers forward communication data, providing an initial demonstration of shared-waveform integrated sensing and communication (ISAC). To our knowledge, this is the first formulation of distributed Rayleigh backscattering as a finite-memory sensing multipath channel. Based on this formulation, we prove that, if the useful OFDM and CP lengths cover the sensing multipath memory, CP removal, one-tap frequency-domain equalization, and inverse discrete Fourier transform reconstruct each range-bin coefficient without deterministic waveform-induced spatial ISI, enabling spatial-ISI-free phase demodulation. For a simulated 5.2-km link with ten simultaneous strong and weak events spaced by 5.31--5.83 m within groups, the proposed receiver suppresses off-event leakage and improves phase-trace mean-square error by up to 29.55 dB over matched-filter pulse compression. In a heterodyne coherent experiment over a 5.2-km fiber link with 111.984-MHz occupied bandwidth, 500-Hz PZT vibrations are blindly localized at 5.071 and 5.066 km under 5- and 1-V drives, respectively, and their waveforms are recovered with correlation coefficients of 0.990 and 0.962. The same data-bearing probe also recovers an image with zero measured bit-error rate and a median error vector magnitude of -23.14 dB. These results validate CP-OFDM-aided frequency-domain channel reconstruction for spatial-ISI-free DAS and demonstrate its potential for shared-waveform optical-fiber ISAC.
Almost-Orthogonality in Lp Spaces: A Case Study with Grok
May 06, 2026Carbery proposed the following sharpened form of triangle inequality for many functions: for any $p\ge 2$ and any finite sequence $(f_j)_j\subset L^p$ we have \[ \Big\|\sum_j f_j\Big\|_p \ \le\ \left(\sup_{j} \sum_{k} α_{jk}^{\,c}\right)^{1/p'} \Big(\sum_j \|f_j\|_p^p\Big)^{1/p}, \] where $c=2$, $1/p+1/p'=1$, and $α_{jk}=\sqrt{\frac{\|f_{j}f_{k}\|_{p/2}}{\|f_{j}\|_{p}\|f_{k}\|_{p}}}$. In the first part of this paper we construct a counterexample showing that this inequality fails for every $p>2$. We then prove that if an estimate of the above form holds, the exponent must satisfy $c\le p'$. Finally, at the critical exponent $c=p'$, we establish the inequality for all integer values $p\ge 2$. In the second part of the paper we obtain a sharp three-function bound \[ \Big\|\sum_{j=1}^{3} f_j\Big\|_p \ \le\ \left(1+2Γ^{c(p)}\right)^{1/p'} \Big(\sum_{j=1}^{3} \|f_j\|_p^p\Big)^{1/p}, \] where $p \geq 3$, $c(p) = \frac{2\ln(2)}{(p-2)\ln(3)+2\ln(2)}$ and $Γ=Γ(f_1,f_2,f_3)\in[0,1]$ quantifies the degree of orthogonality among $f_1,f_2,f_3$. The exponent $c(p)$ is optimal, and improves upon the power $r(p) = \frac{6}{5p-4}$ obtained previously by Carlen, Frank, and Lieb. Some intermediate lemmas and inequalities appearing in this work were explored with the assistance of the large language model Grok.
Regularity of Second-Order Elliptic PDEs in Spectral Barron Spaces
Feb 22, 2026We establish a regularity theorem for second-order elliptic PDEs on $\mathbb{R}^{d}$ in spectral Barron spaces. Under mild ellipticity and smallness assumptions, the solution gains two additional orders of Barron regularity. As a corollary, we identify a class of PDEs whose solutions can be approximated by two-layer neural networks with cosine activation functions, where the width of the neural network is independent of the spatial dimension.
Exact Instance Compression for Convex Empirical Risk Minimization via Color Refinement
Jan 31, 2026Empirical risk minimization (ERM) can be computationally expensive, with standard solvers scaling poorly even in the convex setting. We propose a novel lossless compression framework for convex ERM based on color refinement, extending prior work from linear programs and convex quadratic programs to a broad class of differentiable convex optimization problems. We develop concrete algorithms for a range of models, including linear and polynomial regression, binary and multiclass logistic regression, regression with elastic-net regularization, and kernel methods such as kernel ridge regression and kernel logistic regression. Numerical experiments on representative datasets demonstrate the effectiveness of the proposed approach.
LogPurge: Log Data Purification for Anomaly Detection via Rule-Enhanced Filtering
Nov 18, 2025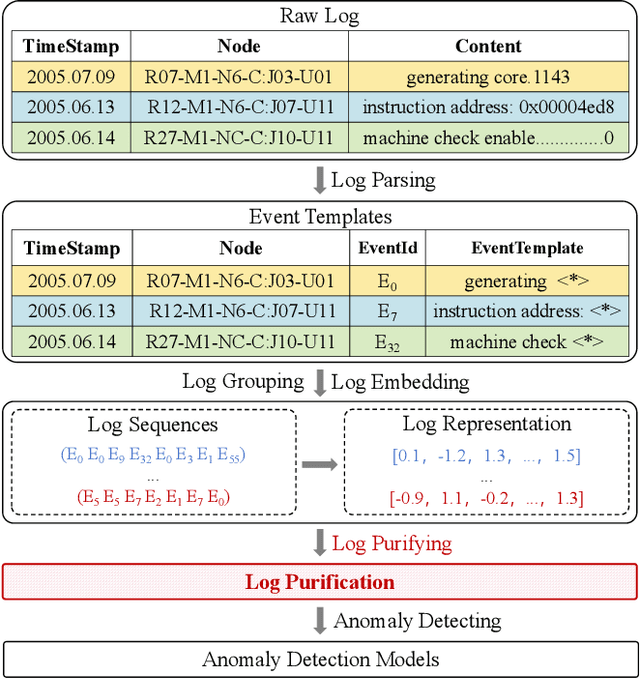
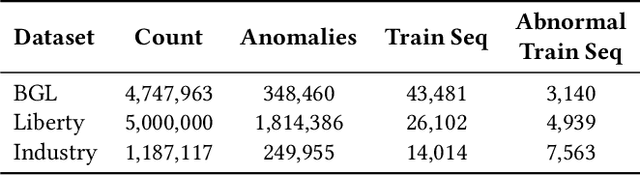
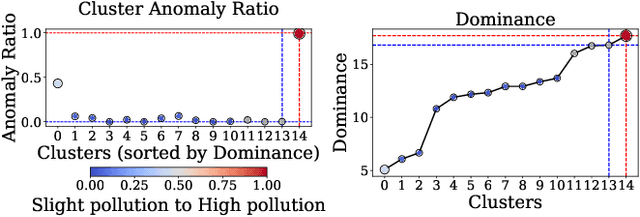
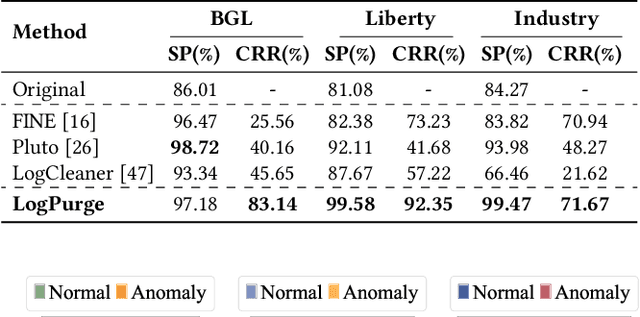
Log anomaly detection, which is critical for identifying system failures and preempting security breaches, detects irregular patterns within large volumes of log data, and impacts domains such as service reliability, performance optimization, and database log analysis. Modern log anomaly detection methods rely on training deep learning models on clean, anomaly-free log sequences. However, obtaining such clean log data requires costly and tedious human labeling, and existing automatic cleaning methods fail to fully integrate the specific characteristics and actual semantics of logs in their purification process. In this paper, we propose a cost-aware, rule-enhanced purification framework, LogPurge, that automatically selects a sufficient subset of normal log sequences from contamination log sequences to train a anomaly detection model. Our approach involves a two-stage filtering algorithm: In the first stage, we use a large language model (LLM) to remove clustered anomalous patterns and enhance system rules to improve LLM's understanding of system logs; in the second stage, we utilize a divide-and-conquer strategy that decomposes the remaining contaminated regions into smaller subproblems, allowing each to be effectively purified through the first stage procedure. Our experiments, conducted on two public datasets and one industrial dataset, show that our method significantly removes an average of 98.74% of anomalies while retaining 82.39% of normal samples. Compared to the latest unsupervised log sample selection algorithms, our method achieves F-1 score improvements of 35.7% and 84.11% on the public datasets, and an impressive 149.72% F-1 improvement on the private dataset, demonstrating the effectiveness of our approach.
A method for improving multilingual quality and diversity of instruction fine-tuning datasets
Sep 19, 2025Multilingual Instruction Fine-Tuning (IFT) is essential for enabling large language models (LLMs) to generalize effectively across diverse linguistic and cultural contexts. However, the scarcity of high-quality multilingual training data and corresponding building method remains a critical bottleneck. While data selection has shown promise in English settings, existing methods often fail to generalize across languages due to reliance on simplistic heuristics or language-specific assumptions. In this work, we introduce Multilingual Data Quality and Diversity (M-DaQ), a novel method for improving LLMs multilinguality, by selecting high-quality and semantically diverse multilingual IFT samples. We further conduct the first systematic investigation of the Superficial Alignment Hypothesis (SAH) in multilingual setting. Empirical results across 18 languages demonstrate that models fine-tuned with M-DaQ method achieve significant performance gains over vanilla baselines over 60% win rate. Human evaluations further validate these gains, highlighting the increment of cultural points in the response. We release the M-DaQ code to support future research.
RationAnomaly: Log Anomaly Detection with Rationality via Chain-of-Thought and Reinforcement Learning
Sep 18, 2025Logs constitute a form of evidence signaling the operational status of software systems. Automated log anomaly detection is crucial for ensuring the reliability of modern software systems. However, existing approaches face significant limitations: traditional deep learning models lack interpretability and generalization, while methods leveraging Large Language Models are often hindered by unreliability and factual inaccuracies. To address these issues, we propose RationAnomaly, a novel framework that enhances log anomaly detection by synergizing Chain-of-Thought (CoT) fine-tuning with reinforcement learning. Our approach first instills expert-like reasoning patterns using CoT-guided supervised fine-tuning, grounded in a high-quality dataset corrected through a rigorous expert-driven process. Subsequently, a reinforcement learning phase with a multi-faceted reward function optimizes for accuracy and logical consistency, effectively mitigating hallucinations. Experimentally, RationAnomaly outperforms state-of-the-art baselines, achieving superior F1-scores on key benchmarks while providing transparent, step-by-step analytical outputs. We have released the corresponding resources, including code and datasets.
Barron Space Representations for Elliptic PDEs with Homogeneous Boundary Conditions
Aug 11, 2025We study the approximation complexity of high-dimensional second-order elliptic PDEs with homogeneous boundary conditions on the unit hypercube, within the framework of Barron spaces. Under the assumption that the coefficients belong to suitably defined Barron spaces, we prove that the solution can be efficiently approximated by two-layer neural networks, circumventing the curse of dimensionality. Our results demonstrate the expressive power of shallow networks in capturing high-dimensional PDE solutions under appropriate structural assumptions.
SCFormer: Structured Channel-wise Transformer with Cumulative Historical State for Multivariate Time Series Forecasting
May 05, 2025

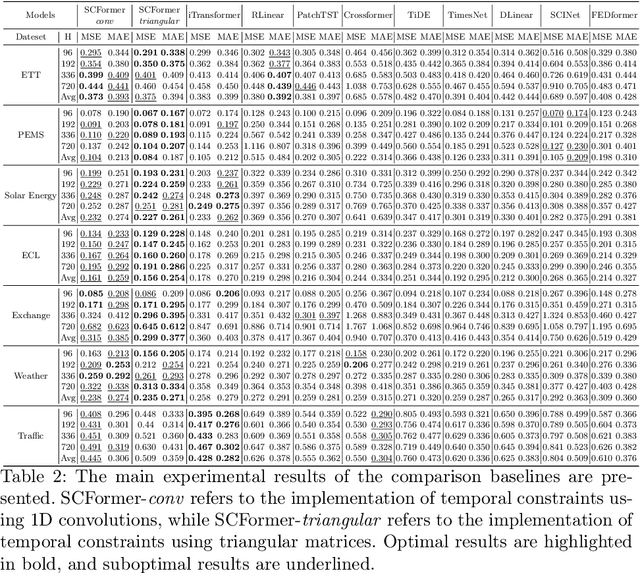
The Transformer model has shown strong performance in multivariate time series forecasting by leveraging channel-wise self-attention. However, this approach lacks temporal constraints when computing temporal features and does not utilize cumulative historical series effectively.To address these limitations, we propose the Structured Channel-wise Transformer with Cumulative Historical state (SCFormer). SCFormer introduces temporal constraints to all linear transformations, including the query, key, and value matrices, as well as the fully connected layers within the Transformer. Additionally, SCFormer employs High-order Polynomial Projection Operators (HiPPO) to deal with cumulative historical time series, allowing the model to incorporate information beyond the look-back window during prediction. Extensive experiments on multiple real-world datasets demonstrate that SCFormer significantly outperforms mainstream baselines, highlighting its effectiveness in enhancing time series forecasting. The code is publicly available at https://github.com/ShiweiGuo1995/SCFormer
ValuePilot: A Two-Phase Framework for Value-Driven Decision-Making
Mar 06, 2025



Despite recent advances in artificial intelligence (AI), it poses challenges to ensure personalized decision-making in tasks that are not considered in training datasets. To address this issue, we propose ValuePilot, a two-phase value-driven decision-making framework comprising a dataset generation toolkit DGT and a decision-making module DMM trained on the generated data. DGT is capable of generating scenarios based on value dimensions and closely mirroring real-world tasks, with automated filtering techniques and human curation to ensure the validity of the dataset. In the generated dataset, DMM learns to recognize the inherent values of scenarios, computes action feasibility and navigates the trade-offs between multiple value dimensions to make personalized decisions. Extensive experiments demonstrate that, given human value preferences, our DMM most closely aligns with human decisions, outperforming Claude-3.5-Sonnet, Gemini-2-flash, Llama-3.1-405b and GPT-4o. This research is a preliminary exploration of value-driven decision-making. We hope it will stimulate interest in value-driven decision-making and personalized decision-making within the community.