 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuriiFormer: A Suite of Nesterov-Accelerated Transformers
Jan 30, 2026We propose a variational framework that interprets transformer layers as iterations of an optimization algorithm acting on token embeddings. In this view, self-attention implements a gradient step of an interaction energy, while MLP layers correspond to gradient updates of a potential energy. Standard GPT-style transformers emerge as vanilla gradient descent on the resulting composite objective, implemented via Lie--Trotter splitting between these two energy functionals. This perspective enables principled architectural design using classical optimization ideas. As a proof of concept, we introduce a Nesterov-style accelerated transformer that preserves the same attention and MLP oracles. The resulting architecture consistently outperforms a nanoGPT baseline on TinyStories and OpenWebText, demonstrating that optimization-theoretic insights can translate into practical gains.
Splat Regression Models
Nov 18, 2025We introduce a highly expressive class of function approximators called Splat Regression Models. Model outputs are mixtures of heterogeneous and anisotropic bump functions, termed splats, each weighted by an output vector. The power of splat modeling lies in its ability to locally adjust the scale and direction of each splat, achieving both high interpretability and accuracy. Fitting splat models reduces to optimization over the space of mixing measures, which can be implemented using Wasserstein-Fisher-Rao gradient flows. As a byproduct, we recover the popular Gaussian Splatting methodology as a special case, providing a unified theoretical framework for this state-of-the-art technique that clearly disambiguates the inverse problem, the model, and the optimization algorithm. Through numerical experiments, we demonstrate that the resulting models and algorithms constitute a flexible and promising approach for solving diverse approximation, estimation, and inverse problems involving low-dimensional data.
Gaussian mixture layers for neural networks
Aug 06, 2025The mean-field theory for two-layer neural networks considers infinitely wide networks that are linearly parameterized by a probability measure over the parameter space. This nonparametric perspective has significantly advanced both the theoretical and conceptual understanding of neural networks, with substantial efforts made to validate its applicability to networks of moderate width. In this work, we explore the opposite direction, investigating whether dynamics can be directly implemented over probability measures. Specifically, we employ Gaussian mixture models as a flexible and expressive parametric family of distributions together with the theory of Wasserstein gradient flows to derive training dynamics for such measures. Our approach introduces a new type of layer -- the Gaussian mixture (GM) layer -- that can be integrated into neural network architectures. As a proof of concept, we validate our proposal through experiments on simple classification tasks, where a GM layer achieves test performance comparable to that of a two-layer fully connected network. Furthermore, we examine the behavior of these dynamics and demonstrate numerically that GM layers exhibit markedly different behavior compared to classical fully connected layers, even when the latter are large enough to be considered in the mean-field regime.
Synchronization of mean-field models on the circle
Jul 30, 2025This paper considers a mean-field model of $n$ interacting particles whose state space is the unit circle, a generalization of the classical Kuramoto model. Global synchronization is said to occur if after starting from almost any initial state, all particles coalesce to a common point on the circle. We propose a general synchronization criterion in terms of $L_1$-norm of the third derivative of the particle interaction function. As an application we resolve a conjecture for the so-called self-attention dynamics (stylized model of transformers), by showing synchronization for all $\beta \ge -0.16$, which significantly extends the previous bound of $0\le \beta \le 1$ from Criscitiello, Rebjock, McRae, and Boumal (2024). We also show that global synchronization does not occur when $\beta < -2/3$.
The power of fine-grained experts: Granularity boosts expressivity in Mixture of Experts
May 11, 2025Mixture-of-Experts (MoE) layers are increasingly central to frontier model architectures. By selectively activating parameters, they reduce computational cost while scaling total parameter count. This paper investigates the impact of the number of active experts, termed granularity, comparing architectures with many (e.g., 8 per layer in DeepSeek) to those with fewer (e.g., 1 per layer in Llama-4 models). We prove an exponential separation in network expressivity based on this design parameter, suggesting that models benefit from higher granularity. Experimental results corroborate our theoretical findings and illustrate this separation.
Quantitative Clustering in Mean-Field Transformer Models
Apr 20, 2025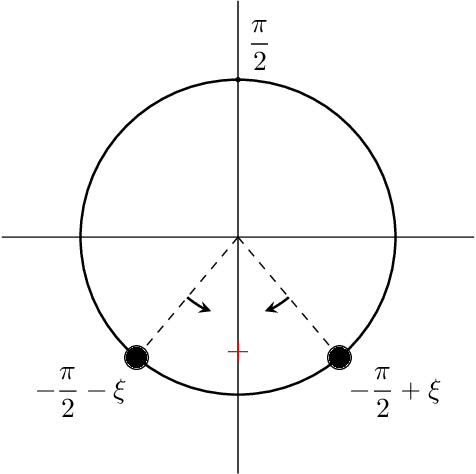
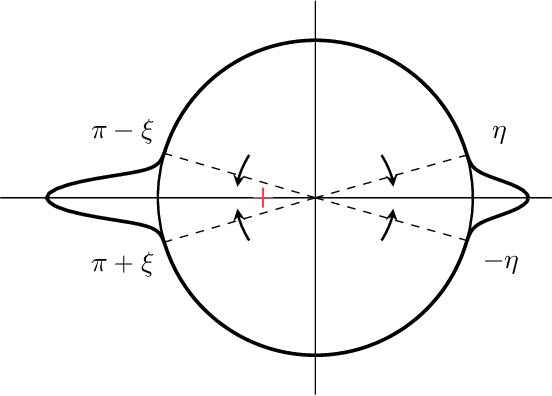
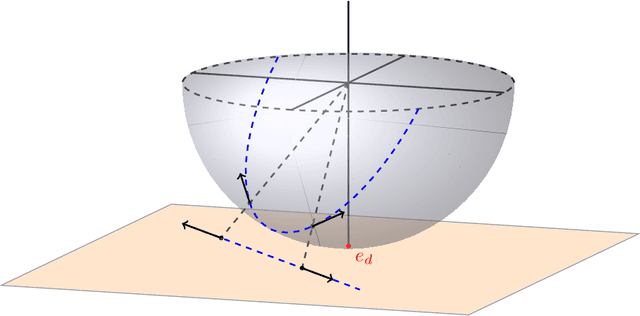
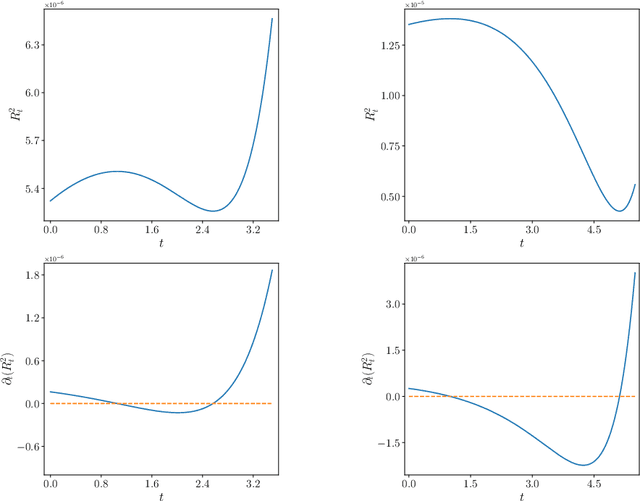
The evolution of tokens through a deep transformer models can be modeled as an interacting particle system that has been shown to exhibit an asymptotic clustering behavior akin to the synchronization phenomenon in Kuramoto models. In this work, we investigate the long-time clustering of mean-field transformer models. More precisely, we establish exponential rates of contraction to a Dirac point mass for any suitably regular initialization under some assumptions on the parameters of transformer models, any suitably regular mean-field initialization synchronizes exponentially fast with some quantitative rates.
Residual connections provably mitigate oversmoothing in graph neural networks
Jan 04, 2025



Graph neural networks (GNNs) have achieved remarkable empirical success in processing and representing graph-structured data across various domains. However, a significant challenge known as "oversmoothing" persists, where vertex features become nearly indistinguishable in deep GNNs, severely restricting their expressive power and practical utility. In this work, we analyze the asymptotic oversmoothing rates of deep GNNs with and without residual connections by deriving explicit convergence rates for a normalized vertex similarity measure. Our analytical framework is grounded in the multiplicative ergodic theorem. Furthermore, we demonstrate that adding residual connections effectively mitigates or prevents oversmoothing across several broad families of parameter distributions. The theoretical findings are strongly supported by numerical experiments.
On the number of modes of Gaussian kernel density estimators
Dec 12, 2024



We consider the Gaussian kernel density estimator with bandwidth $\beta^{-\frac12}$ of $n$ iid Gaussian samples. Using the Kac-Rice formula and an Edgeworth expansion, we prove that the expected number of modes on the real line scales as $\Theta(\sqrt{\beta\log\beta})$ as $\beta,n\to\infty$ provided $n^c\lesssim \beta\lesssim n^{2-c}$ for some constant $c>0$. An impetus behind this investigation is to determine the number of clusters to which Transformers are drawn in a metastable state.
Measure-to-measure interpolation using Transformers
Nov 07, 2024



Transformers are deep neural network architectures that underpin the recent successes of large language models. Unlike more classical architectures that can be viewed as point-to-point maps, a Transformer acts as a measure-to-measure map implemented as specific interacting particle system on the unit sphere: the input is the empirical measure of tokens in a prompt and its evolution is governed by the continuity equation. In fact, Transformers are not limited to empirical measures and can in principle process any input measure. As the nature of data processed by Transformers is expanding rapidly, it is important to investigate their expressive power as maps from an arbitrary measure to another arbitrary measure. To that end, we provide an explicit choice of parameters that allows a single Transformer to match $N$ arbitrary input measures to $N$ arbitrary target measures, under the minimal assumption that every pair of input-target measures can be matched by some transport map.
Clustering in Causal Attention Masking
Nov 07, 2024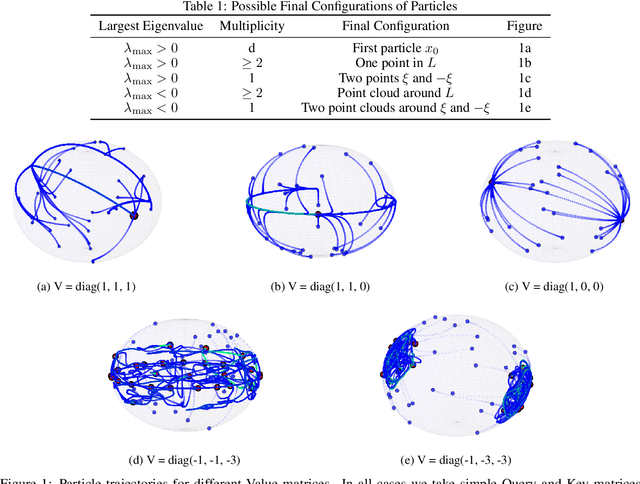
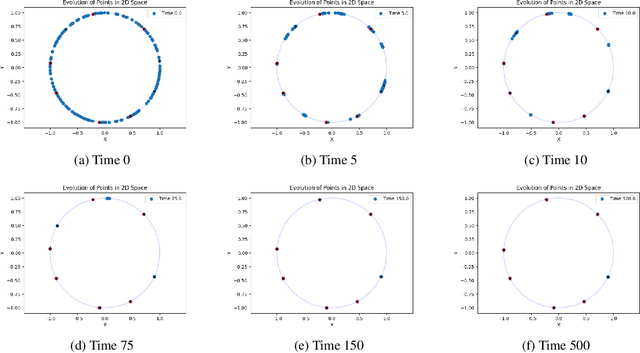
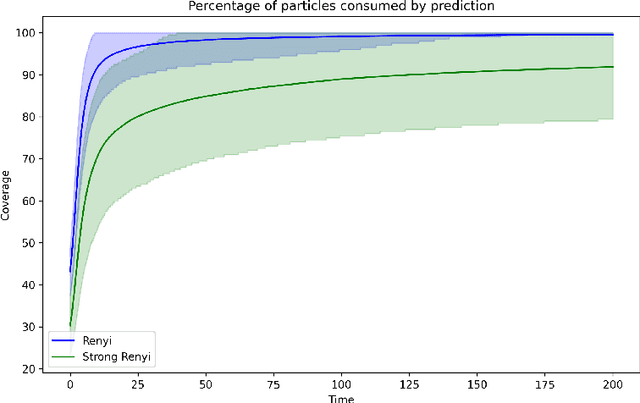
This work presents a modification of the self-attention dynamics proposed by Geshkovski et al. (arXiv:2312.10794) to better reflect the practically relevant, causally masked attention used in transformer architectures for generative AI. This modification translates into an interacting particle system that cannot be interpreted as a mean-field gradient flow. Despite this loss of structure, we significantly strengthen the results of Geshkovski et al. (arXiv:2312.10794) in this context: While previous rigorous results focused on cases where all three matrices (Key, Query, and Value) were scaled identities, we prove asymptotic convergence to a single cluster for arbitrary key-query matrices and a value matrix equal to the identity. Additionally, we establish a connection to the classical R\'enyi parking problem from combinatorial geometry to make initial theoretical steps towards demonstrating the existence of meta-stable states.