 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe (Marginal) Value of a Search Ad: An Online Causal Framework for Repeated Second-price Auctions
May 03, 2026Existing auto-bidding algorithms in digital advertising often treat the value of an ad opportunity as the revenue obtained when an ad is shown and/or clicked, and bid accordingly. This can lead to wasteful spending because the true value is the marginal gain from paid exposure: even without winning a sponsored slot, an advertiser may still earn revenue via an organic search result (e.g., on Google or Amazon). Motivated by recent work, we model ad value as a treatment effect--the outcome difference between winning and losing the auction--and study online learning for bidding in second-price (Vickrey) auctions under this causal perspective. We develop algorithms that attain rate-optimal regret under several feedback models. A key ingredient exploits the information revealed by the second-price payment rule, which strictly improves regret relative to analogous learning problems in first-price auctions.
PETS: A Principled Framework Towards Optimal Trajectory Allocation for Efficient Test-Time Self-Consistency
Feb 18, 2026Test-time scaling can improve model performance by aggregating stochastic reasoning trajectories. However, achieving sample-efficient test-time self-consistency under a limited budget remains an open challenge. We introduce PETS (Principled and Efficient Test-TimeSelf-Consistency), which initiates a principled study of trajectory allocation through an optimization framework. Central to our approach is the self-consistency rate, a new measure defined as agreement with the infinite-budget majority vote. This formulation makes sample-efficient test-time allocation theoretically grounded and amenable to rigorous analysis. We study both offline and online settings. In the offline regime, where all questions are known in advance, we connect trajectory allocation to crowdsourcing, a classic and well-developed area, by modeling reasoning traces as workers. This perspective allows us to leverage rich existing theory, yielding theoretical guarantees and an efficient majority-voting-based allocation algorithm. In the online streaming regime, where questions arrive sequentially and allocations must be made on the fly, we propose a novel method inspired by the offline framework. Our approach adapts budgets to question difficulty while preserving strong theoretical guarantees and computational efficiency. Experiments show that PETS consistently outperforms uniform allocation. On GPQA, PETS achieves perfect self-consistency in both settings while reducing the sampling budget by up to 75% (offline) and 55% (online) relative to uniform allocation. Code is available at https://github.com/ZDCSlab/PETS.
Universal priors: solving empirical Bayes via Bayesian inference and pretraining
Feb 16, 2026We theoretically justify the recent empirical finding of [Teh et al., 2025] that a transformer pretrained on synthetically generated data achieves strong performance on empirical Bayes (EB) problems. We take an indirect approach to this question: rather than analyzing the model architecture or training dynamics, we ask why a pretrained Bayes estimator, trained under a prespecified training distribution, can adapt to arbitrary test distributions. Focusing on Poisson EB problems, we identify the existence of universal priors such that training under these priors yields a near-optimal regret bound of $\widetilde{O}(\frac{1}{n})$ uniformly over all test distributions. Our analysis leverages the classical phenomenon of posterior contraction in Bayesian statistics, showing that the pretrained transformer adapts to unknown test distributions precisely through posterior contraction. This perspective also explains the phenomenon of length generalization, in which the test sequence length exceeds the training length, as the model performs Bayesian inference using a generalized posterior.
Joint Value Estimation and Bidding in Repeated First-Price Auctions
Feb 24, 2025We study regret minimization in repeated first-price auctions (FPAs), where a bidder observes only the realized outcome after each auction -- win or loss. This setup reflects practical scenarios in online display advertising where the actual value of an impression depends on the difference between two potential outcomes, such as clicks or conversion rates, when the auction is won versus lost. We analyze three outcome models: (1) adversarial outcomes without features, (2) linear potential outcomes with features, and (3) linear treatment effects in features. For each setting, we propose algorithms that jointly estimate private values and optimize bidding strategies, achieving near-optimal regret bounds. Notably, our framework enjoys a unique feature that the treatments are also actively chosen, and hence eliminates the need for the overlap condition commonly required in causal inference.
Assouad, Fano, and Le Cam with Interaction: A Unifying Lower Bound Framework and Characterization for Bandit Learnability
Oct 07, 2024In this paper, we develop a unified framework for lower bound methods in statistical estimation and interactive decision making. Classical lower bound techniques -- such as Fano's inequality, Le Cam's method, and Assouad's lemma -- have been central to the study of minimax risk in statistical estimation, yet they are insufficient for the analysis of methods that collect data in an interactive manner. The recent minimax lower bounds for interactive decision making via the Decision-Estimation Coefficient (DEC) appear to be genuinely different from the classical methods. We propose a unified view of these distinct methodologies through a general algorithmic lower bound method. We further introduce a novel complexity measure, decision dimension, which facilitates the derivation of new lower bounds for interactive decision making. In particular, decision dimension provides a characterization of bandit learnability for any structured bandit model class. Further, we characterize the sample complexity of learning convex model class up to a polynomial gap with the decision dimension, addressing the remaining gap between upper and lower bounds in Foster et al. (2021, 2023).
Online Estimation via Offline Estimation: An Information-Theoretic Framework
Apr 15, 2024$ $The classical theory of statistical estimation aims to estimate a parameter of interest under data generated from a fixed design ("offline estimation"), while the contemporary theory of online learning provides algorithms for estimation under adaptively chosen covariates ("online estimation"). Motivated by connections between estimation and interactive decision making, we ask: is it possible to convert offline estimation algorithms into online estimation algorithms in a black-box fashion? We investigate this question from an information-theoretic perspective by introducing a new framework, Oracle-Efficient Online Estimation (OEOE), where the learner can only interact with the data stream indirectly through a sequence of offline estimators produced by a black-box algorithm operating on the stream. Our main results settle the statistical and computational complexity of online estimation in this framework. $\bullet$ Statistical complexity. We show that information-theoretically, there exist algorithms that achieve near-optimal online estimation error via black-box offline estimation oracles, and give a nearly-tight characterization for minimax rates in the OEOE framework. $\bullet$ Computational complexity. We show that the guarantees above cannot be achieved in a computationally efficient fashion in general, but give a refined characterization for the special case of conditional density estimation: computationally efficient online estimation via black-box offline estimation is possible whenever it is possible via unrestricted algorithms. Finally, we apply our results to give offline oracle-efficient algorithms for interactive decision making.
Stochastic contextual bandits with graph feedback: from independence number to MAS number
Feb 12, 2024We consider contextual bandits with graph feedback, a class of interactive learning problems with richer structures than vanilla contextual bandits, where taking an action reveals the rewards for all neighboring actions in the feedback graph under all contexts. Unlike the multi-armed bandits setting where a growing literature has painted a near-complete understanding of graph feedback, much remains unexplored in the contextual bandits counterpart. In this paper, we make inroads into this inquiry by establishing a regret lower bound $\Omega(\sqrt{\beta_M(G) T})$, where $M$ is the number of contexts, $G$ is the feedback graph, and $\beta_M(G)$ is our proposed graph-theoretical quantity that characterizes the fundamental learning limit for this class of problems. Interestingly, $\beta_M(G)$ interpolates between $\alpha(G)$ (the independence number of the graph) and $\mathsf{m}(G)$ (the maximum acyclic subgraph (MAS) number of the graph) as the number of contexts $M$ varies. We also provide algorithms that achieve near-optimal regrets for important classes of context sequences and/or feedback graphs, such as transitively closed graphs that find applications in auctions and inventory control. In particular, with many contexts, our results show that the MAS number completely characterizes the statistical complexity for contextual bandits, as opposed to the independence number in multi-armed bandits.
Covariance alignment: from maximum likelihood estimation to Gromov-Wasserstein
Nov 22, 2023

Feature alignment methods are used in many scientific disciplines for data pooling, annotation, and comparison. As an instance of a permutation learning problem, feature alignment presents significant statistical and computational challenges. In this work, we propose the covariance alignment model to study and compare various alignment methods and establish a minimax lower bound for covariance alignment that has a non-standard dimension scaling because of the presence of a nuisance parameter. This lower bound is in fact minimax optimal and is achieved by a natural quasi MLE. However, this estimator involves a search over all permutations which is computationally infeasible even when the problem has moderate size. To overcome this limitation, we show that the celebrated Gromov-Wasserstein algorithm from optimal transport which is more amenable to fast implementation even on large-scale problems is also minimax optimal. These results give the first statistical justification for the deployment of the Gromov-Wasserstein algorithm in practice.
Online Learning in Multi-unit Auctions
May 27, 2023We consider repeated multi-unit auctions with uniform pricing, which are widely used in practice for allocating goods such as carbon licenses. In each round, $K$ identical units of a good are sold to a group of buyers that have valuations with diminishing marginal returns. The buyers submit bids for the units, and then a price $p$ is set per unit so that all the units are sold. We consider two variants of the auction, where the price is set to the $K$-th highest bid and $(K+1)$-st highest bid, respectively. We analyze the properties of this auction in both the offline and online settings. In the offline setting, we consider the problem that one player $i$ is facing: given access to a data set that contains the bids submitted by competitors in past auctions, find a bid vector that maximizes player $i$'s cumulative utility on the data set. We design a polynomial time algorithm for this problem, by showing it is equivalent to finding a maximum-weight path on a carefully constructed directed acyclic graph. In the online setting, the players run learning algorithms to update their bids as they participate in the auction over time. Based on our offline algorithm, we design efficient online learning algorithms for bidding. The algorithms have sublinear regret, under both full information and bandit feedback structures. We complement our online learning algorithms with regret lower bounds. Finally, we analyze the quality of the equilibria in the worst case through the lens of the core solution concept in the game among the bidders. We show that the $(K+1)$-st price format is susceptible to collusion among the bidders; meanwhile, the $K$-th price format does not have this issue.
Beyond UCB: Statistical Complexity and Optimal Algorithms for Non-linear Ridge Bandits
Feb 12, 2023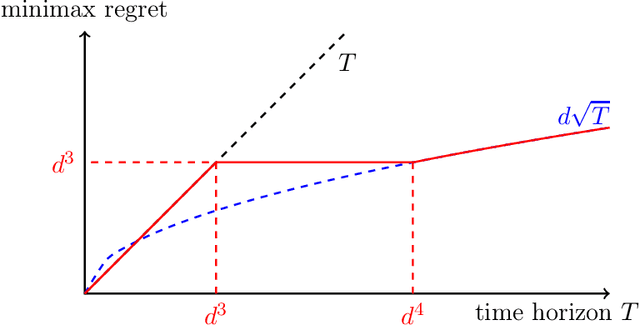
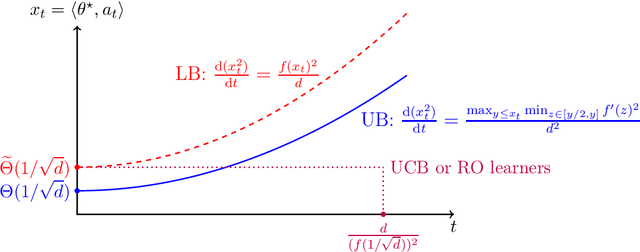
We consider the sequential decision-making problem where the mean outcome is a non-linear function of the chosen action. Compared with the linear model, two curious phenomena arise in non-linear models: first, in addition to the "learning phase" with a standard parametric rate for estimation or regret, there is an "burn-in period" with a fixed cost determined by the non-linear function; second, achieving the smallest burn-in cost requires new exploration algorithms. For a special family of non-linear functions named ridge functions in the literature, we derive upper and lower bounds on the optimal burn-in cost, and in addition, on the entire learning trajectory during the burn-in period via differential equations. In particular, a two-stage algorithm that first finds a good initial action and then treats the problem as locally linear is statistically optimal. In contrast, several classical algorithms, such as UCB and algorithms relying on regression oracles, are provably suboptimal.