 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Best: Estimating Distribution Functionals in Infinite-Armed Bandits
Nov 01, 2022



In the infinite-armed bandit problem, each arm's average reward is sampled from an unknown distribution, and each arm can be sampled further to obtain noisy estimates of the average reward of that arm. Prior work focuses on identifying the best arm, i.e., estimating the maximum of the average reward distribution. We consider a general class of distribution functionals beyond the maximum, and propose unified meta algorithms for both the offline and online settings, achieving optimal sample complexities. We show that online estimation, where the learner can sequentially choose whether to sample a new or existing arm, offers no advantage over the offline setting for estimating the mean functional, but significantly reduces the sample complexity for other functionals such as the median, maximum, and trimmed mean. The matching lower bounds utilize several different Wasserstein distances. For the special case of median estimation, we identify a curious thresholding phenomenon on the indistinguishability between Gaussian convolutions with respect to the noise level, which may be of independent interest.
Approximate Function Evaluation via Multi-Armed Bandits
Mar 18, 2022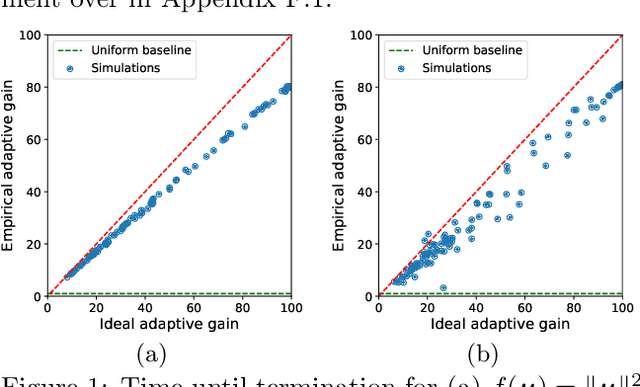
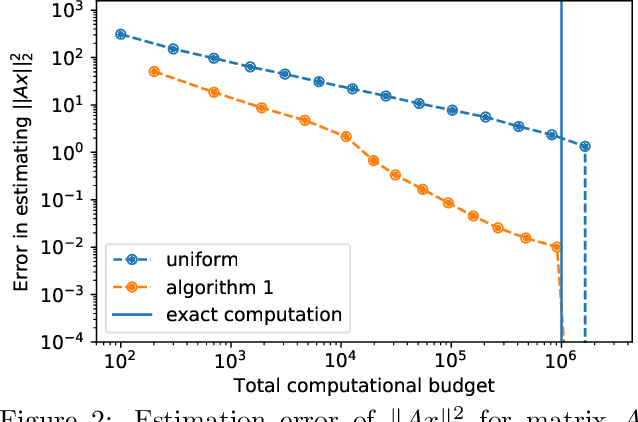
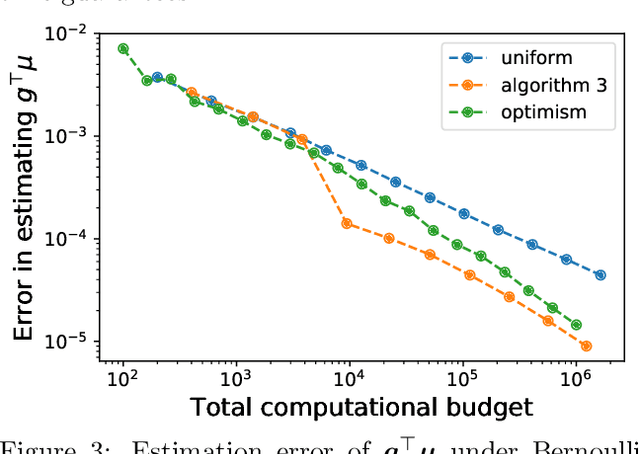
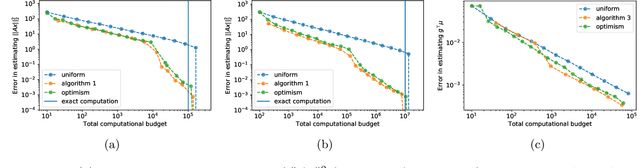
We study the problem of estimating the value of a known smooth function $f$ at an unknown point $\boldsymbol{\mu} \in \mathbb{R}^n$, where each component $\mu_i$ can be sampled via a noisy oracle. Sampling more frequently components of $\boldsymbol{\mu}$ corresponding to directions of the function with larger directional derivatives is more sample-efficient. However, as $\boldsymbol{\mu}$ is unknown, the optimal sampling frequencies are also unknown. We design an instance-adaptive algorithm that learns to sample according to the importance of each coordinate, and with probability at least $1-\delta$ returns an $\epsilon$ accurate estimate of $f(\boldsymbol{\mu})$. We generalize our algorithm to adapt to heteroskedastic noise, and prove asymptotic optimality when $f$ is linear. We corroborate our theoretical results with numerical experiments, showing the dramatic gains afforded by adaptivity.
Group-Structured Adversarial Training
Jun 18, 2021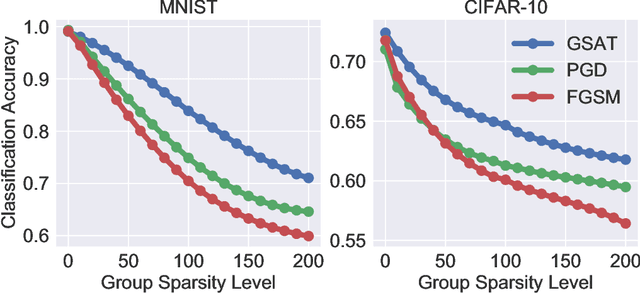
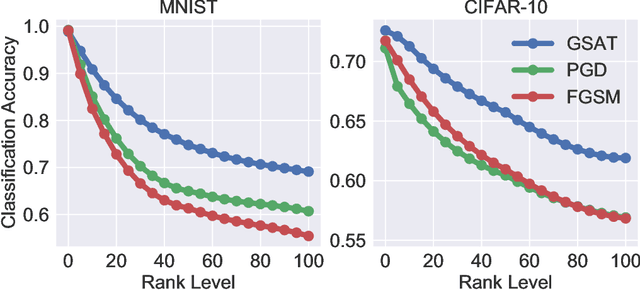
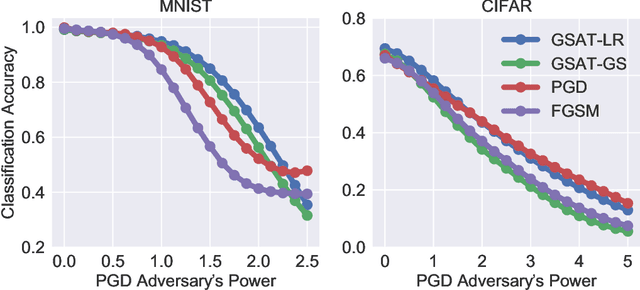
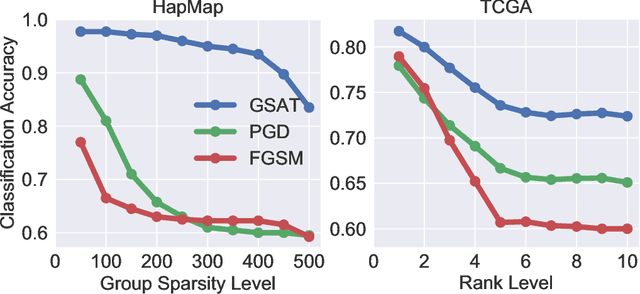
Robust training methods against perturbations to the input data have received great attention in the machine learning literature. A standard approach in this direction is adversarial training which learns a model using adversarially-perturbed training samples. However, adversarial training performs suboptimally against perturbations structured across samples such as universal and group-sparse shifts that are commonly present in biological data such as gene expression levels of different tissues. In this work, we seek to close this optimality gap and introduce Group-Structured Adversarial Training (GSAT) which learns a model robust to perturbations structured across samples. We formulate GSAT as a non-convex concave minimax optimization problem which minimizes a group-structured optimal transport cost. Specifically, we focus on the applications of GSAT for group-sparse and rank-constrained perturbations modeled using group and nuclear norm penalties. In order to solve GSAT's non-smooth optimization problem in those cases, we propose a new minimax optimization algorithm called GDADMM by combining Gradient Descent Ascent (GDA) and Alternating Direction Method of Multipliers (ADMM). We present several applications of the GSAT framework to gain robustness against structured perturbations for image recognition and computational biology datasets.
Deconstructing Generative Adversarial Networks
Jan 27, 2019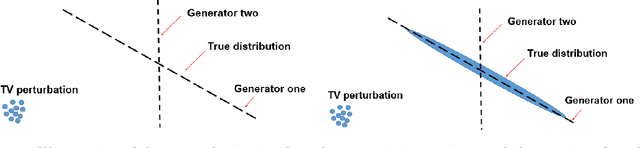


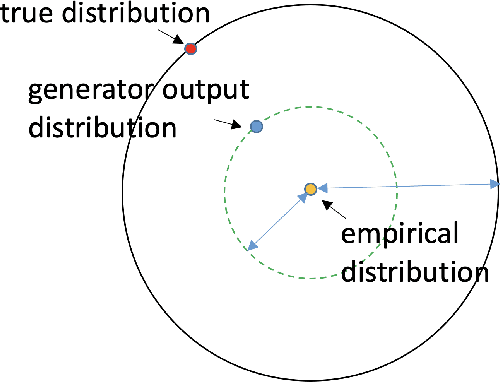
We deconstruct the performance of GANs into three components: 1. Formulation: we propose a perturbation view of the population target of GANs. Building on this interpretation, we show that GANs can be viewed as a generalization of the robust statistics framework, and propose a novel GAN architecture, termed as Cascade GANs, to provably recover meaningful low-dimensional generator approximations when the real distribution is high-dimensional and corrupted by outliers. 2. Generalization: given a population target of GANs, we design a systematic principle, projection under admissible distance, to design GANs to meet the population requirement using finite samples. We implement our principle in three cases to achieve polynomial and sometimes near-optimal sample complexities: (1) learning an arbitrary generator under an arbitrary pseudonorm; (2) learning a Gaussian location family under total variation distance, where we utilize our principle provide a new proof for the optimality of Tukey median viewed as GANs; (3) learning a low-dimensional Gaussian approximation of a high-dimensional arbitrary distribution under Wasserstein distance. We demonstrate a fundamental trade-off in the approximation error and statistical error in GANs, and show how to apply our principle with empirical samples to predict how many samples are sufficient for GANs in order not to suffer from the discriminator winning problem. 3. Optimization: we demonstrate alternating gradient descent is provably not even locally stable in optimizating the GAN formulation of PCA. We diagnose the problem as the minimax duality gap being non-zero, and propose a new GAN architecture whose duality gap is zero, where the value of the game is equal to the previous minimax value (not the maximin value). We prove the new GAN architecture is globally stable in optimization under alternating gradient descent.
Generalizable Adversarial Training via Spectral Normalization
Nov 19, 2018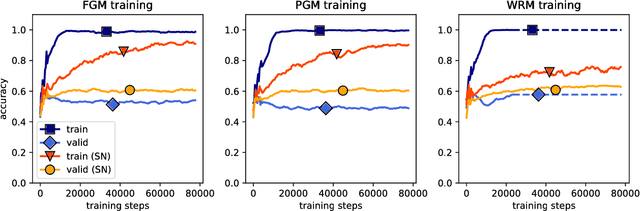
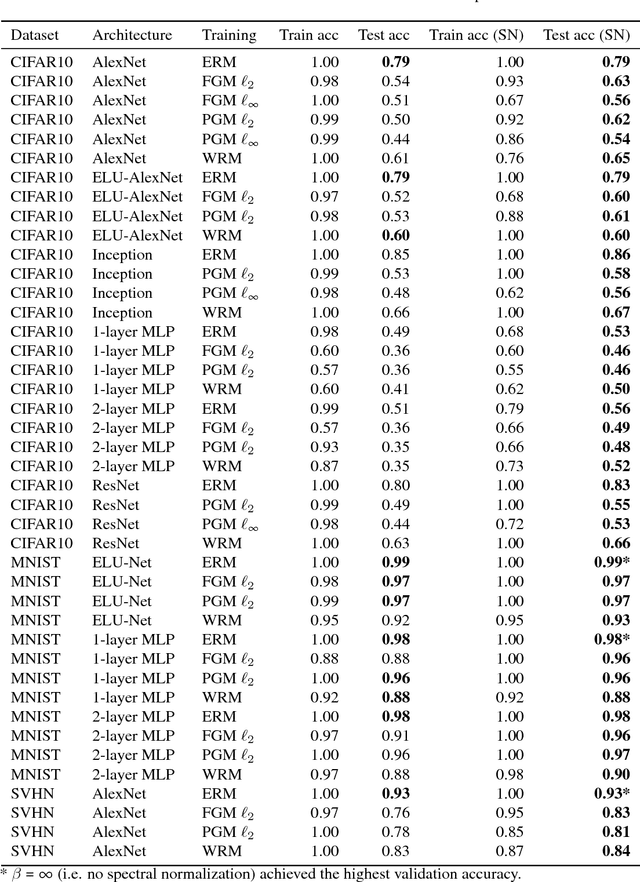
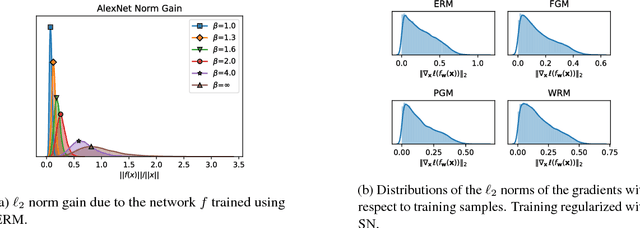
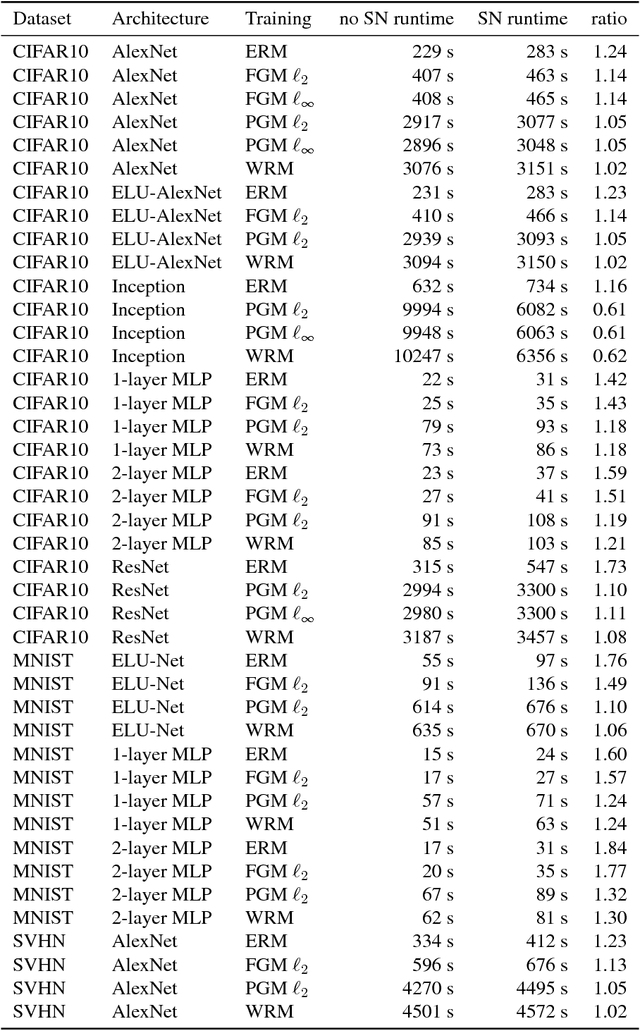
Deep neural networks (DNNs) have set benchmarks on a wide array of supervised learning tasks. Trained DNNs, however, often lack robustness to minor adversarial perturbations to the input, which undermines their true practicality. Recent works have increased the robustness of DNNs by fitting networks using adversarially-perturbed training samples, but the improved performance can still be far below the performance seen in non-adversarial settings. A significant portion of this gap can be attributed to the decrease in generalization performance due to adversarial training. In this work, we extend the notion of margin loss to adversarial settings and bound the generalization error for DNNs trained under several well-known gradient-based attack schemes, motivating an effective regularization scheme based on spectral normalization of the DNN's weight matrices. We also provide a computationally-efficient method for normalizing the spectral norm of convolutional layers with arbitrary stride and padding schemes in deep convolutional networks. We evaluate the power of spectral normalization extensively on combinations of datasets, network architectures, and adversarial training schemes. The code is available at https://github.com/jessemzhang/dl_spectral_normalization.
A Convex Duality Framework for GANs
Oct 28, 2018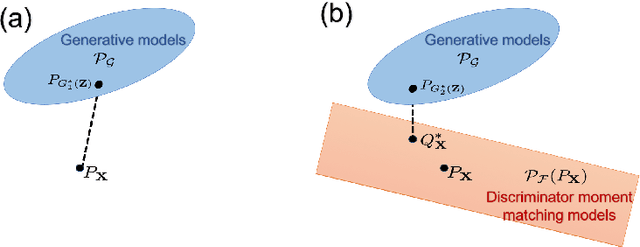
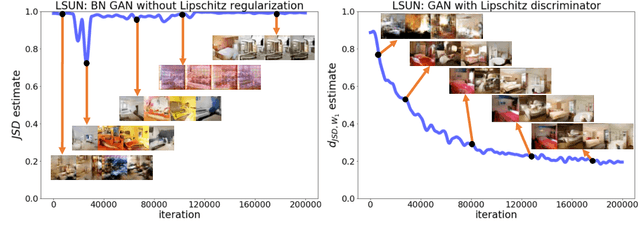

Generative adversarial network (GAN) is a minimax game between a generator mimicking the true model and a discriminator distinguishing the samples produced by the generator from the real training samples. Given an unconstrained discriminator able to approximate any function, this game reduces to finding the generative model minimizing a divergence measure, e.g. the Jensen-Shannon (JS) divergence, to the data distribution. However, in practice the discriminator is constrained to be in a smaller class $\mathcal{F}$ such as neural nets. Then, a natural question is how the divergence minimization interpretation changes as we constrain $\mathcal{F}$. In this work, we address this question by developing a convex duality framework for analyzing GANs. For a convex set $\mathcal{F}$, this duality framework interprets the original GAN formulation as finding the generative model with minimum JS-divergence to the distributions penalized to match the moments of the data distribution, with the moments specified by the discriminators in $\mathcal{F}$. We show that this interpretation more generally holds for f-GAN and Wasserstein GAN. As a byproduct, we apply the duality framework to a hybrid of f-divergence and Wasserstein distance. Unlike the f-divergence, we prove that the proposed hybrid divergence changes continuously with the generative model, which suggests regularizing the discriminator's Lipschitz constant in f-GAN and vanilla GAN. We numerically evaluate the power of the suggested regularization schemes for improving GAN's training performance.
Understanding GANs: the LQG Setting
Oct 22, 2018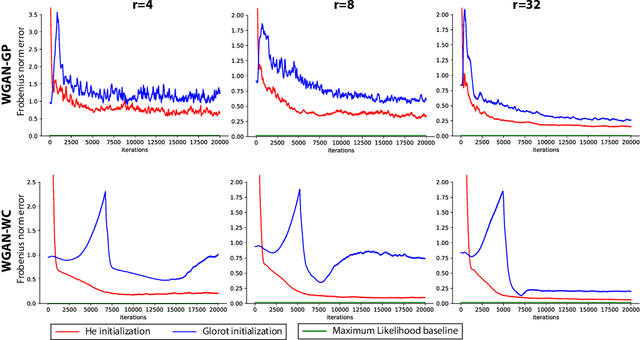
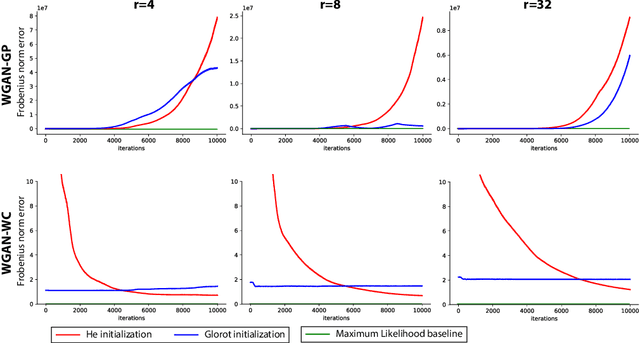
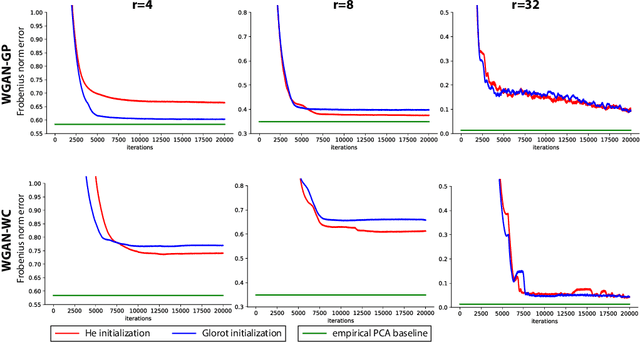
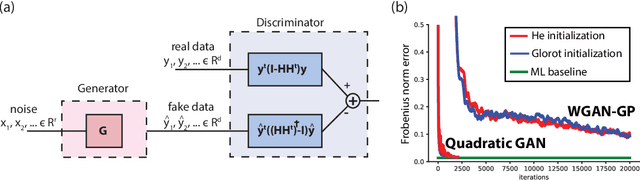
Generative Adversarial Networks (GANs) have become a popular method to learn a probability model from data. In this paper, we aim to provide an understanding of some of the basic issues surrounding GANs including their formulation, generalization and stability on a simple benchmark where the data has a high-dimensional Gaussian distribution. Even in this simple benchmark, the GAN problem has not been well-understood as we observe that existing state-of-the-art GAN architectures may fail to learn a proper generative distribution owing to (1) stability issues (i.e., convergence to bad local solutions or not converging at all), (2) approximation issues (i.e., having improper global GAN optimizers caused by inappropriate GAN's loss functions), and (3) generalizability issues (i.e., requiring large number of samples for training). In this setup, we propose a GAN architecture which recovers the maximum-likelihood solution and demonstrates fast generalization. Moreover, we analyze global stability of different computational approaches for the proposed GAN optimization and highlight their pros and cons. Finally, we outline an extension of our model-based approach to design GANs in more complex setups than the considered Gaussian benchmark.
Hidden Hamiltonian Cycle Recovery via Linear Programming
Apr 15, 2018

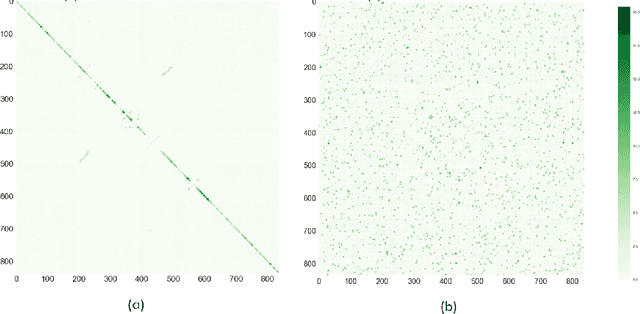

We introduce the problem of hidden Hamiltonian cycle recovery, where there is an unknown Hamiltonian cycle in an $n$-vertex complete graph that needs to be inferred from noisy edge measurements. The measurements are independent and distributed according to $\calP_n$ for edges in the cycle and $\calQ_n$ otherwise. This formulation is motivated by a problem in genome assembly, where the goal is to order a set of contigs (genome subsequences) according to their positions on the genome using long-range linking measurements between the contigs. Computing the maximum likelihood estimate in this model reduces to a Traveling Salesman Problem (TSP). Despite the NP-hardness of TSP, we show that a simple linear programming (LP) relaxation, namely the fractional $2$-factor (F2F) LP, recovers the hidden Hamiltonian cycle with high probability as $n \to \infty$ provided that $\alpha_n - \log n \to \infty$, where $\alpha_n \triangleq -2 \log \int \sqrt{d P_n d Q_n}$ is the R\'enyi divergence of order $\frac{1}{2}$. This condition is information-theoretically optimal in the sense that, under mild distributional assumptions, $\alpha_n \geq (1+o(1)) \log n$ is necessary for any algorithm to succeed regardless of the computational cost. Departing from the usual proof techniques based on dual witness construction, the analysis relies on the combinatorial characterization (in particular, the half-integrality) of the extreme points of the F2F polytope. Represented as bicolored multi-graphs, these extreme points are further decomposed into simpler "blossom-type" structures for the large deviation analysis and counting arguments. Evaluation of the algorithm on real data shows improvements over existing approaches.
NeuralFDR: Learning Discovery Thresholds from Hypothesis Features
Nov 18, 2017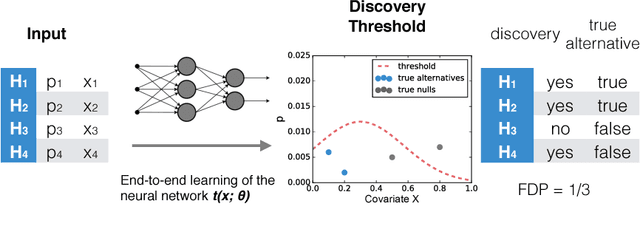
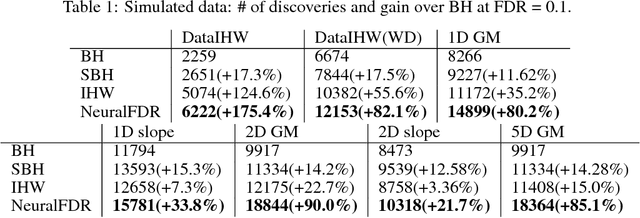
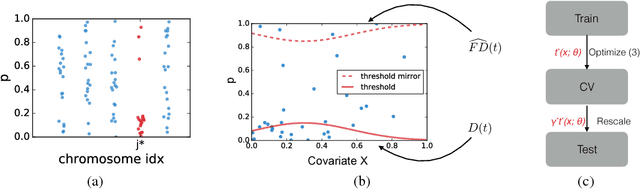
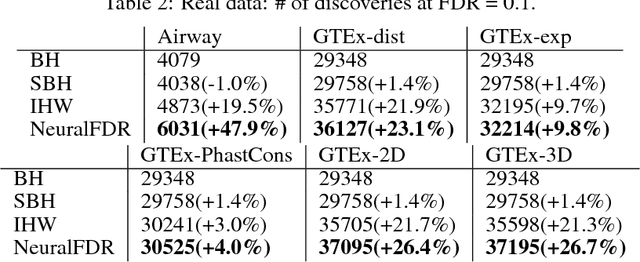
As datasets grow richer, an important challenge is to leverage the full features in the data to maximize the number of useful discoveries while controlling for false positives. We address this problem in the context of multiple hypotheses testing, where for each hypothesis, we observe a p-value along with a set of features specific to that hypothesis. For example, in genetic association studies, each hypothesis tests the correlation between a variant and the trait. We have a rich set of features for each variant (e.g. its location, conservation, epigenetics etc.) which could inform how likely the variant is to have a true association. However popular testing approaches, such as Benjamini-Hochberg's procedure (BH) and independent hypothesis weighting (IHW), either ignore these features or assume that the features are categorical or uni-variate. We propose a new algorithm, NeuralFDR, which automatically learns a discovery threshold as a function of all the hypothesis features. We parametrize the discovery threshold as a neural network, which enables flexible handling of multi-dimensional discrete and continuous features as well as efficient end-to-end optimization. We prove that NeuralFDR has strong false discovery rate (FDR) guarantees, and show that it makes substantially more discoveries in synthetic and real datasets. Moreover, we demonstrate that the learned discovery threshold is directly interpretable.
Medoids in almost linear time via multi-armed bandits
Nov 07, 2017
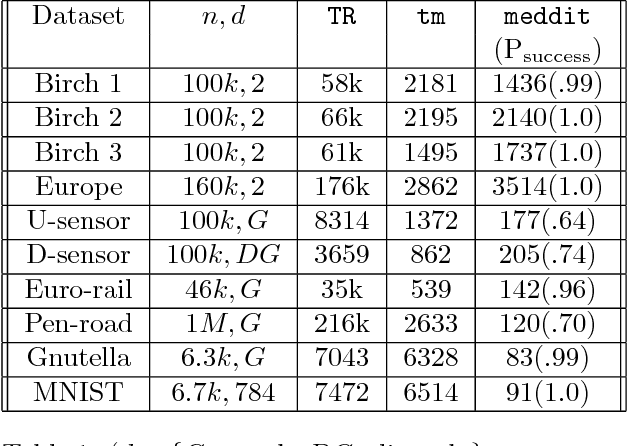
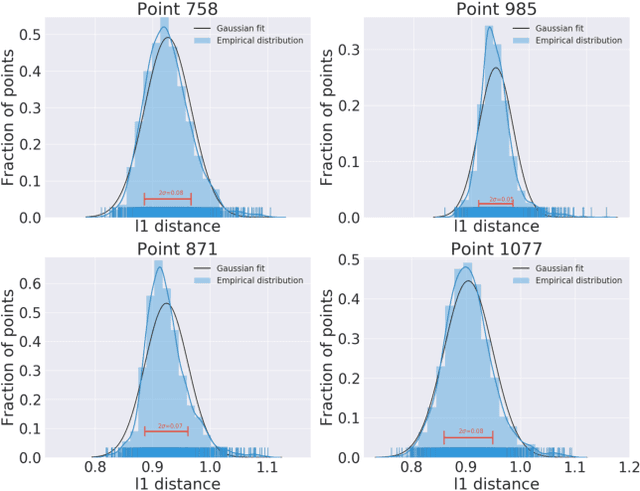
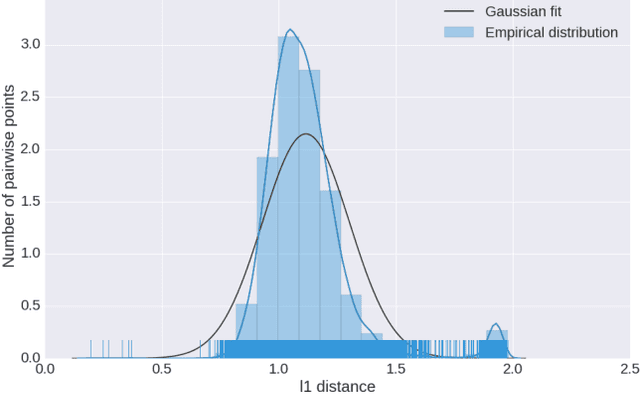
Computing the medoid of a large number of points in high-dimensional space is an increasingly common operation in many data science problems. We present an algorithm Med-dit which uses O(n log n) distance evaluations to compute the medoid with high probability. Med-dit is based on a connection with the multi-armed bandit problem. We evaluate the performance of Med-dit empirically on the Netflix-prize and the single-cell RNA-Seq datasets, containing hundreds of thousands of points living in tens of thousands of dimensions, and observe a 5-10x improvement in performance over the current state of the art. Med-dit is available at https://github.com/bagavi/Meddit