 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked SVD or SVD stacked? A Random Matrix Theory perspective on data integration
Jul 29, 2025



Modern data analysis increasingly requires identifying shared latent structure across multiple high-dimensional datasets. A commonly used model assumes that the data matrices are noisy observations of low-rank matrices with a shared singular subspace. In this case, two primary methods have emerged for estimating this shared structure, which vary in how they integrate information across datasets. The first approach, termed Stack-SVD, concatenates all the datasets, and then performs a singular value decomposition (SVD). The second approach, termed SVD-Stack, first performs an SVD separately for each dataset, then aggregates the top singular vectors across these datasets, and finally computes a consensus amongst them. While these methods are widely used, they have not been rigorously studied in the proportional asymptotic regime, which is of great practical relevance in today's world of increasing data size and dimensionality. This lack of theoretical understanding has led to uncertainty about which method to choose and limited the ability to fully exploit their potential. To address these challenges, we derive exact expressions for the asymptotic performance and phase transitions of these two methods and develop optimal weighting schemes to further improve both methods. Our analysis reveals that while neither method uniformly dominates the other in the unweighted case, optimally weighted Stack-SVD dominates optimally weighted SVD-Stack. We extend our analysis to accommodate multiple shared components, and provide practical algorithms for estimating optimal weights from data, offering theoretical guidance for method selection in practical data integration problems. Extensive numerical simulations and semi-synthetic experiments on genomic data corroborate our theoretical findings.
Adaptive Data Depth via Multi-Armed Bandits
Nov 09, 2022



Data depth, introduced by Tukey (1975), is an important tool in data science, robust statistics, and computational geometry. One chief barrier to its broader practical utility is that many common measures of depth are computationally intensive, requiring on the order of $n^d$ operations to exactly compute the depth of a single point within a data set of $n$ points in $d$-dimensional space. Often however, we are not directly interested in the absolute depths of the points, but rather in their relative ordering. For example, we may want to find the most central point in a data set (a generalized median), or to identify and remove all outliers (points on the fringe of the data set with low depth). With this observation, we develop a novel and instance-adaptive algorithm for adaptive data depth computation by reducing the problem of exactly computing $n$ depths to an $n$-armed stochastic multi-armed bandit problem which we can efficiently solve. We focus our exposition on simplicial depth, developed by Liu (1990), which has emerged as a promising notion of depth due to its interpretability and asymptotic properties. We provide general instance-dependent theoretical guarantees for our proposed algorithms, which readily extend to many other common measures of data depth including majority depth, Oja depth, and likelihood depth. When specialized to the case where the gaps in the data follow a power law distribution with parameter $\alpha<2$, we show that we can reduce the complexity of identifying the deepest point in the data set (the simplicial median) from $O(n^d)$ to $\tilde{O}(n^{d-(d-1)\alpha/2})$, where $\tilde{O}$ suppresses logarithmic factors. We corroborate our theoretical results with numerical experiments on synthetic data, showing the practical utility of our proposed methods.
Approximate Function Evaluation via Multi-Armed Bandits
Mar 18, 2022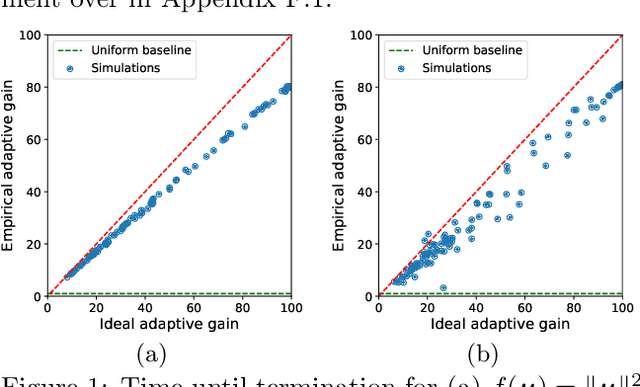
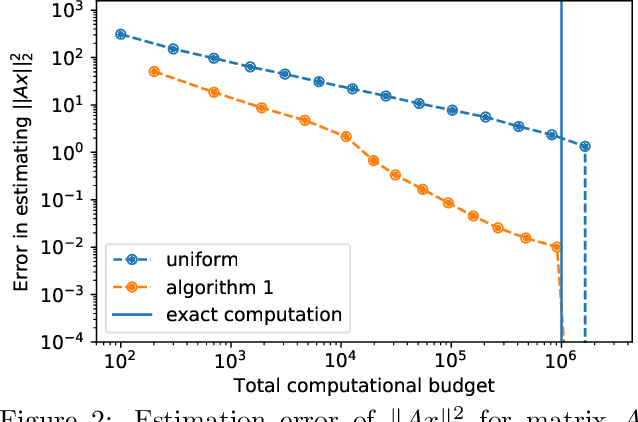
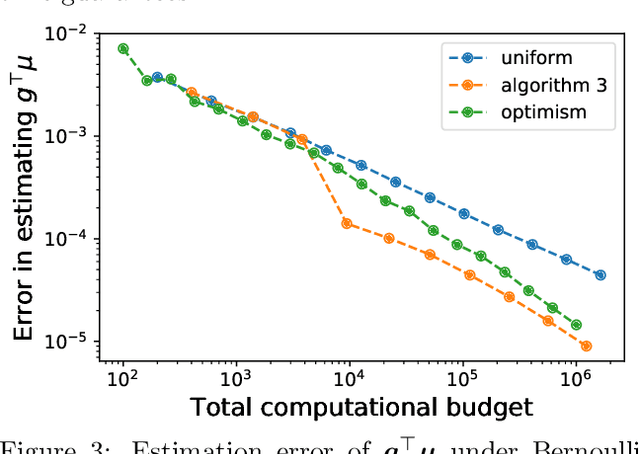
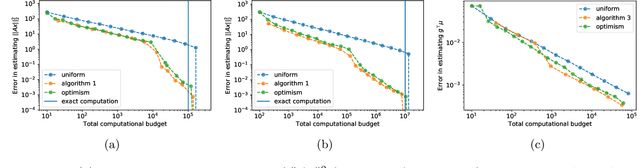
We study the problem of estimating the value of a known smooth function $f$ at an unknown point $\boldsymbol{\mu} \in \mathbb{R}^n$, where each component $\mu_i$ can be sampled via a noisy oracle. Sampling more frequently components of $\boldsymbol{\mu}$ corresponding to directions of the function with larger directional derivatives is more sample-efficient. However, as $\boldsymbol{\mu}$ is unknown, the optimal sampling frequencies are also unknown. We design an instance-adaptive algorithm that learns to sample according to the importance of each coordinate, and with probability at least $1-\delta$ returns an $\epsilon$ accurate estimate of $f(\boldsymbol{\mu})$. We generalize our algorithm to adapt to heteroskedastic noise, and prove asymptotic optimality when $f$ is linear. We corroborate our theoretical results with numerical experiments, showing the dramatic gains afforded by adaptivity.
Enabling Efficiency-Precision Trade-offs for Label Trees in Extreme Classification
Jun 01, 2021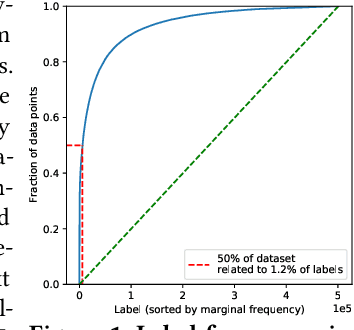
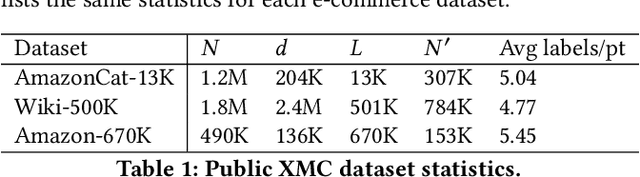
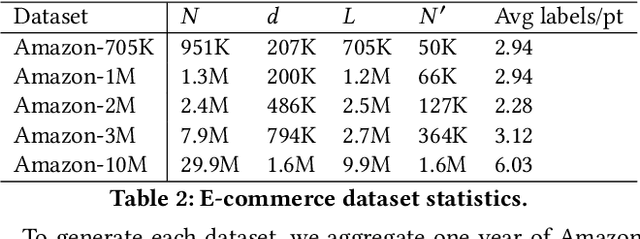
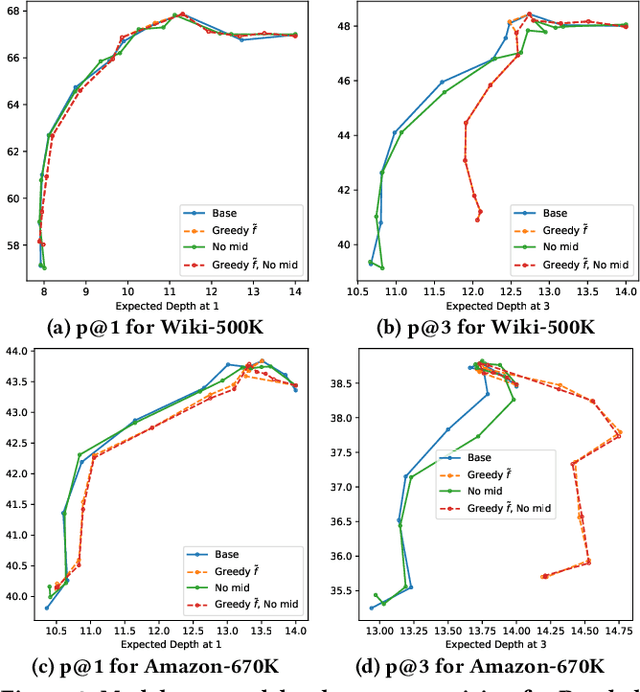
Extreme multi-label classification (XMC) aims to learn a model that can tag data points with a subset of relevant labels from an extremely large label set. Real world e-commerce applications like personalized recommendations and product advertising can be formulated as XMC problems, where the objective is to predict for a user a small subset of items from a catalog of several million products. For such applications, a common approach is to organize these labels into a tree, enabling training and inference times that are logarithmic in the number of labels. While training a model once a label tree is available is well studied, designing the structure of the tree is a difficult task that is not yet well understood, and can dramatically impact both model latency and statistical performance. Existing approaches to tree construction fall at an extreme point, either optimizing exclusively for statistical performance, or for latency. We propose an efficient information theory inspired algorithm to construct intermediary operating points that trade off between the benefits of both. Our algorithm enables interpolation between these objectives, which was not previously possible. We corroborate our theoretical analysis with numerical results, showing that on the Wiki-500K benchmark dataset our method can reduce a proxy for expected latency by up to 28% while maintaining the same accuracy as Parabel. On several datasets derived from e-commerce customer logs, our modified label tree is able to improve this expected latency metric by up to 20% while maintaining the same accuracy. Finally, we discuss challenges in realizing these latency improvements in deployed models.
Adaptive Learning of Rank-One Models for Efficient Pairwise Sequence Alignment
Nov 09, 2020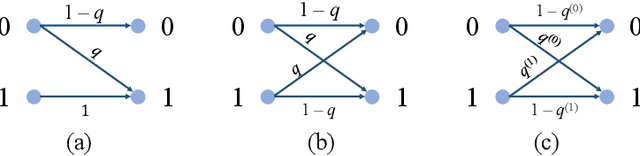
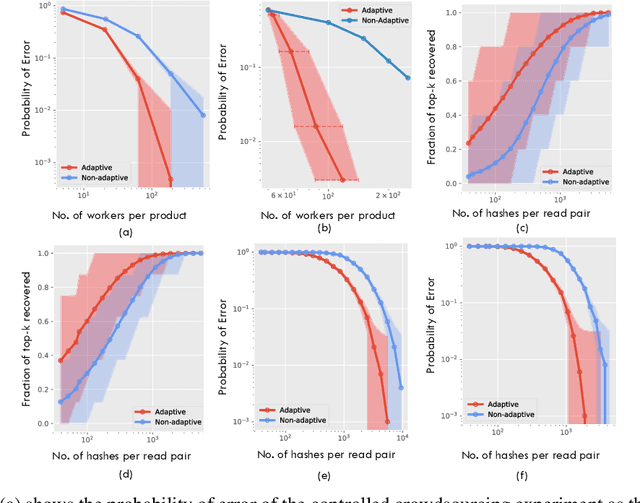
Pairwise alignment of DNA sequencing data is a ubiquitous task in bioinformatics and typically represents a heavy computational burden. State-of-the-art approaches to speed up this task use hashing to identify short segments (k-mers) that are shared by pairs of reads, which can then be used to estimate alignment scores. However, when the number of reads is large, accurately estimating alignment scores for all pairs is still very costly. Moreover, in practice, one is only interested in identifying pairs of reads with large alignment scores. In this work, we propose a new approach to pairwise alignment estimation based on two key new ingredients. The first ingredient is to cast the problem of pairwise alignment estimation under a general framework of rank-one crowdsourcing models, where the workers' responses correspond to k-mer hash collisions. These models can be accurately solved via a spectral decomposition of the response matrix. The second ingredient is to utilise a multi-armed bandit algorithm to adaptively refine this spectral estimator only for read pairs that are likely to have large alignments. The resulting algorithm iteratively performs a spectral decomposition of the response matrix for adaptively chosen subsets of the read pairs.
My Fair Bandit: Distributed Learning of Max-Min Fairness with Multi-player Bandits
Aug 21, 2020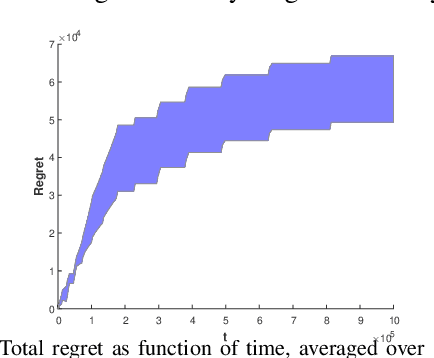
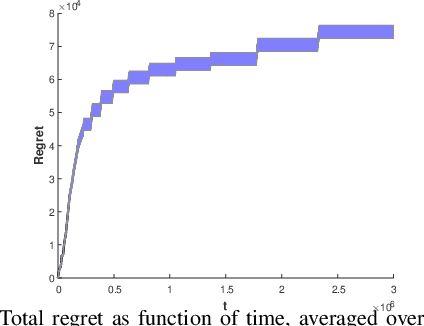
Consider N cooperative but non-communicating players where each plays one out of M arms for T turns. Players have different utilities for each arm, representable as an NxM matrix. These utilities are unknown to the players. In each turn players select an arm and receive a noisy observation of their utility for it. However, if any other players selected the same arm that turn, all colliding players will all receive zero utility due to the conflict. No other communication or coordination between the players is possible. Our goal is to design a distributed algorithm that learns the matching between players and arms that achieves max-min fairness while minimizing the regret. We present an algorithm and prove that it is regret optimal up to a $\log\log T$ factor. This is the first max-min fairness multi-player bandit algorithm with (near) order optimal regret.
Ultra Fast Medoid Identification via Correlated Sequential Halving
Jun 11, 2019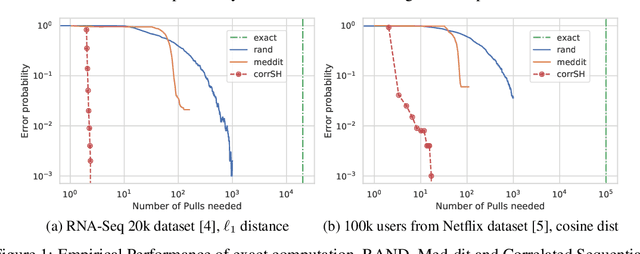
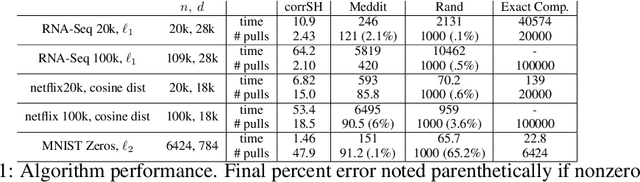
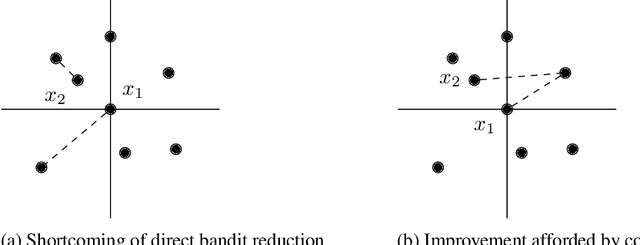
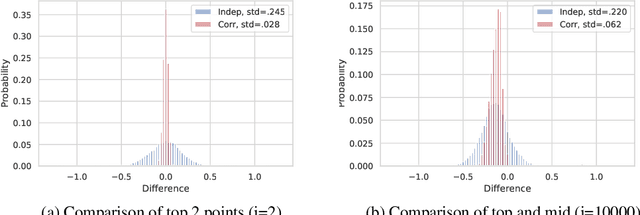
The medoid of a set of $n$ points is the point in the set that minimizes the sum of distances to other points. Computing the medoid can be solved exactly in $O(n^2)$ time by computing the distances between all pairs of points. Previous work shows that one can significantly reduce the number of distance computations needed by adaptively querying distances. The resulting randomized algorithm is obtained by a direct conversion of the computation problem to a multi-armed bandit statistical inference problem. In this work, we show that we can better exploit the structure of the underlying computation problem by modifying the traditional bandit sampling strategy and using it in conjunction with a suitably chosen multi-armed bandit algorithm. Four to five orders of magnitude gains over exact computation are obtained on real data, in terms of both number of distance computations needed and wall clock time. Theoretical results are obtained to quantify such gains in terms of data parameters. Our code is publicly available online at https://github.com/NEURIPS-anonymous-2019/Correlated-Sequential-Halving.