 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInitializing Services in Interactive ML Systems for Diverse Users
Dec 19, 2023This paper studies ML systems that interactively learn from users across multiple subpopulations with heterogeneous data distributions. The primary objective is to provide specialized services for different user groups while also predicting user preferences. Once the users select a service based on how well the service anticipated their preference, the services subsequently adapt and refine themselves based on the user data they accumulate, resulting in an iterative, alternating minimization process between users and services (learning dynamics). Employing such tailored approaches has two main challenges: (i) Unknown user preferences: Typically, data on user preferences are unavailable without interaction, and uniform data collection across a large and diverse user base can be prohibitively expensive. (ii) Suboptimal Local Solutions: The total loss (sum of loss functions across all users and all services) landscape is not convex even if the individual losses on a single service are convex, making it likely for the learning dynamics to get stuck in local minima. The final outcome of the aforementioned learning dynamics is thus strongly influenced by the initial set of services offered to users, and is not guaranteed to be close to the globally optimal outcome. In this work, we propose a randomized algorithm to adaptively select very few users to collect preference data from, while simultaneously initializing a set of services. We prove that under mild assumptions on the loss functions, the expected total loss achieved by the algorithm right after initialization is within a factor of the globally optimal total loss with complete user preference data, and this factor scales only logarithmically in the number of services. Our theory is complemented by experiments on real as well as semi-synthetic datasets.
Enabling Efficiency-Precision Trade-offs for Label Trees in Extreme Classification
Jun 01, 2021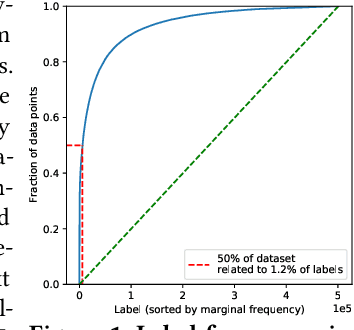
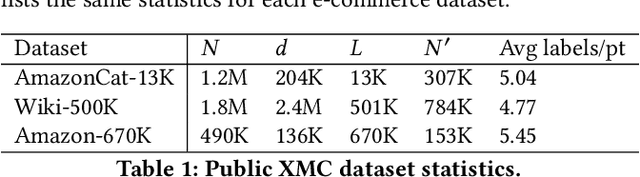
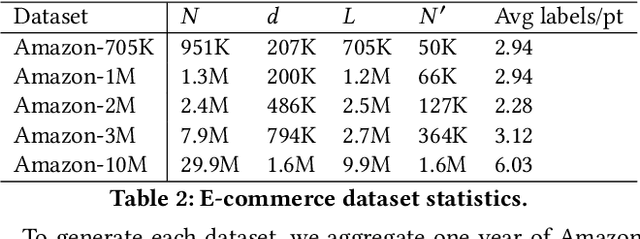
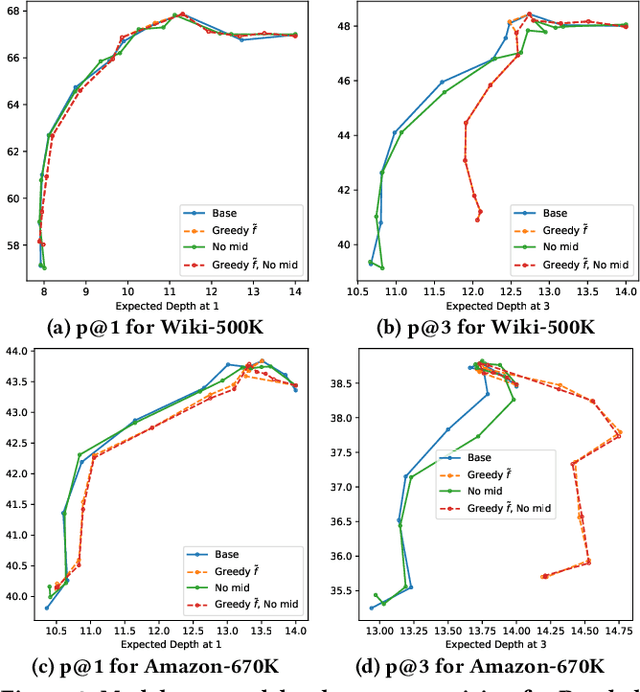
Extreme multi-label classification (XMC) aims to learn a model that can tag data points with a subset of relevant labels from an extremely large label set. Real world e-commerce applications like personalized recommendations and product advertising can be formulated as XMC problems, where the objective is to predict for a user a small subset of items from a catalog of several million products. For such applications, a common approach is to organize these labels into a tree, enabling training and inference times that are logarithmic in the number of labels. While training a model once a label tree is available is well studied, designing the structure of the tree is a difficult task that is not yet well understood, and can dramatically impact both model latency and statistical performance. Existing approaches to tree construction fall at an extreme point, either optimizing exclusively for statistical performance, or for latency. We propose an efficient information theory inspired algorithm to construct intermediary operating points that trade off between the benefits of both. Our algorithm enables interpolation between these objectives, which was not previously possible. We corroborate our theoretical analysis with numerical results, showing that on the Wiki-500K benchmark dataset our method can reduce a proxy for expected latency by up to 28% while maintaining the same accuracy as Parabel. On several datasets derived from e-commerce customer logs, our modified label tree is able to improve this expected latency metric by up to 20% while maintaining the same accuracy. Finally, we discuss challenges in realizing these latency improvements in deployed models.
The Power of Batching in Multiple Hypothesis Testing
Nov 01, 2019
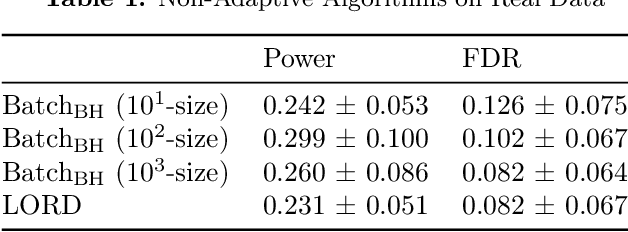
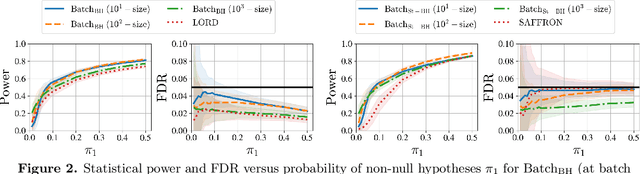

One important partition of algorithms for controlling the false discovery rate (FDR) in multiple testing is into offline and online algorithms. The first generally achieve significantly higher power of discovery, while the latter allow making decisions sequentially as well as adaptively formulating hypotheses based on past observations. Using existing methodology, it is unclear how one could trade off the benefits of these two broad families of algorithms, all the while preserving their formal FDR guarantees. To this end, we introduce $\text{Batch}_{\text{BH}}$ and $\text{Batch}_{\text{St-BH}}$, algorithms for controlling the FDR when a possibly infinite sequence of batches of hypotheses is tested by repeated application of one of the most widely used offline algorithms, the Benjamini-Hochberg (BH) method or Storey's improvement of the BH method. We show that our algorithms interpolate between existing online and offline methodology, thus trading off the best of both worlds.