 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCold-Start Personalization via Training-Free Priors from Structured World Models
Feb 16, 2026Cold-start personalization requires inferring user preferences through interaction when no user-specific historical data is available. The core challenge is a routing problem: each task admits dozens of preference dimensions, yet individual users care about only a few, and which ones matter depends on who is asking. With a limited question budget, asking without structure will miss the dimensions that matter. Reinforcement learning is the natural formulation, but in multi-turn settings its terminal reward fails to exploit the factored, per-criterion structure of preference data, and in practice learned policies collapse to static question sequences that ignore user responses. We propose decomposing cold-start elicitation into offline structure learning and online Bayesian inference. Pep (Preference Elicitation with Priors) learns a structured world model of preference correlations offline from complete profiles, then performs training-free Bayesian inference online to select informative questions and predict complete preference profiles, including dimensions never asked about. The framework is modular across downstream solvers and requires only simple belief models. Across medical, mathematical, social, and commonsense reasoning, Pep achieves 80.8% alignment between generated responses and users' stated preferences versus 68.5% for RL, with 3-5x fewer interactions. When two users give different answers to the same question, Pep changes its follow-up 39-62% of the time versus 0-28% for RL. It does so with ~10K parameters versus 8B for RL, showing that the bottleneck in cold-start elicitation is the capability to exploit the factored structure of preference data.
LoRe: Personalizing LLMs via Low-Rank Reward Modeling
Apr 20, 2025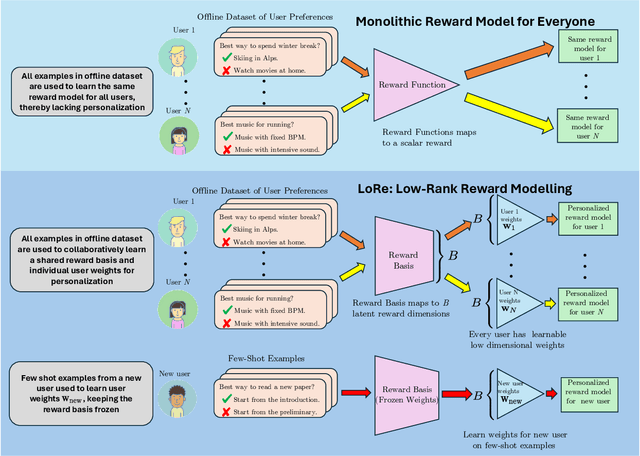
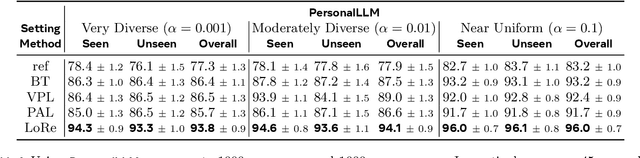
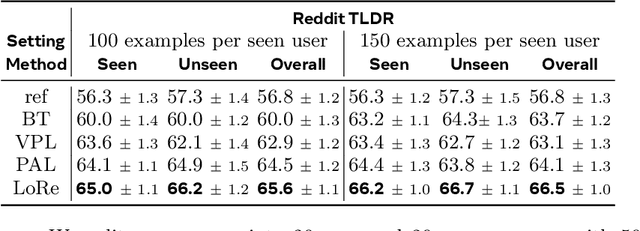
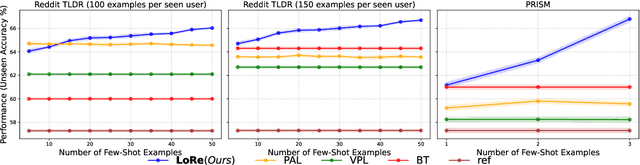
Personalizing large language models (LLMs) to accommodate diverse user preferences is essential for enhancing alignment and user satisfaction. Traditional reinforcement learning from human feedback (RLHF) approaches often rely on monolithic value representations, limiting their ability to adapt to individual preferences. We introduce a novel framework that leverages low-rank preference modeling to efficiently learn and generalize user-specific reward functions. By representing reward functions in a low-dimensional subspace and modeling individual preferences as weighted combinations of shared basis functions, our approach avoids rigid user categorization while enabling scalability and few-shot adaptation. We validate our method on multiple preference datasets, demonstrating superior generalization to unseen users and improved accuracy in preference prediction tasks.
Keeping up with dynamic attackers: Certifying robustness to adaptive online data poisoning
Feb 23, 2025The rise of foundation models fine-tuned on human feedback from potentially untrusted users has increased the risk of adversarial data poisoning, necessitating the study of robustness of learning algorithms against such attacks. Existing research on provable certified robustness against data poisoning attacks primarily focuses on certifying robustness for static adversaries who modify a fraction of the dataset used to train the model before the training algorithm is applied. In practice, particularly when learning from human feedback in an online sense, adversaries can observe and react to the learning process and inject poisoned samples that optimize adversarial objectives better than when they are restricted to poisoning a static dataset once, before the learning algorithm is applied. Indeed, it has been shown in prior work that online dynamic adversaries can be significantly more powerful than static ones. We present a novel framework for computing certified bounds on the impact of dynamic poisoning, and use these certificates to design robust learning algorithms. We give an illustration of the framework for the mean estimation and binary classification problems and outline directions for extending this in further work. The code to implement our certificates and replicate our results is available at https://github.com/Avinandan22/Certified-Robustness.
Hybrid Preference Optimization for Alignment: Provably Faster Convergence Rates by Combining Offline Preferences with Online Exploration
Dec 13, 2024Reinforcement Learning from Human Feedback (RLHF) is currently the leading approach for aligning large language models with human preferences. Typically, these models rely on extensive offline preference datasets for training. However, offline algorithms impose strict concentrability requirements, which are often difficult to satisfy. On the other hand, while online algorithms can avoid the concentrability issue, pure online exploration could be expensive due to the active preference query cost and real-time implementation overhead. In this paper, we propose a novel approach: Hybrid Preference Optimization (HPO) which combines online exploration with existing offline preferences by relaxing the stringent concentrability conditions for offline exploration, as well as significantly improving the sample efficiency for its online counterpart. We give the first provably optimal theoretical bound for Hybrid RLHF with preference feedback, providing sample complexity bounds for policy optimization with matching lower bounds. Our results yield improved sample efficiency of hybrid RLHF over pure offline and online exploration.
Offline Multi-task Transfer RL with Representational Penalization
Feb 19, 2024We study the problem of representation transfer in offline Reinforcement Learning (RL), where a learner has access to episodic data from a number of source tasks collected a priori, and aims to learn a shared representation to be used in finding a good policy for a target task. Unlike in online RL where the agent interacts with the environment while learning a policy, in the offline setting there cannot be such interactions in either the source tasks or the target task; thus multi-task offline RL can suffer from incomplete coverage. We propose an algorithm to compute pointwise uncertainty measures for the learnt representation, and establish a data-dependent upper bound for the suboptimality of the learnt policy for the target task. Our algorithm leverages the collective exploration done by source tasks to mitigate poor coverage at some points by a few tasks, thus overcoming the limitation of needing uniformly good coverage for a meaningful transfer by existing offline algorithms. We complement our theoretical results with empirical evaluation on a rich-observation MDP which requires many samples for complete coverage. Our findings illustrate the benefits of penalizing and quantifying the uncertainty in the learnt representation.
Initializing Services in Interactive ML Systems for Diverse Users
Dec 19, 2023This paper studies ML systems that interactively learn from users across multiple subpopulations with heterogeneous data distributions. The primary objective is to provide specialized services for different user groups while also predicting user preferences. Once the users select a service based on how well the service anticipated their preference, the services subsequently adapt and refine themselves based on the user data they accumulate, resulting in an iterative, alternating minimization process between users and services (learning dynamics). Employing such tailored approaches has two main challenges: (i) Unknown user preferences: Typically, data on user preferences are unavailable without interaction, and uniform data collection across a large and diverse user base can be prohibitively expensive. (ii) Suboptimal Local Solutions: The total loss (sum of loss functions across all users and all services) landscape is not convex even if the individual losses on a single service are convex, making it likely for the learning dynamics to get stuck in local minima. The final outcome of the aforementioned learning dynamics is thus strongly influenced by the initial set of services offered to users, and is not guaranteed to be close to the globally optimal outcome. In this work, we propose a randomized algorithm to adaptively select very few users to collect preference data from, while simultaneously initializing a set of services. We prove that under mild assumptions on the loss functions, the expected total loss achieved by the algorithm right after initialization is within a factor of the globally optimal total loss with complete user preference data, and this factor scales only logarithmically in the number of services. Our theory is complemented by experiments on real as well as semi-synthetic datasets.
Scalable Distributional Robustness in a Class of Non Convex Optimization with Guarantees
May 31, 2022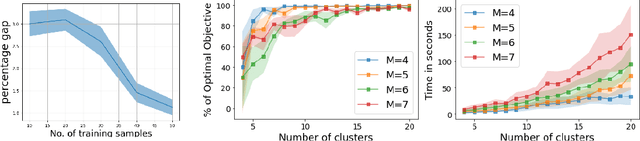
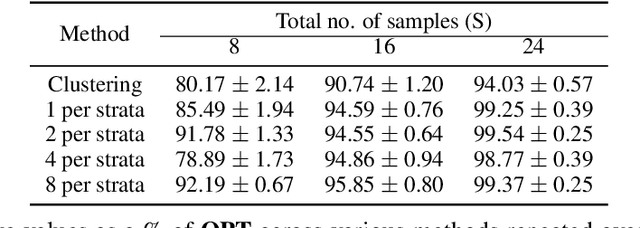

Distributionally robust optimization (DRO) has shown lot of promise in providing robustness in learning as well as sample based optimization problems. We endeavor to provide DRO solutions for a class of sum of fractionals, non-convex optimization which is used for decision making in prominent areas such as facility location and security games. In contrast to previous work, we find it more tractable to optimize the equivalent variance regularized form of DRO rather than the minimax form. We transform the variance regularized form to a mixed-integer second order cone program (MISOCP), which, while guaranteeing near global optimality, does not scale enough to solve problems with real world data-sets. We further propose two abstraction approaches based on clustering and stratified sampling to increase scalability, which we then use for real world data-sets. Importantly, we provide near global optimality guarantees for our approach and show experimentally that our solution quality is better than the locally optimal ones achieved by state-of-the-art gradient-based methods. We experimentally compare our different approaches and baselines, and reveal nuanced properties of a DRO solution.
Multiscale Generative Models: Improving Performance of a Generative Model Using Feedback from Other Dependent Generative Models
Jan 24, 2022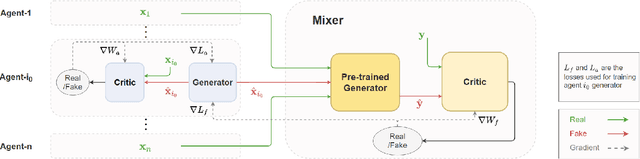


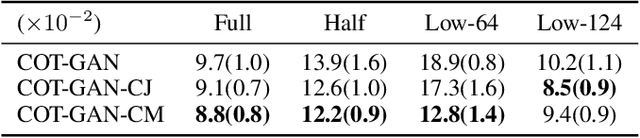
Realistic fine-grained multi-agent simulation of real-world complex systems is crucial for many downstream tasks such as reinforcement learning. Recent work has used generative models (GANs in particular) for providing high-fidelity simulation of real-world systems. However, such generative models are often monolithic and miss out on modeling the interaction in multi-agent systems. In this work, we take a first step towards building multiple interacting generative models (GANs) that reflects the interaction in real world. We build and analyze a hierarchical set-up where a higher-level GAN is conditioned on the output of multiple lower-level GANs. We present a technique of using feedback from the higher-level GAN to improve performance of lower-level GANs. We mathematically characterize the conditions under which our technique is impactful, including understanding the transfer learning nature of our set-up. We present three distinct experiments on synthetic data, time series data, and image domain, revealing the wide applicability of our technique.
Conditional Expectation based Value Decomposition for Scalable On-Demand Ride Pooling
Dec 01, 2021


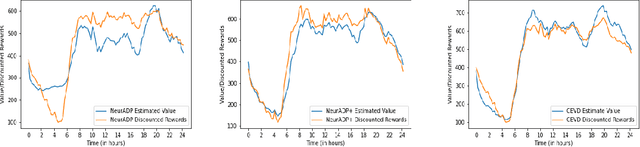
Owing to the benefits for customers (lower prices), drivers (higher revenues), aggregation companies (higher revenues) and the environment (fewer vehicles), on-demand ride pooling (e.g., Uber pool, Grab Share) has become quite popular. The significant computational complexity of matching vehicles to combinations of requests has meant that traditional ride pooling approaches are myopic in that they do not consider the impact of current matches on future value for vehicles/drivers. Recently, Neural Approximate Dynamic Programming (NeurADP) has employed value decomposition with Approximate Dynamic Programming (ADP) to outperform leading approaches by considering the impact of an individual agent's (vehicle) chosen actions on the future value of that agent. However, in order to ensure scalability and facilitate city-scale ride pooling, NeurADP completely ignores the impact of other agents actions on individual agent/vehicle value. As demonstrated in our experimental results, ignoring the impact of other agents actions on individual value can have a significant impact on the overall performance when there is increased competition among vehicles for demand. Our key contribution is a novel mechanism based on computing conditional expectations through joint conditional probabilities for capturing dependencies on other agents actions without increasing the complexity of training or decision making. We show that our new approach, Conditional Expectation based Value Decomposition (CEVD) outperforms NeurADP by up to 9.76% in terms of overall requests served, which is a significant improvement on a city wide benchmark taxi dataset.
Changepoint Analysis of Topic Proportions in Temporal Text Data
Nov 29, 2021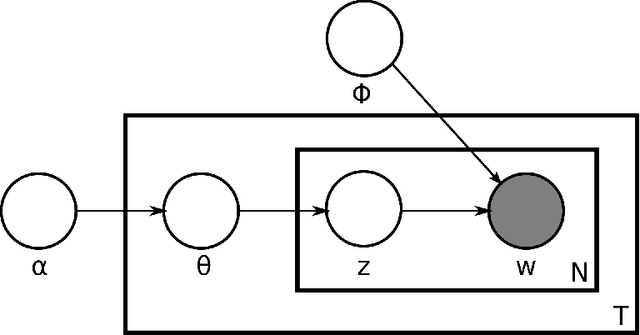
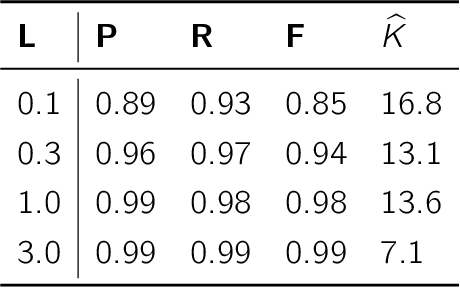
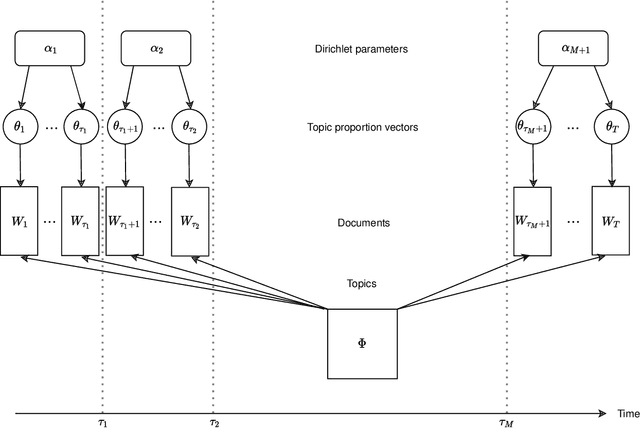
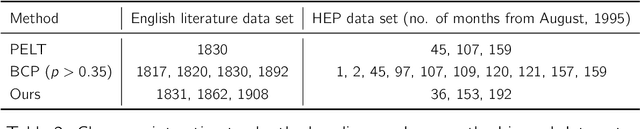
Changepoint analysis deals with unsupervised detection and/or estimation of time-points in time-series data, when the distribution generating the data changes. In this article, we consider \emph{offline} changepoint detection in the context of large scale textual data. We build a specialised temporal topic model with provisions for changepoints in the distribution of topic proportions. As full likelihood based inference in this model is computationally intractable, we develop a computationally tractable approximate inference procedure. More specifically, we use sample splitting to estimate topic polytopes first and then apply a likelihood ratio statistic together with a modified version of the wild binary segmentation algorithm of Fryzlewicz et al. (2014). Our methodology facilitates automated detection of structural changes in large corpora without the need of manual processing by domain experts. As changepoints under our model correspond to changes in topic structure, the estimated changepoints are often highly interpretable as marking the surge or decline in popularity of a fashionable topic. We apply our procedure on two large datasets: (i) a corpus of English literature from the period 1800-1922 (Underwoodet al., 2015); (ii) abstracts from the High Energy Physics arXiv repository (Clementet al., 2019). We obtain some historically well-known changepoints and discover some new ones.