 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHey Chat, Can You Teach Me? Structuring Socratic Dialogue for Human Learning in the Wild
Jun 10, 2026Large language models are now widely used for everyday learning, but the underlying interactions are typically unstructured chats rather than following a curriculum. Unlike formal online learning systems, these interactions carry no prior record of the student, so any estimate of what the student already knows must be inferred from the dialogue itself. We show that this gap is not closed by scaling models alone. Frontier and education-tuned LLMs perform poorly when asked to tutor a student over an extended session, because doing so requires three things at once. The tutor must sequence a curriculum, conduct Socratic dialogue, and infer the student's knowledge state from that dialogue. We propose separating these responsibilities. Given a student query, our system constructs a prerequisite knowledge graph in which subtopics are nodes and dependencies are edges, and frames tutoring as deciding which node to teach next and how many dialogue turns to spend on it before moving on. A lightweight PPO policy handles this sequencing decision, while an LLM conducts the Socratic exchange at the chosen node and returns a signal of student progress. Across held-out STEM and non-STEM topics, our PPO-paired tutor outperforms heuristic baselines, frontier general-purpose models, and a model specialised for Socratic dialogue: on both the rate at which students reach full curriculum mastery and the number of turns required. Explicit curriculum structure delivers gains that scaling the underlying model does not.
Induced Numerical Instability: Hidden Costs in Multimodal Large Language Models
Feb 27, 2026The use of multimodal large language models has become widespread, and as such the study of these models and their failure points has become of utmost importance. We study a novel mode of failure that causes degradation in performance indirectly by optimizing a loss term that seeks to maximize numerical instability in the inference stage of these models. We apply this loss term as the optimization target to construct images that, when used on multimodal large language models, cause significant degradation in the output. We validate our hypothesis on state of the art models large vision language models (LLaVa-v1.5-7B, Idefics3-8B, SmolVLM-2B-Instruct) against standard datasets (Flickr30k, MMVet, TextVQA, VQAv2, POPE, COCO) and show that performance degrades significantly, even with a very small change to the input image, compared to baselines. Our results uncover a fundamentally different vector of performance degradation, highlighting a failure mode not captured by adversarial perturbations.
Strategic Incentivization for Locally Differentially Private Federated Learning
Aug 10, 2025In Federated Learning (FL), multiple clients jointly train a machine learning model by sharing gradient information, instead of raw data, with a server over multiple rounds. To address the possibility of information leakage in spite of sharing only the gradients, Local Differential Privacy (LDP) is often used. In LDP, clients add a selective amount of noise to the gradients before sending the same to the server. Although such noise addition protects the privacy of clients, it leads to a degradation in global model accuracy. In this paper, we model this privacy-accuracy trade-off as a game, where the sever incentivizes the clients to add a lower degree of noise for achieving higher accuracy, while the clients attempt to preserve their privacy at the cost of a potential loss in accuracy. A token based incentivization mechanism is introduced in which the quantum of tokens credited to a client in an FL round is a function of the degree of perturbation of its gradients. The client can later access a newly updated global model only after acquiring enough tokens, which are to be deducted from its balance. We identify the players, their actions and payoff, and perform a strategic analysis of the game. Extensive experiments were carried out to study the impact of different parameters.
Temporal Robustness in Discrete Time Linear Dynamical Systems
May 05, 2025Discrete time linear dynamical systems, including Markov chains, have found many applications. However, in some problems, there is uncertainty about the time horizon for which the system runs. This creates uncertainty about the cost (or reward) incurred based on the state distribution when the system stops. Given past data samples of how long a system ran, we propose to theoretically analyze a distributional robust cost estimation task in a Wasserstein ambiguity set, instead of learning a probability distribution from a few samples. Towards this, we show an equivalence between a discrete time Markov Chain on a probability simplex and a global asymptotic stable (GAS) discrete time linear dynamical system, allowing us to base our study on a GAS system only. Then, we provide various polynomial time algorithms and hardness results for different cases in our theoretical study, including a fundamental result about Wasserstein distance based polytope.
On Learning Informative Trajectory Embeddings for Imitation, Classification and Regression
Jan 16, 2025



In real-world sequential decision making tasks like autonomous driving, robotics, and healthcare, learning from observed state-action trajectories is critical for tasks like imitation, classification, and clustering. For example, self-driving cars must replicate human driving behaviors, while robots and healthcare systems benefit from modeling decision sequences, whether or not they come from expert data. Existing trajectory encoding methods often focus on specific tasks or rely on reward signals, limiting their ability to generalize across domains and tasks. Inspired by the success of embedding models like CLIP and BERT in static domains, we propose a novel method for embedding state-action trajectories into a latent space that captures the skills and competencies in the dynamic underlying decision-making processes. This method operates without the need for reward labels, enabling better generalization across diverse domains and tasks. Our contributions are threefold: (1) We introduce a trajectory embedding approach that captures multiple abilities from state-action data. (2) The learned embeddings exhibit strong representational power across downstream tasks, including imitation, classification, clustering, and regression. (3) The embeddings demonstrate unique properties, such as controlling agent behaviors in IQ-Learn and an additive structure in the latent space. Experimental results confirm that our method outperforms traditional approaches, offering more flexible and powerful trajectory representations for various applications. Our code is available at https://github.com/Erasmo1015/vte.
Semantic loss guided data efficient supervised fine tuning for Safe Responses in LLMs
Dec 07, 2024



Large Language Models (LLMs) generating unsafe responses to toxic prompts is a significant issue in their applications. While various efforts aim to address this safety concern, previous approaches often demand substantial human data collection or rely on the less dependable option of using another LLM to generate corrective data. In this paper, we aim to take this problem and overcome limitations of requiring significant high-quality human data. Our method requires only a small set of unsafe responses to toxic prompts, easily obtained from the unsafe LLM itself. By employing a semantic cost combined with a negative Earth Mover Distance (EMD) loss, we guide the LLM away from generating unsafe responses. Additionally, we propose a novel lower bound for EMD loss, enabling more efficient optimization. Our results demonstrate superior performance and data efficiency compared to baselines, and we further examine the nuanced effects of over-alignment and potential degradation of language capabilities when using contrastive data.
Heterogeneous Graph Generation: A Hierarchical Approach using Node Feature Pooling
Oct 15, 2024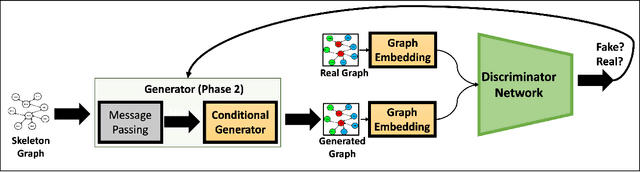
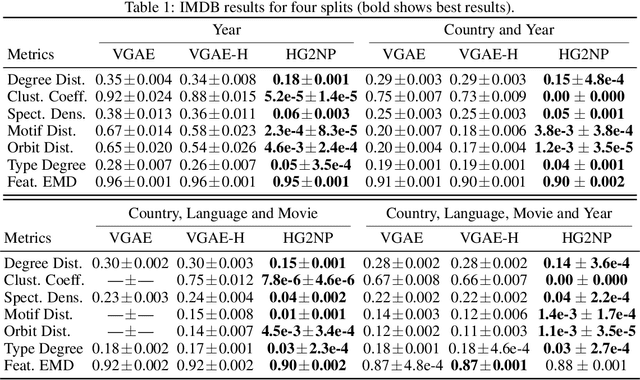
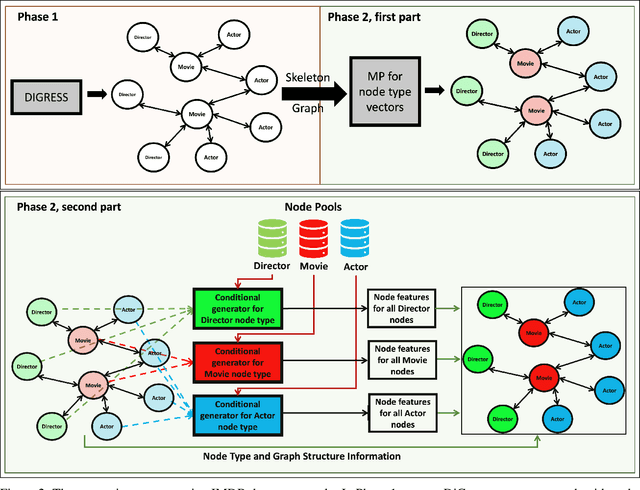
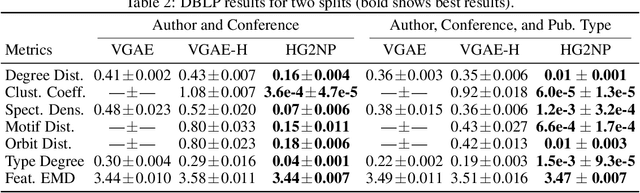
Heterogeneous graphs are present in various domains, such as social networks, recommendation systems, and biological networks. Unlike homogeneous graphs, heterogeneous graphs consist of multiple types of nodes and edges, each representing different entities and relationships. Generating realistic heterogeneous graphs that capture the complex interactions among diverse entities is a difficult task due to several reasons. The generator has to model both the node type distribution along with the feature distribution for each node type. In this paper, we look into solving challenges in heterogeneous graph generation, by employing a two phase hierarchical structure, wherein the first phase creates a skeleton graph with node types using a prior diffusion based model and in the second phase, we use an encoder and a sampler structure as generator to assign node type specific features to the nodes. A discriminator is used to guide training of the generator and feature vectors are sampled from a node feature pool. We conduct extensive experiments with subsets of IMDB and DBLP datasets to show the effectiveness of our method and also the need for various architecture components.
Towards Neural Network based Cognitive Models of Dynamic Decision-Making by Humans
Jul 24, 2024



Modelling human cognitive processes in dynamic decision-making tasks has been an endeavor in AI for a long time. Some initial works have attempted to utilize neural networks (and large language models) but often assume one common model for all humans and aim to emulate human behavior in aggregate. However, behavior of each human is distinct, heterogeneous and relies on specific past experiences in specific tasks. To that end, we build on a well known model of cognition, namely Instance Based Learning (IBL), that posits that decisions are made based on similar situations encountered in the past. We propose two new attention based neural network models to model human decision-making in dynamic settings. We experiment with two distinct datasets gathered from human subject experiment data, one focusing on detection of phishing email by humans and another where humans act as attackers in a cybersecurity setting and decide on an attack option. We conduct extensive experiments with our two neural network models, IBL, and GPT3.5, and demonstrate that one of our neural network models achieves the best performance in representing human decision-making. We find an interesting trend that all models predict a human's decision better if that human is better at the task. We also explore explanation of human decisions based on what our model considers important in prediction. Overall, our work yields promising results for further use of neural networks in cognitive modelling of human decision making. Our code is available at https://github.com/shshnkreddy/NCM-HDM.
Bootstrapping Language Models with DPO Implicit Rewards
Jun 14, 2024



Human alignment in large language models (LLMs) is an active area of research. A recent groundbreaking work, direct preference optimization (DPO), has greatly simplified the process from past work in reinforcement learning from human feedback (RLHF) by bypassing the reward learning stage in RLHF. DPO, after training, provides an implicit reward model. In this work, we make a novel observation that this implicit reward model can by itself be used in a bootstrapping fashion to further align the LLM. Our approach is to use the rewards from a current LLM model to construct a preference dataset, which is then used in subsequent DPO rounds. We incorporate refinements that debias the length of the responses and improve the quality of the preference dataset to further improve our approach. Our approach, named self-alignment with DPO ImpliCit rEwards (DICE), shows great improvements in alignment and achieves superior performance than Gemini Pro on AlpacaEval 2, reaching 27.55% length-controlled win rate against GPT-4 Turbo, but with only 8B parameters and no external feedback. Our code is available at https://github.com/sail-sg/dice.
Probabilistic Perspectives on Error Minimization in Adversarial Reinforcement Learning
Jun 07, 2024



Deep Reinforcement Learning (DRL) policies are critically vulnerable to adversarial noise in observations, posing severe risks in safety-critical scenarios. For example, a self-driving car receiving manipulated sensory inputs about traffic signs could lead to catastrophic outcomes. Existing strategies to fortify RL algorithms against such adversarial perturbations generally fall into two categories: (a) using regularization methods that enhance robustness by incorporating adversarial loss terms into the value objectives, and (b) adopting "maximin" principles, which focus on maximizing the minimum value to ensure robustness. While regularization methods reduce the likelihood of successful attacks, their effectiveness drops significantly if an attack does succeed. On the other hand, maximin objectives, although robust, tend to be overly conservative. To address this challenge, we introduce a novel objective called Adversarial Counterfactual Error (ACoE), which naturally balances optimizing value and robustness against adversarial attacks. To optimize ACoE in a scalable manner in model-free settings, we propose a theoretically justified surrogate objective known as Cumulative-ACoE (C-ACoE). The core idea of optimizing C-ACoE is utilizing the belief about the underlying true state given the adversarially perturbed observation. Our empirical evaluations demonstrate that our method outperforms current state-of-the-art approaches for addressing adversarial RL problems across all established benchmarks (MuJoCo, Atari, and Highway) used in the literature.