 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your Data! Hiding Backdoors in Offline Reinforcement Learning Datasets
Paper and Code
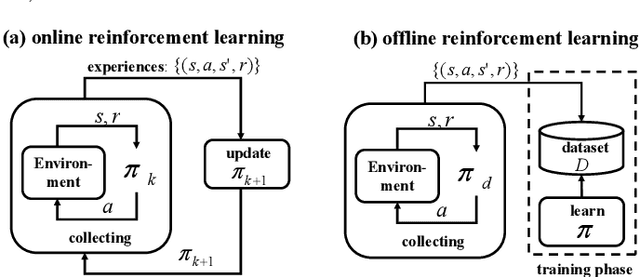

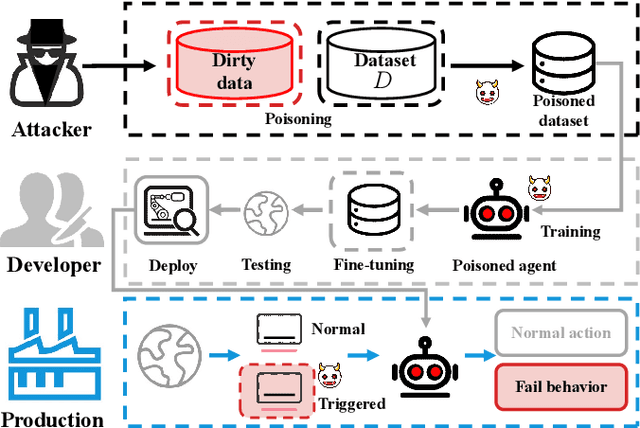
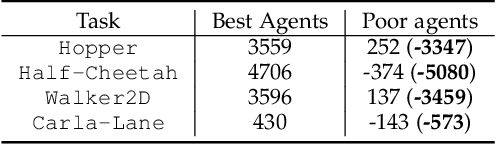
A growing body of research works has focused on the Offline Reinforcement Learning (RL) paradigm. Data providers share large pre-collected datasets on which others can train high-quality agents without interacting with the environments. Such an offline RL paradigm has demonstrated effectiveness in many critical tasks, including robot control, autonomous driving, etc. A well-trained agent can be regarded as a software system. However, less attention is paid to investigating the security threats to the offline RL system. In this paper, we focus on a critical security threat: backdoor attacks. Given normal observations, an agent implanted with backdoors takes actions leading to high rewards. However, the same agent takes actions that lead to low rewards if the observations are injected with triggers that can activate the backdoor. In this paper, we propose Baffle (Backdoor Attack for Offline Reinforcement Learning) and evaluate how different Offline RL algorithms react to this attack. Our experiments conducted on four tasks and four offline RL algorithms expose a disquieting fact: none of the existing offline RL algorithms is immune to such a backdoor attack. More specifically, Baffle modifies $10\%$ of the datasets for four tasks (3 robotic controls and 1 autonomous driving). Agents trained on the poisoned datasets perform well in normal settings. However, when triggers are presented, the agents' performance decreases drastically by $63.6\%$, $57.8\%$, $60.8\%$ and $44.7\%$ in the four tasks on average. The backdoor still persists after fine-tuning poisoned agents on clean datasets. We further show that the inserted backdoor is also hard to be detected by a popular defensive method. This paper calls attention to developing more effective protection for the open-source offline RL dataset.