 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessLeak-Bench: A First Investigation of Data Leakage in LLMs Across 83 Software Engineering Benchmarks
Feb 10, 2025
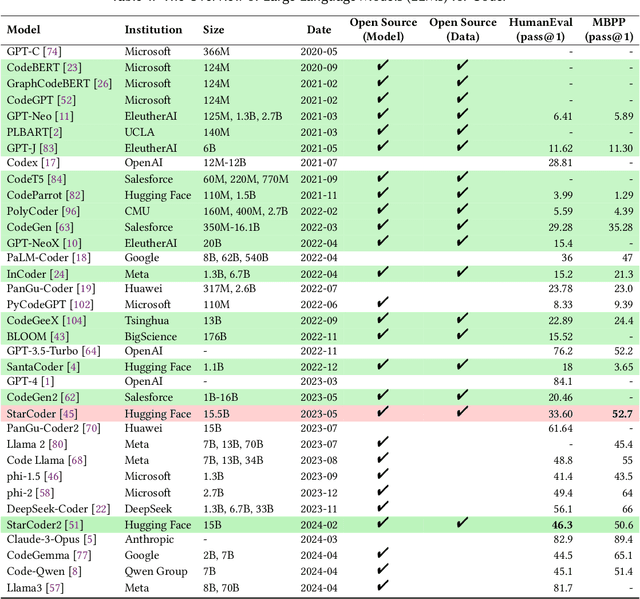

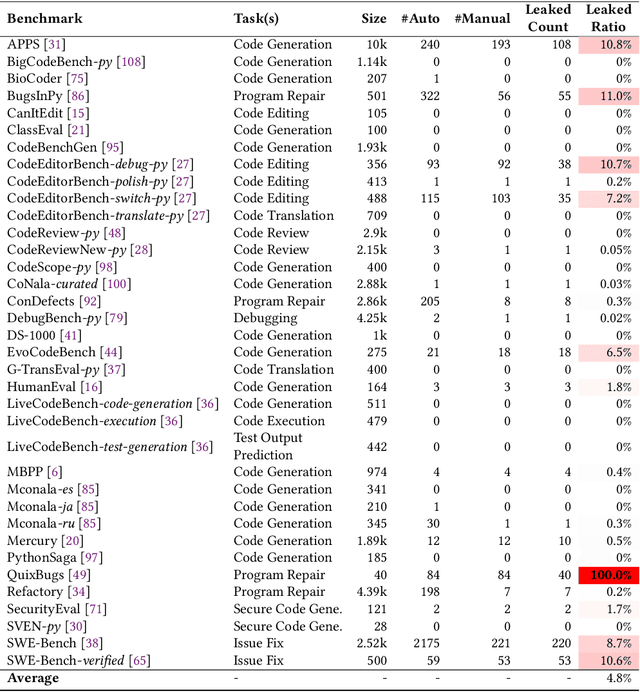
Large Language Models (LLMs) are widely utilized in software engineering (SE) tasks, such as code generation and automated program repair. However, their reliance on extensive and often undisclosed pre-training datasets raises significant concerns about data leakage, where the evaluation benchmark data is unintentionally ``seen'' by LLMs during the model's construction phase. The data leakage issue could largely undermine the validity of LLM-based research and evaluations. Despite the increasing use of LLMs in the SE community, there is no comprehensive study that assesses the extent of data leakage in SE benchmarks for LLMs yet. To address this gap, this paper presents the first large-scale analysis of data leakage in 83 SE benchmarks concerning LLMs. Our results show that in general, data leakage in SE benchmarks is minimal, with average leakage ratios of only 4.8\%, 2.8\%, and 0.7\% for Python, Java, and C/C++ benchmarks, respectively. However, some benchmarks exhibit relatively higher leakage ratios, which raises concerns about their bias in evaluation. For instance, QuixBugs and BigCloneBench have leakage ratios of 100.0\% and 55.7\%, respectively. Furthermore, we observe that data leakage has a substantial impact on LLM evaluation. We also identify key causes of high data leakage, such as the direct inclusion of benchmark data in pre-training datasets and the use of coding platforms like LeetCode for benchmark construction. To address the data leakage, we introduce \textbf{LessLeak-Bench}, a new benchmark that removes leaked samples from the 83 SE benchmarks, enabling more reliable LLM evaluations in future research. Our study enhances the understanding of data leakage in SE benchmarks and provides valuable insights for future research involving LLMs in SE.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
Mind Your Data! Hiding Backdoors in Offline Reinforcement Learning Datasets
Oct 07, 2022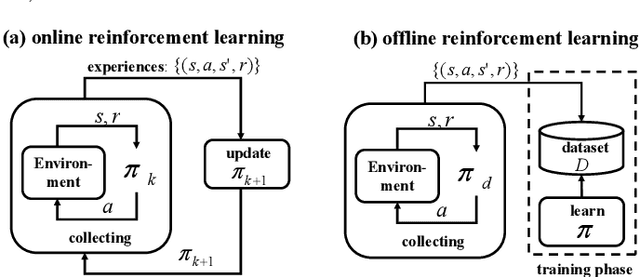

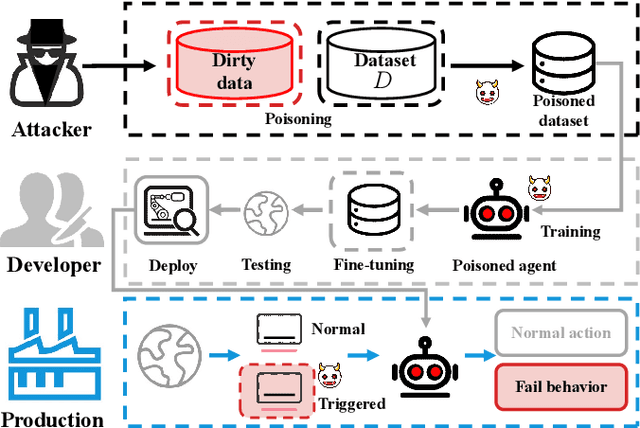
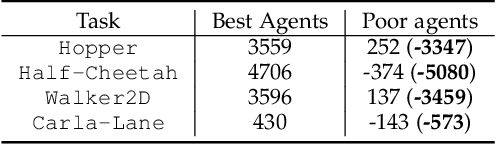
A growing body of research works has focused on the Offline Reinforcement Learning (RL) paradigm. Data providers share large pre-collected datasets on which others can train high-quality agents without interacting with the environments. Such an offline RL paradigm has demonstrated effectiveness in many critical tasks, including robot control, autonomous driving, etc. A well-trained agent can be regarded as a software system. However, less attention is paid to investigating the security threats to the offline RL system. In this paper, we focus on a critical security threat: backdoor attacks. Given normal observations, an agent implanted with backdoors takes actions leading to high rewards. However, the same agent takes actions that lead to low rewards if the observations are injected with triggers that can activate the backdoor. In this paper, we propose Baffle (Backdoor Attack for Offline Reinforcement Learning) and evaluate how different Offline RL algorithms react to this attack. Our experiments conducted on four tasks and four offline RL algorithms expose a disquieting fact: none of the existing offline RL algorithms is immune to such a backdoor attack. More specifically, Baffle modifies $10\%$ of the datasets for four tasks (3 robotic controls and 1 autonomous driving). Agents trained on the poisoned datasets perform well in normal settings. However, when triggers are presented, the agents' performance decreases drastically by $63.6\%$, $57.8\%$, $60.8\%$ and $44.7\%$ in the four tasks on average. The backdoor still persists after fine-tuning poisoned agents on clean datasets. We further show that the inserted backdoor is also hard to be detected by a popular defensive method. This paper calls attention to developing more effective protection for the open-source offline RL dataset.