 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LLM-as-Judge Metric for Bridging the Gap with Human Evaluation in SE Tasks
May 27, 2025



Large Language Models (LLMs) and other automated techniques have been increasingly used to support software developers by generating software artifacts such as code snippets, patches, and comments. However, accurately assessing the correctness of these generated artifacts remains a significant challenge. On one hand, human evaluation provides high accuracy but is labor-intensive and lacks scalability. On the other hand, other existing automatic evaluation metrics are scalable and require minimal human effort, but they often fail to accurately reflect the actual correctness of generated software artifacts. In this paper, we present SWE-Judge, the first evaluation metric for LLM-as-Ensemble-Judge specifically designed to accurately assess the correctness of generated software artifacts. SWE-Judge first defines five distinct evaluation strategies, each implemented as an independent judge. A dynamic team selection mechanism then identifies the most appropriate subset of judges to produce a final correctness score through ensembling. We evaluate SWE-Judge across a diverse set of software engineering (SE) benchmarks, including CoNaLa, Card2Code, HumanEval-X, APPS, APR-Assess, and Summary-Assess. These benchmarks span three SE tasks: code generation, automated program repair, and code summarization. Experimental results demonstrate that SWE-Judge consistently achieves a higher correlation with human judgments, with improvements ranging from 5.9% to 183.8% over existing automatic metrics. Furthermore, SWE-Judge reaches agreement levels with human annotators that are comparable to inter-annotator agreement in code generation and program repair tasks. These findings underscore SWE-Judge's potential as a scalable and reliable alternative to human evaluation.
Let the Trial Begin: A Mock-Court Approach to Vulnerability Detection using LLM-Based Agents
May 16, 2025



Detecting vulnerabilities in source code remains a critical yet challenging task, especially when benign and vulnerable functions share significant similarities. In this work, we introduce VulTrial, a courtroom-inspired multi-agent framework designed to enhance automated vulnerability detection. It employs four role-specific agents, which are security researcher, code author, moderator, and review board. Through extensive experiments using GPT-3.5 and GPT-4o we demonstrate that Vultrial outperforms single-agent and multi-agent baselines. Using GPT-4o, VulTrial improves the performance by 102.39% and 84.17% over its respective baseline. Additionally, we show that role-specific instruction tuning in multi-agent with small data (50 pair samples) improves the performance of VulTrial further by 139.89% and 118.30%. Furthermore, we analyze the impact of increasing the number of agent interactions on VulTrial's overall performance. While multi-agent setups inherently incur higher costs due to increased token usage, our findings reveal that applying VulTrial to a cost-effective model like GPT-3.5 can improve its performance by 69.89% compared to GPT-4o in a single-agent setting, at a lower overall cost.
R2Vul: Learning to Reason about Software Vulnerabilities with Reinforcement Learning and Structured Reasoning Distillation
Apr 07, 2025


Large language models (LLMs) have shown promising performance in software vulnerability detection (SVD), yet their reasoning capabilities remain unreliable. Existing approaches relying on chain-of-thought (CoT) struggle to provide relevant and actionable security assessments. Additionally, effective SVD requires not only generating coherent reasoning but also differentiating between well-founded and misleading yet plausible security assessments, an aspect overlooked in prior work. To this end, we introduce R2Vul, a novel approach that distills structured reasoning into small LLMs using reinforcement learning from AI feedback (RLAIF). Through RLAIF, R2Vul enables LLMs to produce structured, security-aware reasoning that is actionable and reliable while explicitly learning to distinguish valid assessments from misleading ones. We evaluate R2Vul across five languages against SAST tools, CoT, instruction tuning, and classification-based baselines. Our results show that R2Vul with structured reasoning distillation enables a 1.5B student LLM to rival larger models while improving generalization to out-of-distribution vulnerabilities. Beyond model improvements, we contribute a large-scale, multilingual preference dataset featuring structured reasoning to support future research in SVD.
LessLeak-Bench: A First Investigation of Data Leakage in LLMs Across 83 Software Engineering Benchmarks
Feb 10, 2025
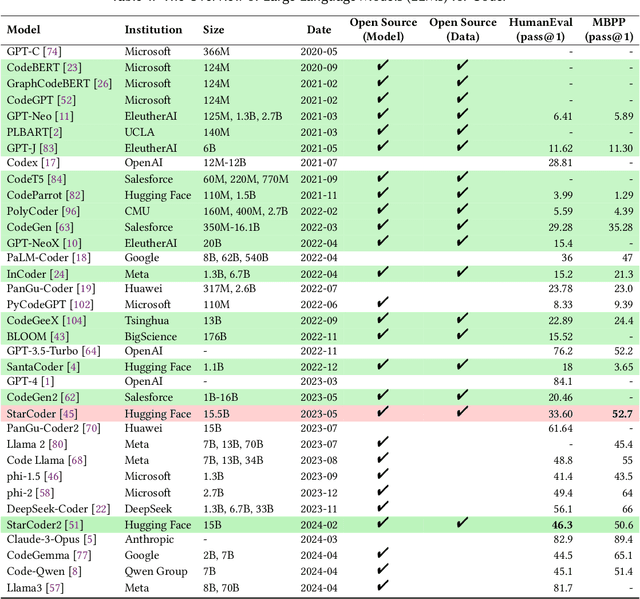

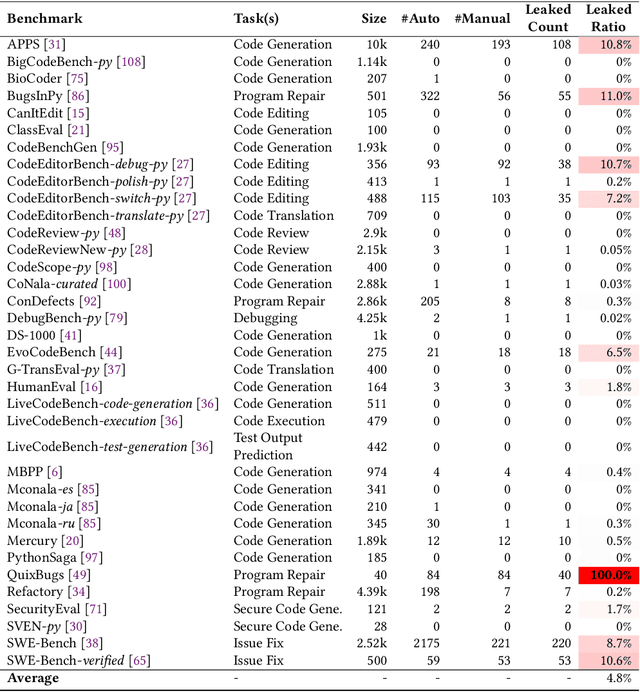
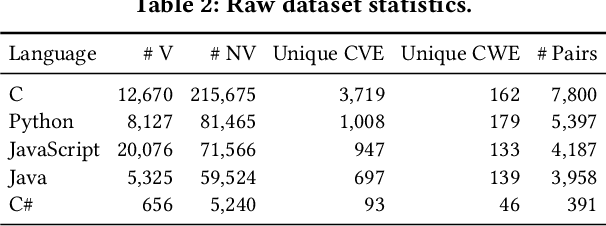
Large Language Models (LLMs) are widely utilized in software engineering (SE) tasks, such as code generation and automated program repair. However, their reliance on extensive and often undisclosed pre-training datasets raises significant concerns about data leakage, where the evaluation benchmark data is unintentionally ``seen'' by LLMs during the model's construction phase. The data leakage issue could largely undermine the validity of LLM-based research and evaluations. Despite the increasing use of LLMs in the SE community, there is no comprehensive study that assesses the extent of data leakage in SE benchmarks for LLMs yet. To address this gap, this paper presents the first large-scale analysis of data leakage in 83 SE benchmarks concerning LLMs. Our results show that in general, data leakage in SE benchmarks is minimal, with average leakage ratios of only 4.8\%, 2.8\%, and 0.7\% for Python, Java, and C/C++ benchmarks, respectively. However, some benchmarks exhibit relatively higher leakage ratios, which raises concerns about their bias in evaluation. For instance, QuixBugs and BigCloneBench have leakage ratios of 100.0\% and 55.7\%, respectively. Furthermore, we observe that data leakage has a substantial impact on LLM evaluation. We also identify key causes of high data leakage, such as the direct inclusion of benchmark data in pre-training datasets and the use of coding platforms like LeetCode for benchmark construction. To address the data leakage, we introduce \textbf{LessLeak-Bench}, a new benchmark that removes leaked samples from the 83 SE benchmarks, enabling more reliable LLM evaluations in future research. Our study enhances the understanding of data leakage in SE benchmarks and provides valuable insights for future research involving LLMs in SE.
CodeUltraFeedback: An LLM-as-a-Judge Dataset for Aligning Large Language Models to Coding Preferences
Mar 14, 2024



Evaluating the alignment of large language models (LLMs) with user-defined coding preferences is a challenging endeavour that requires assessing intricate textual LLMs' outputs. By relying on automated metrics and static analysis tools, existing benchmarks fail to assess nuances in user instructions and LLM outputs, highlighting the need for large-scale datasets and benchmarks for LLM preference alignment. In this paper, we introduce CodeUltraFeedback, a preference dataset of 10,000 complex instructions to tune and align LLMs to coding preferences through AI feedback. We generate responses to the instructions using a pool of 14 diverse LLMs, which we then annotate according to their alignment with five coding preferences using the LLM-as-a-Judge approach with GPT-3.5, producing both numerical and textual feedback. We also present CODAL-Bench, a benchmark for assessing LLM alignment with these coding preferences. Our results show that CodeLlama-7B-Instruct, aligned through reinforcement learning from AI feedback (RLAIF) with direct preference optimization (DPO) using CodeUltraFeedback's AI feedback data, outperforms 34B LLMs on CODAL-Bench, validating the utility of CodeUltraFeedback for preference tuning. Furthermore, we show our DPO-aligned CodeLlama model improves functional correctness on HumanEval+ compared to the unaligned base model. Therefore, our contributions bridge the gap in preference tuning of LLMs for code and set the stage for further advancements in model alignment and RLAIF for code intelligence. Our code and data are available at https://github.com/martin-wey/CodeUltraFeedback.
CodeLL: A Lifelong Learning Dataset to Support the Co-Evolution of Data and Language Models of Code
Dec 20, 2023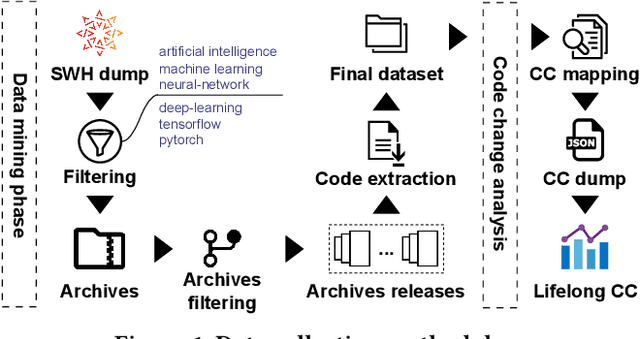
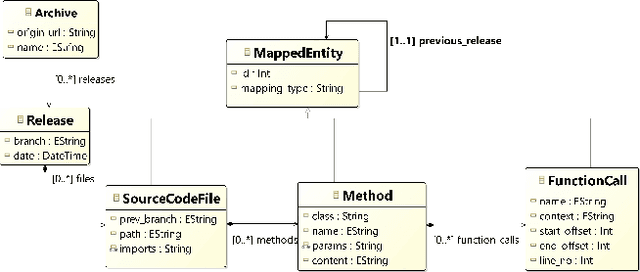
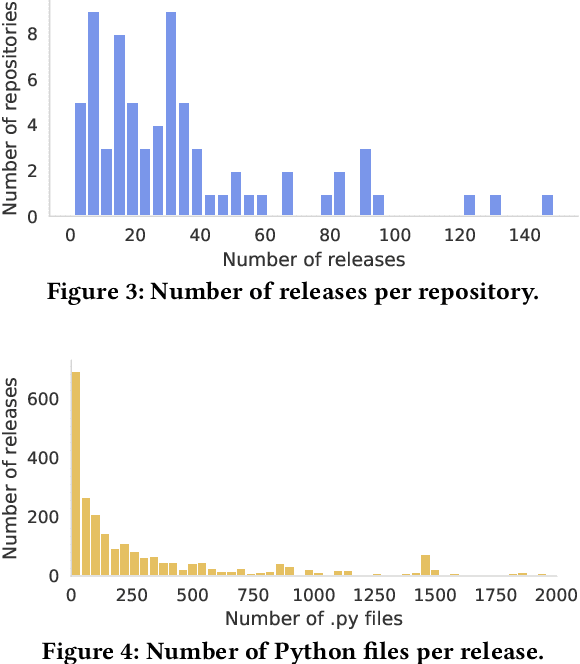
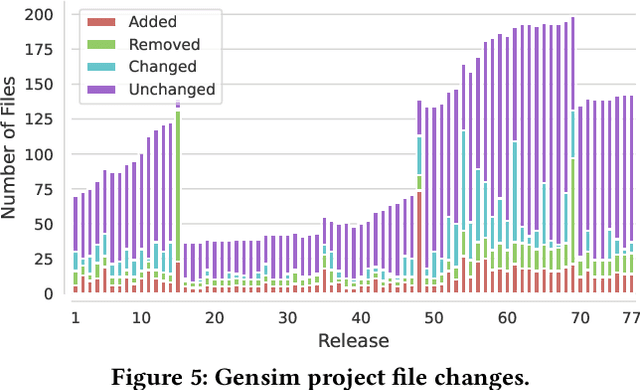
Motivated by recent work on lifelong learning applications for language models (LMs) of code, we introduce CodeLL, a lifelong learning dataset focused on code changes. Our contribution addresses a notable research gap marked by the absence of a long-term temporal dimension in existing code change datasets, limiting their suitability in lifelong learning scenarios. In contrast, our dataset aims to comprehensively capture code changes across the entire release history of open-source software repositories. In this work, we introduce an initial version of CodeLL, comprising 71 machine-learning-based projects mined from Software Heritage. This dataset enables the extraction and in-depth analysis of code changes spanning 2,483 releases at both the method and API levels. CodeLL enables researchers studying the behaviour of LMs in lifelong fine-tuning settings for learning code changes. Additionally, the dataset can help studying data distribution shifts within software repositories and the evolution of API usages over time.
Exploring Parameter-Efficient Fine-Tuning Techniques for Code Generation with Large Language Models
Aug 21, 2023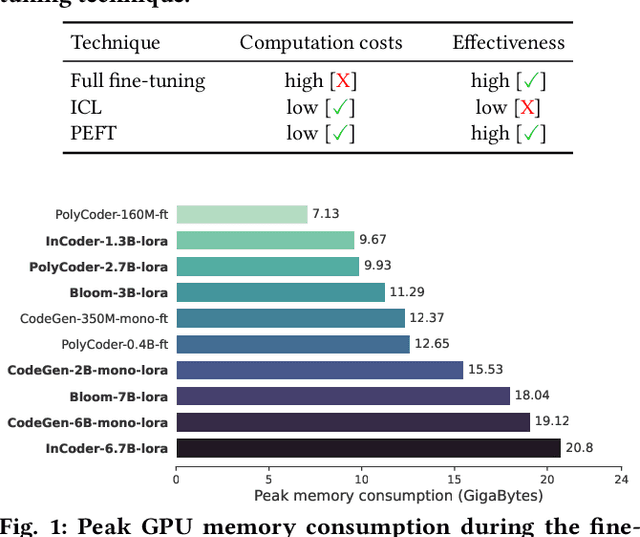


Large Language Models (LLMs) possess impressive capabilities to generate meaningful code snippets given natural language intents in zero-shot, i.e., without the need for specific fine-tuning. In the perspective of unleashing their full potential, prior work has demonstrated the benefits of fine-tuning the models to task-specific data. However, fine-tuning process demands heavy computational costs and is intractable when resources are scarce, especially for models with billions of parameters. In light of these challenges, previous studies explored In-Context Learning (ICL) as an effective strategy to generate contextually appropriate code without fine-tuning. However, it operates at inference time and does not involve learning task-specific parameters, potentially limiting the model's performance on downstream tasks. In this context, we foresee that Parameter-Efficient Fine-Tuning (PEFT) techniques carry a high potential for efficiently specializing LLMs to task-specific data. In this paper, we deliver a comprehensive study of LLMs with the impact of PEFT techniques under the automated code generation scenario. Our experimental results reveal the superiority and potential of such techniques over ICL on a wide range of LLMs in reducing the computational burden and improving performance. Therefore, the study opens opportunities for broader applications of PEFT in software engineering scenarios.
On the Usage of Continual Learning for Out-of-Distribution Generalization in Pre-trained Language Models of Code
May 06, 2023



Pre-trained language models (PLMs) have become a prevalent technique in deep learning for code, utilizing a two-stage pre-training and fine-tuning procedure to acquire general knowledge about code and specialize in a variety of downstream tasks. However, the dynamic nature of software codebases poses a challenge to the effectiveness and robustness of PLMs. In particular, world-realistic scenarios potentially lead to significant differences between the distribution of the pre-training and test data, i.e., distribution shift, resulting in a degradation of the PLM's performance on downstream tasks. In this paper, we stress the need for adapting PLMs of code to software data whose distribution changes over time, a crucial problem that has been overlooked in previous works. The motivation of this work is to consider the PLM in a non-stationary environment, where fine-tuning data evolves over time according to a software evolution scenario. Specifically, we design a scenario where the model needs to learn from a stream of programs containing new, unseen APIs over time. We study two widely used PLM architectures, i.e., a GPT2 decoder and a RoBERTa encoder, on two downstream tasks, API call and API usage prediction. We demonstrate that the most commonly used fine-tuning technique from prior work is not robust enough to handle the dynamic nature of APIs, leading to the loss of previously acquired knowledge i.e., catastrophic forgetting. To address these issues, we implement five continual learning approaches, including replay-based and regularization-based methods. Our findings demonstrate that utilizing these straightforward methods effectively mitigates catastrophic forgetting in PLMs across both downstream tasks while achieving comparable or superior performance.
AST-Probe: Recovering abstract syntax trees from hidden representations of pre-trained language models
Jun 23, 2022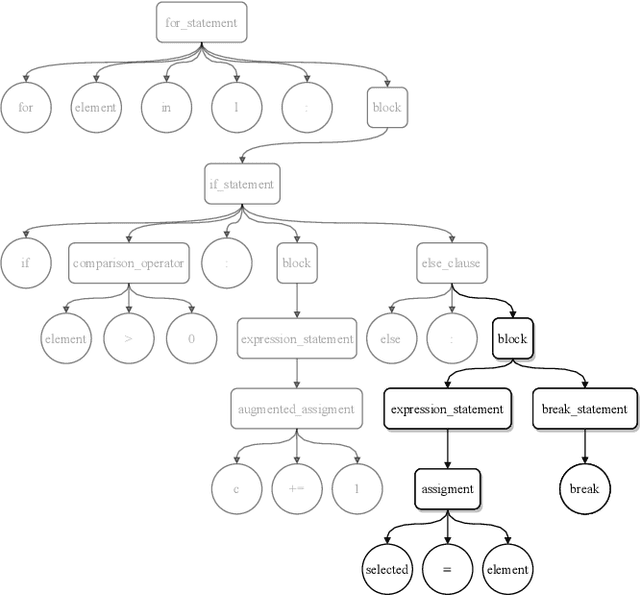
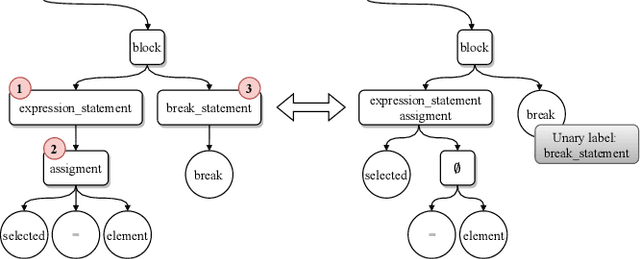
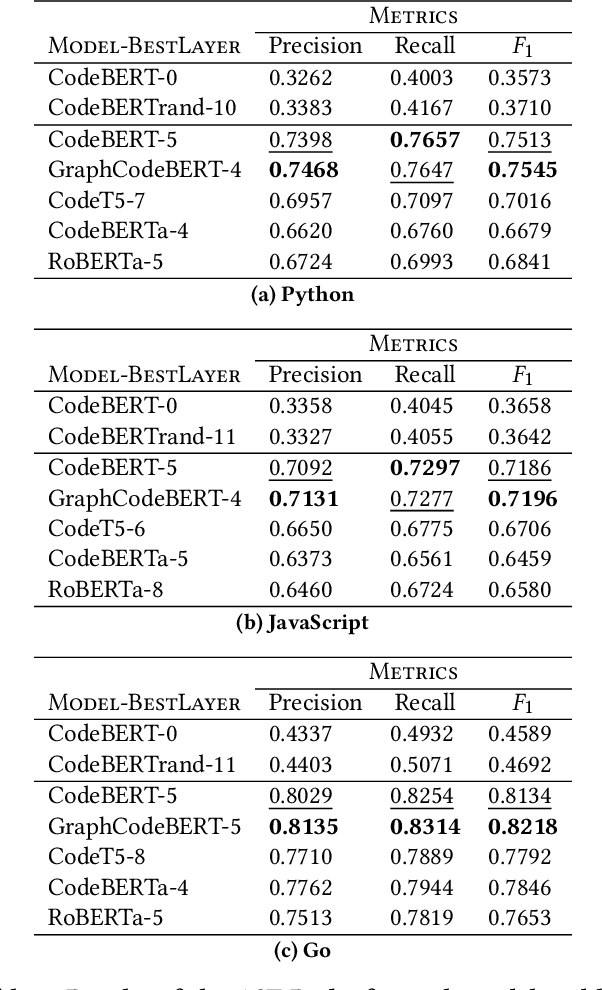
The objective of pre-trained language models is to learn contextual representations of textual data. Pre-trained language models have become mainstream in natural language processing and code modeling. Using probes, a technique to study the linguistic properties of hidden vector spaces, previous works have shown that these pre-trained language models encode simple linguistic properties in their hidden representations. However, none of the previous work assessed whether these models encode the whole grammatical structure of a programming language. In this paper, we prove the existence of a \textit{syntactic subspace}, lying in the hidden representations of pre-trained language models, which contain the syntactic information of the programming language. We show that this subspace can be extracted from the models' representations and define a novel probing method, the AST-Probe, that enables recovering the whole abstract syntax tree (AST) of an input code snippet. In our experimentations, we show that this syntactic subspace exists in five state-of-the-art pre-trained language models. In addition, we highlight that the middle layers of the models are the ones that encode most of the AST information. Finally, we estimate the optimal size of this syntactic subspace and show that its dimension is substantially lower than those of the models' representation spaces. This suggests that pre-trained language models use a small part of their representation spaces to encode syntactic information of the programming languages.
Better Modeling the Programming World with Code Concept Graphs-augmented Multi-modal Learning
Jan 10, 2022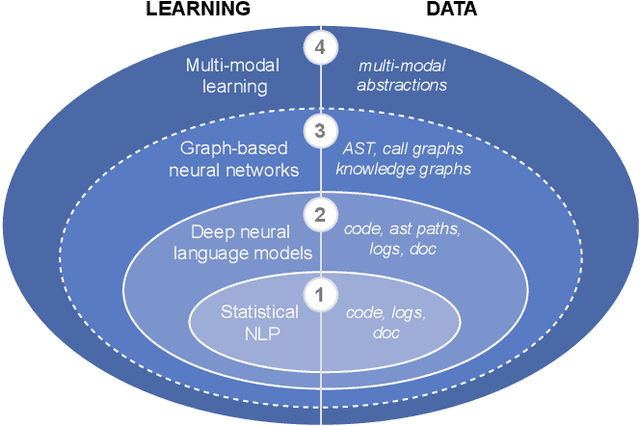
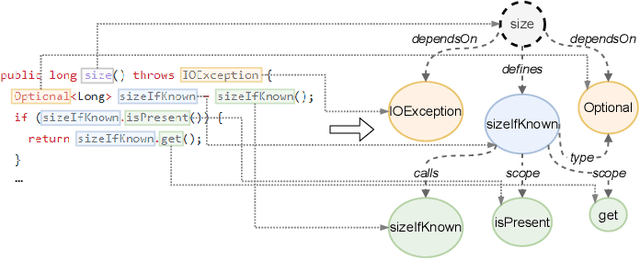
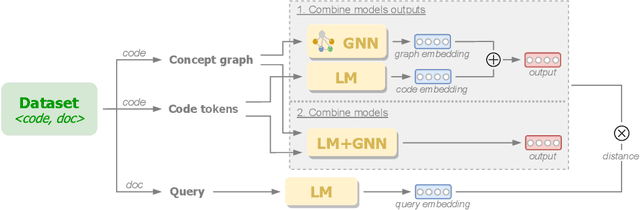
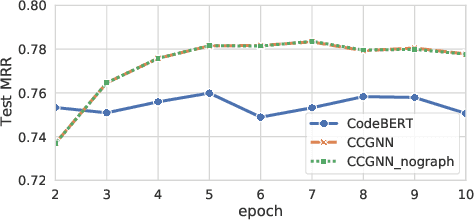
The progress made in code modeling has been tremendous in recent years thanks to the design of natural language processing learning approaches based on state-of-the-art model architectures. Nevertheless, we believe that the current state-of-the-art does not focus enough on the full potential that data may bring to a learning process in software engineering. Our vision articulates on the idea of leveraging multi-modal learning approaches to modeling the programming world. In this paper, we investigate one of the underlying idea of our vision whose objective based on concept graphs of identifiers aims at leveraging high-level relationships between domain concepts manipulated through particular language constructs. In particular, we propose to enhance an existing pretrained language model of code by joint-learning it with a graph neural network based on our concept graphs. We conducted a preliminary evaluation that shows gain of effectiveness of the models for code search using a simple joint-learning method and prompts us to further investigate our research vision.