 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeLL: A Lifelong Learning Dataset to Support the Co-Evolution of Data and Language Models of Code
Dec 20, 2023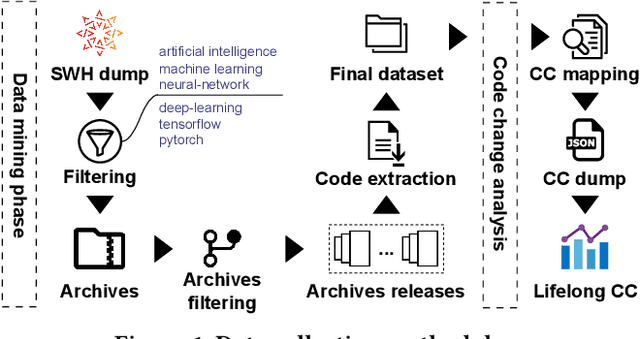
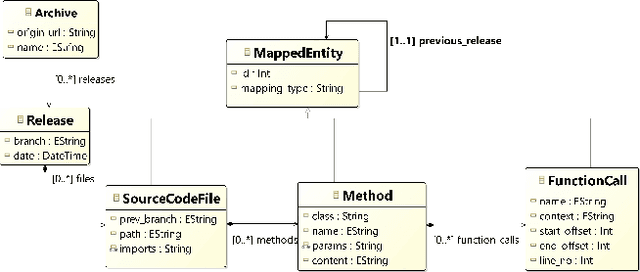
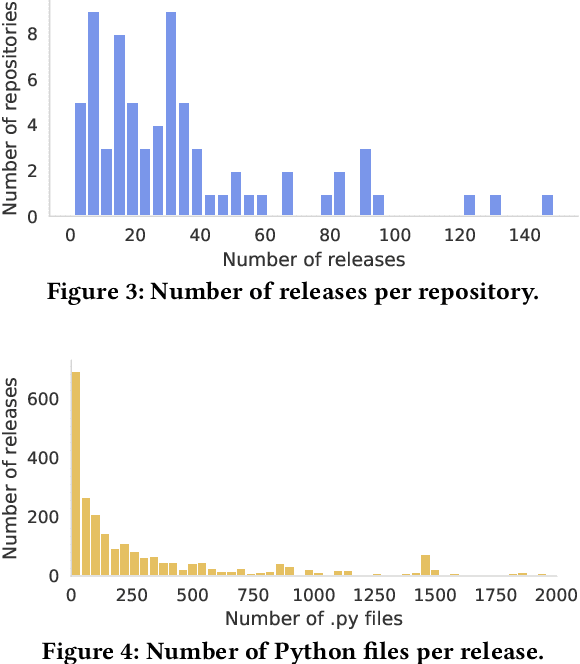
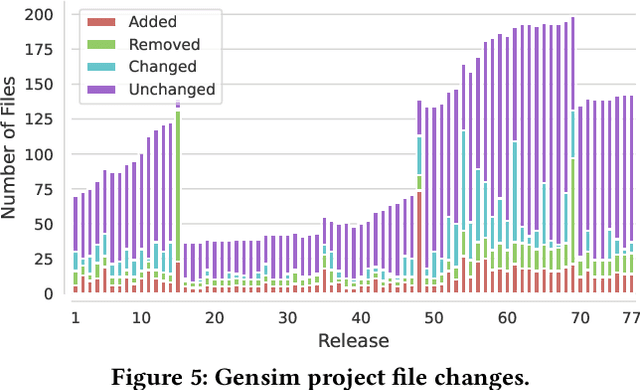
Motivated by recent work on lifelong learning applications for language models (LMs) of code, we introduce CodeLL, a lifelong learning dataset focused on code changes. Our contribution addresses a notable research gap marked by the absence of a long-term temporal dimension in existing code change datasets, limiting their suitability in lifelong learning scenarios. In contrast, our dataset aims to comprehensively capture code changes across the entire release history of open-source software repositories. In this work, we introduce an initial version of CodeLL, comprising 71 machine-learning-based projects mined from Software Heritage. This dataset enables the extraction and in-depth analysis of code changes spanning 2,483 releases at both the method and API levels. CodeLL enables researchers studying the behaviour of LMs in lifelong fine-tuning settings for learning code changes. Additionally, the dataset can help studying data distribution shifts within software repositories and the evolution of API usages over time.
GitRanking: A Ranking of GitHub Topics for Software Classification using Active Sampling
May 19, 2022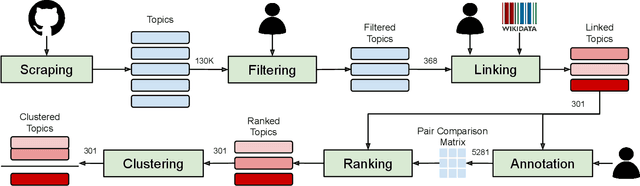
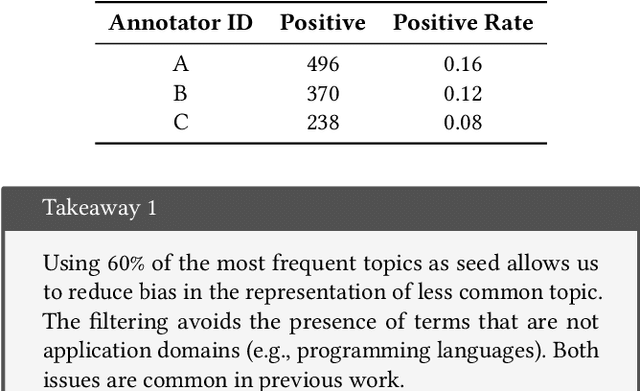


GitHub is the world's largest host of source code, with more than 150M repositories. However, most of these repositories are not labeled or inadequately so, making it harder for users to find relevant projects. There have been various proposals for software application domain classification over the past years. However, these approaches lack a well-defined taxonomy that is hierarchical, grounded in a knowledge base, and free of irrelevant terms. This work proposes GitRanking, a framework for creating a classification ranked into discrete levels based on how general or specific their meaning is. We collected 121K topics from GitHub and considered $60\%$ of the most frequent ones for the ranking. GitRanking 1) uses active sampling to ensure a minimal number of required annotations; and 2) links each topic to Wikidata, reducing ambiguities and improving the reusability of the taxonomy. Our results show that developers, when annotating their projects, avoid using terms with a high degree of specificity. This makes the finding and discovery of their projects more challenging for other users. Furthermore, we show that GitRanking can effectively rank terms according to their general or specific meaning. This ranking would be an essential asset for developers to build upon, allowing them to complement their annotations with more precise topics. Finally, we show that GitRanking is a dynamically extensible method: it can currently accept further terms to be ranked with a minimum number of annotations ($\sim$ 15). This paper is the first collective attempt to build a ground-up taxonomy of software domains.