 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Models for the Early Detection of Burnout in Software Engineering: a Systematic Literature Review
Mar 24, 2026Burnout is an occupational syndrome that, like many other professions, affects the majority of software engineers. Past research studies showed important trends, including an increasing use of machine learning techniques to allow for an early detection of burnout. This paper is a systematic literature review (SLR) of the research papers that proposed machine learning (ML) approaches, and focused on detecting burnout in software developers and IT professionals. Our objective is to review the accuracy and precision of the proposed ML techniques, and to formulate recommendations for future researchers interested to replicate or extend those studies. From our SLR we observed that a majority of primary studies focuses on detecting emotions or utilise emotional dimensions to detect or predict the presence of burnout. We also performed a cross-sectional study to detect which ML approach shows a better performance at detecting emotions; and which dataset has more potential and expressivity to capture emotions. We believe that, by identifying which ML tools and datasets show a better performance at detecting emotions, and indirectly at identifying burnout, our paper can be a valuable asset to progress in this important research direction.
Deep Learning and Data Augmentation for Detecting Self-Admitted Technical Debt
Oct 21, 2024Self-Admitted Technical Debt (SATD) refers to circumstances where developers use textual artifacts to explain why the existing implementation is not optimal. Past research in detecting SATD has focused on either identifying SATD (classifying SATD items as SATD or not) or categorizing SATD (labeling instances as SATD that pertain to requirement, design, code, test debt, etc.). However, the performance of these approaches remains suboptimal, particularly for specific types of SATD, such as test and requirement debt, primarily due to extremely imbalanced datasets. To address these challenges, we build on earlier research by utilizing BiLSTM architecture for the binary identification of SATD and BERT architecture for categorizing different types of SATD. Despite their effectiveness, both architectures struggle with imbalanced data. Therefore, we employ a large language model data augmentation strategy to mitigate this issue. Furthermore, we introduce a two-step approach to identify and categorize SATD across various datasets derived from different artifacts. Our contributions include providing a balanced dataset for future SATD researchers and demonstrating that our approach significantly improves SATD identification and categorization performance compared to baseline methods.
SATDAUG -- A Balanced and Augmented Dataset for Detecting Self-Admitted Technical Debt
Mar 12, 2024Self-admitted technical debt (SATD) refers to a form of technical debt in which developers explicitly acknowledge and document the existence of technical shortcuts, workarounds, or temporary solutions within the codebase. Over recent years, researchers have manually labeled datasets derived from various software development artifacts: source code comments, messages from the issue tracker and pull request sections, and commit messages. These datasets are designed for training, evaluation, performance validation, and improvement of machine learning and deep learning models to accurately identify SATD instances. However, class imbalance poses a serious challenge across all the existing datasets, particularly when researchers are interested in categorizing the specific types of SATD. In order to address the scarcity of labeled data for SATD \textit{identification} (i.e., whether an instance is SATD or not) and \textit{categorization} (i.e., which type of SATD is being classified) in existing datasets, we share the \textit{SATDAUG} dataset, an augmented version of existing SATD datasets, including source code comments, issue tracker, pull requests, and commit messages. These augmented datasets have been balanced in relation to the available artifacts and provide a much richer source of labeled data for training machine learning or deep learning models.
Detecting Technical Debt Using Natural Language Processing Approaches -- A Systematic Literature Review
Dec 19, 2023



Context: Technical debt (TD) is a well-known metaphor for the long-term effects of architectural decisions in software development and the trade-off between producing high-quality, effective, and efficient code and meeting a release schedule. Thus, the code degrades and needs refactoring. A lack of resources, time, knowledge, or experience on the development team might cause TD in any software development project. Objective: In the context of TD detection, NLP has been utilized to identify the presence of TD automatically and even recognize specific types of TD. However, the enormous variety of feature extraction approaches and ML/DL algorithms employed in the literature often hinders researchers from trying to improve their performance. Method: In light of this, this SLR proposes a taxonomy of feature extraction techniques and algorithms used in technical debt detection: its objective is to compare and benchmark their performance in the examined studies. Results: We selected 55 articles that passed the quality evaluation of this SLR. We then investigated which feature extractions and algorithms were employed to identify TD in each SDLC phase. All approaches proposed in the analyzed studies were grouped into NLP, NLP+ML, and NLP+DL. This allows us to discuss the performance in three different ways. Conclusion: Overall, the NLP+DL group consistently outperforms in precision and F1-score for all projects, and in all but one project for the recall metric. Regarding the feature extraction techniques, the PTWE consistently achieves higher precision, recall, and F1-score for each project analyzed. Furthermore, TD types have been mapped, when possible, to SDLC phases: this served to determine the best-performing feature extractions and algorithms for each SDLC phase. Finally, based on the SLR results, we also identify implications that could be of concern to researchers and practitioners.
GitRanking: A Ranking of GitHub Topics for Software Classification using Active Sampling
May 19, 2022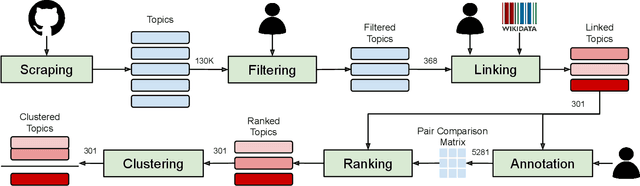
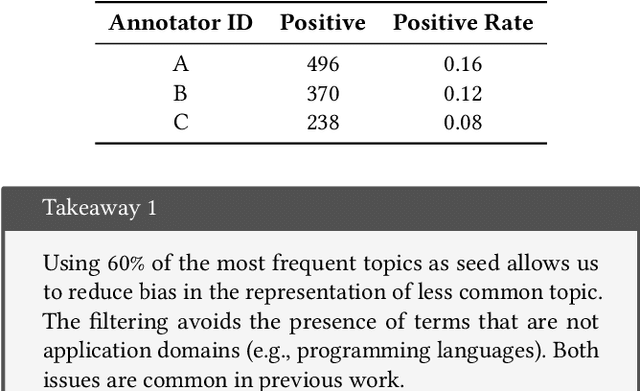


GitHub is the world's largest host of source code, with more than 150M repositories. However, most of these repositories are not labeled or inadequately so, making it harder for users to find relevant projects. There have been various proposals for software application domain classification over the past years. However, these approaches lack a well-defined taxonomy that is hierarchical, grounded in a knowledge base, and free of irrelevant terms. This work proposes GitRanking, a framework for creating a classification ranked into discrete levels based on how general or specific their meaning is. We collected 121K topics from GitHub and considered $60\%$ of the most frequent ones for the ranking. GitRanking 1) uses active sampling to ensure a minimal number of required annotations; and 2) links each topic to Wikidata, reducing ambiguities and improving the reusability of the taxonomy. Our results show that developers, when annotating their projects, avoid using terms with a high degree of specificity. This makes the finding and discovery of their projects more challenging for other users. Furthermore, we show that GitRanking can effectively rank terms according to their general or specific meaning. This ranking would be an essential asset for developers to build upon, allowing them to complement their annotations with more precise topics. Finally, we show that GitRanking is a dynamically extensible method: it can currently accept further terms to be ranked with a minimum number of annotations ($\sim$ 15). This paper is the first collective attempt to build a ground-up taxonomy of software domains.
Antipatterns in Software Classification Taxonomies
Apr 19, 2022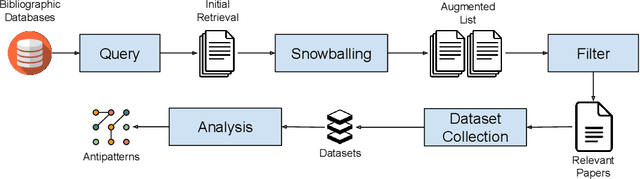

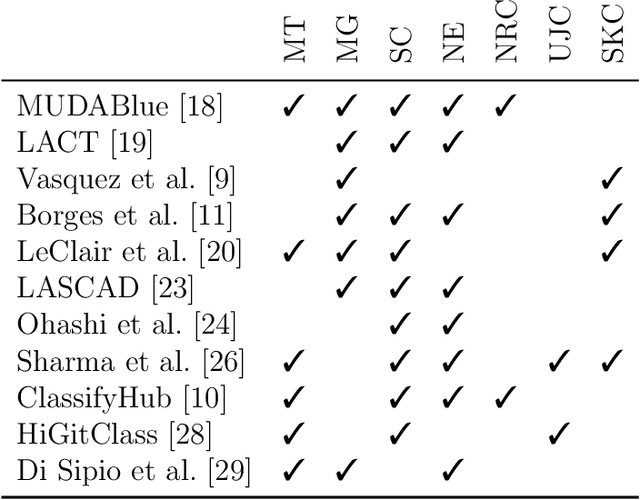
Empirical results in software engineering have long started to show that findings are unlikely to be applicable to all software systems, or any domain: results need to be evaluated in specified contexts, and limited to the type of systems that they were extracted from. This is a known issue, and requires the establishment of a classification of software types. This paper makes two contributions: the first is to evaluate the quality of the current software classifications landscape. The second is to perform a case study showing how to create a classification of software types using a curated set of software systems. Our contributions show that existing, and very likely even new, classification attempts are deemed to fail for one or more issues, that we named as the `antipatterns' of software classification tasks. We collected 7 of these antipatterns that emerge from both our case study, and the existing classifications. These antipatterns represent recurring issues in a classification, so we discuss practical ways to help researchers avoid these pitfalls. It becomes clear that classification attempts must also face the daunting task of formulating a taxonomy of software types, with the objective of establishing a hierarchy of categories in a classification.
LabelGit: A Dataset for Software Repositories Classification using Attributed Dependency Graphs
Mar 16, 2021

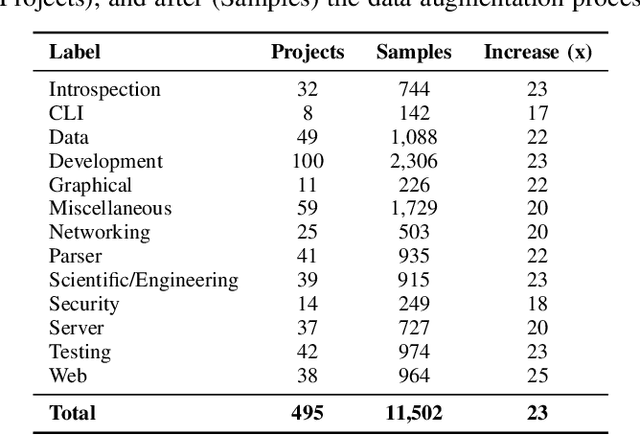
Software repository hosting services contain large amounts of open-source software, with GitHub hosting more than 100 million repositories, from new to established ones. Given this vast amount of projects, there is a pressing need for a search based on the software's content and features. However, even though GitHub offers various solutions to aid software discovery, most repositories do not have any labels, reducing the utility of search and topic-based analysis. Moreover, classifying software modules is also getting more importance given the increase in Component-Based Software Development. However, previous work focused on software classification using keyword-based approaches or proxies for the project (e.g., README), which is not always available. In this work, we create a new annotated dataset of GitHub Java projects called LabelGit. Our dataset uses direct information from the source code, like the dependency graph and source code neural representations from the identifiers. Using this dataset, we hope to aid the development of solutions that do not rely on proxies but use the entire source code to perform classification.
The Prevalence of Errors in Machine Learning Experiments
Sep 10, 2019

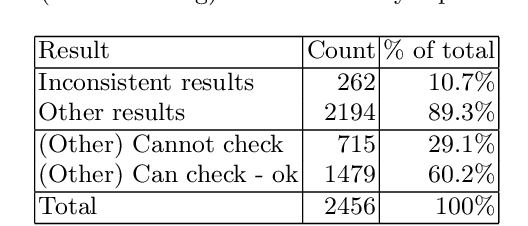
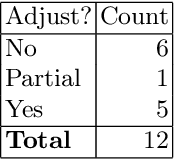
Context: Conducting experiments is central to research machine learning research to benchmark, evaluate and compare learning algorithms. Consequently it is important we conduct reliable, trustworthy experiments. Objective: We investigate the incidence of errors in a sample of machine learning experiments in the domain of software defect prediction. Our focus is simple arithmetical and statistical errors. Method: We analyse 49 papers describing 2456 individual experimental results from a previously undertaken systematic review comparing supervised and unsupervised defect prediction classifiers. We extract the confusion matrices and test for relevant constraints, e.g., the marginal probabilities must sum to one. We also check for multiple statistical significance testing errors. Results: We find that a total of 22 out of 49 papers contain demonstrable errors. Of these 7 were statistical and 16 related to confusion matrix inconsistency (one paper contained both classes of error). Conclusions: Whilst some errors may be of a relatively trivial nature, e.g., transcription errors their presence does not engender confidence. We strongly urge researchers to follow open science principles so errors can be more easily be detected and corrected, thus as a community reduce this worryingly high error rate with our computational experiments.