 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4SCREENLIT: Recommendations on Assessing the Performance of Large Language Models for Screening Literature in Systematic Reviews
Nov 16, 2025


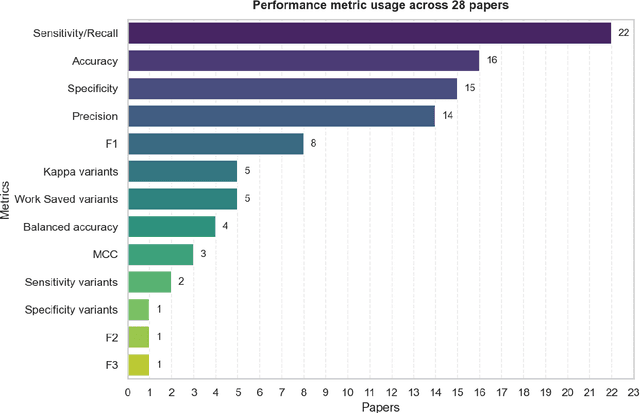
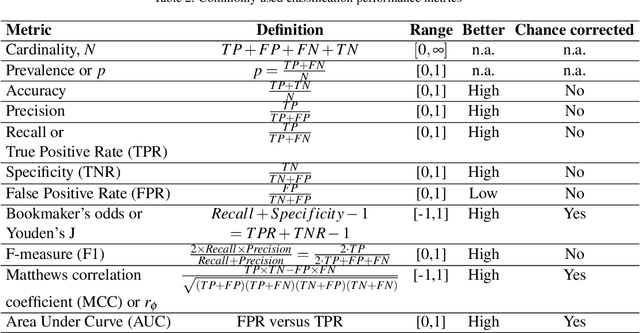
Context: Large language models (LLMs) are released faster than users' ability to evaluate them rigorously. When LLMs underpin research, such as identifying relevant literature for systematic reviews (SRs), robust empirical assessment is essential. Objective: We identify and discuss key challenges in assessing LLM performance for selecting relevant literature, identify good (evaluation) practices, and propose recommendations. Method: Using a recent large-scale study as an example, we identify problems with the use of traditional metrics for assessing the performance of Gen-AI tools for identifying relevant literature in SRs. We analyzed 27 additional papers investigating this issue, extracted the performance metrics, and found both good practices and widespread problems, especially with the use and reporting of performance metrics for SR screening. Results: Major weaknesses included: i) a failure to use metrics that are robust to imbalanced data and do not directly indicate whether results are better than chance, e.g., the use of Accuracy, ii) a failure to consider the impact of lost evidence when making claims concerning workload savings, and iii) pervasive failure to report the full confusion matrix (or performance metrics from which it can be reconstructed) which is essential for future meta-analyses. On the positive side, we extract good (evaluation) practices on which our recommendations for researchers and practitioners, as well as policymakers, are built. Conclusions: SR screening evaluations should prioritize lost evidence/recall alongside chance-anchored and cost-sensitive Weighted MCC (WMCC) metric, report complete confusion matrices, treat unclassifiable outputs as referred-back positives for assessment, adopt leakage-aware designs with non-LLM baselines and open artifacts, and ground conclusions in cost-benefit analysis where FNs carry higher penalties than FPs.
An analysis of retracted papers in Computer Science
Jun 14, 2022
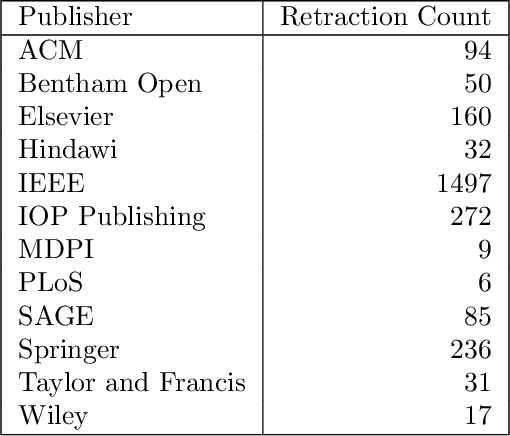

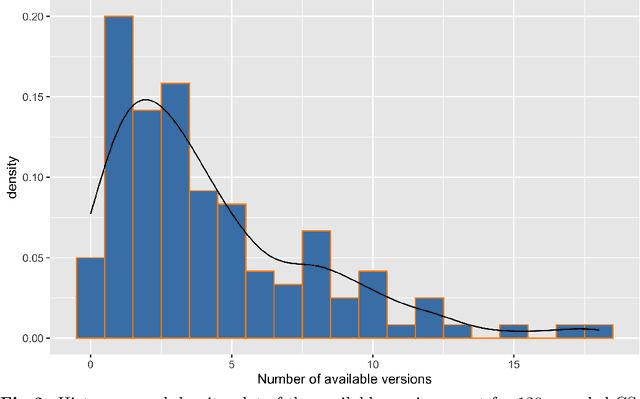
Context: The retraction of research papers, for whatever reason, is a growing phenomenon. However, although retracted paper information is publicly available via publishers, it is somewhat distributed and inconsistent. Objective: The aim is to assess: (i) the extent and nature of retracted research in Computer Science (CS) (ii) the post-retraction citation behaviour of retracted works and (iii) the potential impact on systematic reviews and mapping studies. Method: We analyse the Retraction Watch database and take citation information from the Web of Science and Google scholar. Results: We find that of the 33,955 entries in the Retraction watch database (16 May 2022), 2,816 are classified as CS, i.e., approximately 8.3%. For CS, 56% of retracted papers, provide little or no information as to the reasons. This contrasts with 26% for other disciplines. There is also a remarkable disparity between different publishers, a tendency for multiple versions of a retracted paper over and above the Version of Record (VoR), and for new citations long after a paper is officially retracted. Conclusions: Unfortunately retraction seems to be a sufficiently common outcome for a scientific paper that we as a research community need to take it more seriously, e.g., standardising procedures and taxonomies across publishers and the provision of appropriate research tools. Finally, we recommend particular caution when undertaking secondary analyses and meta-analyses which are at risk of becoming contaminated by these problem primary studies.
The impact of using biased performance metrics on software defect prediction research
Mar 24, 2021
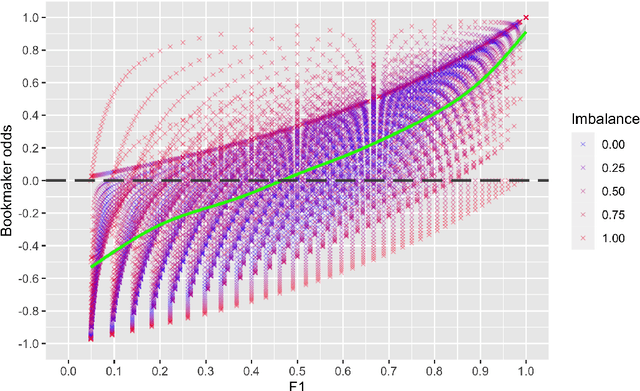
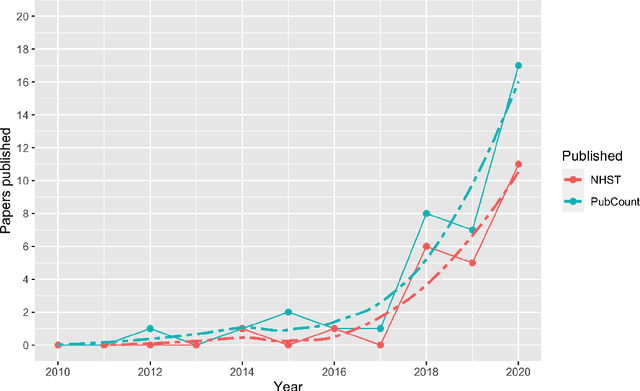
Context: Software engineering researchers have undertaken many experiments investigating the potential of software defect prediction algorithms. Unfortunately, some widely used performance metrics are known to be problematic, most notably F1, but nevertheless F1 is widely used. Objective: To investigate the potential impact of using F1 on the validity of this large body of research. Method: We undertook a systematic review to locate relevant experiments and then extract all pairwise comparisons of defect prediction performance using F1 and the un-biased Matthews correlation coefficient (MCC). Results: We found a total of 38 primary studies. These contain 12,471 pairs of results. Of these, 21.95% changed direction when the MCC metric is used instead of the biased F1 metric. Unfortunately, we also found evidence suggesting that F1 remains widely used in software defect prediction research. Conclusions: We reiterate the concerns of statisticians that the F1 is a problematic metric outside of an information retrieval context, since we are concerned about both classes (defect-prone and not defect-prone units). This inappropriate usage has led to a substantial number (more than one fifth) of erroneous (in terms of direction) results. Therefore we urge researchers to (i) use an unbiased metric and (ii) publish detailed results including confusion matrices such that alternative analyses become possible.
The Prevalence of Errors in Machine Learning Experiments
Sep 10, 2019

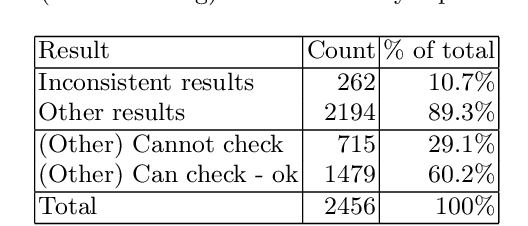
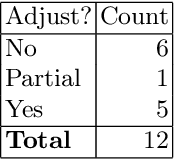
Context: Conducting experiments is central to research machine learning research to benchmark, evaluate and compare learning algorithms. Consequently it is important we conduct reliable, trustworthy experiments. Objective: We investigate the incidence of errors in a sample of machine learning experiments in the domain of software defect prediction. Our focus is simple arithmetical and statistical errors. Method: We analyse 49 papers describing 2456 individual experimental results from a previously undertaken systematic review comparing supervised and unsupervised defect prediction classifiers. We extract the confusion matrices and test for relevant constraints, e.g., the marginal probabilities must sum to one. We also check for multiple statistical significance testing errors. Results: We find that a total of 22 out of 49 papers contain demonstrable errors. Of these 7 were statistical and 16 related to confusion matrix inconsistency (one paper contained both classes of error). Conclusions: Whilst some errors may be of a relatively trivial nature, e.g., transcription errors their presence does not engender confidence. We strongly urge researchers to follow open science principles so errors can be more easily be detected and corrected, thus as a community reduce this worryingly high error rate with our computational experiments.