 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-MapReduce: Executing Wide Search via Agentic MapReduce
Feb 01, 2026Contemporary large language model (LLM)-based multi-agent systems exhibit systematic advantages in deep research tasks, which emphasize iterative, vertically structured information seeking. However, when confronted with wide search tasks characterized by large-scale, breadth-oriented retrieval, existing agentic frameworks, primarily designed around sequential, vertically structured reasoning, remain stuck in expansive search objectives and inefficient long-horizon execution. To bridge this gap, we propose A-MapReduce, a MapReduce paradigm-inspired multi-agent execution framework that recasts wide search as a horizontally structured retrieval problem. Concretely, A-MapReduce implements parallel processing of massive retrieval targets through task-adaptive decomposition and structured result aggregation. Meanwhile, it leverages experiential memory to drive the continual evolution of query-conditioned task allocation and recomposition, enabling progressive improvement in large-scale wide-search regimes. Extensive experiments on five agentic benchmarks demonstrate that A-MapReduce is (i) high-performing, achieving state-of-the-art performance on WideSearch and DeepWideSearch, and delivering 5.11% - 17.50% average Item F1 improvements compared with strong baselines with OpenAI o3 or Gemini 2.5 Pro backbones; (ii) cost-effective and efficient, delivering superior cost-performance trade-offs and reducing running time by 45.8\% compared to representative multi-agent baselines. The code is available at https://github.com/mingju-c/AMapReduce.
SparseFormer: Detecting Objects in HRW Shots via Sparse Vision Transformer
Feb 11, 2025Recent years have seen an increase in the use of gigapixel-level image and video capture systems and benchmarks with high-resolution wide (HRW) shots. However, unlike close-up shots in the MS COCO dataset, the higher resolution and wider field of view raise unique challenges, such as extreme sparsity and huge scale changes, causing existing close-up detectors inaccuracy and inefficiency. In this paper, we present a novel model-agnostic sparse vision transformer, dubbed SparseFormer, to bridge the gap of object detection between close-up and HRW shots. The proposed SparseFormer selectively uses attentive tokens to scrutinize the sparsely distributed windows that may contain objects. In this way, it can jointly explore global and local attention by fusing coarse- and fine-grained features to handle huge scale changes. SparseFormer also benefits from a novel Cross-slice non-maximum suppression (C-NMS) algorithm to precisely localize objects from noisy windows and a simple yet effective multi-scale strategy to improve accuracy. Extensive experiments on two HRW benchmarks, PANDA and DOTA-v1.0, demonstrate that the proposed SparseFormer significantly improves detection accuracy (up to 5.8%) and speed (up to 3x) over the state-of-the-art approaches.
Corner2Net: Detecting Objects as Cascade Corners
Nov 24, 2024



The corner-based detection paradigm enjoys the potential to produce high-quality boxes. But the development is constrained by three factors: 1) Hard to match corners. Heuristic corner matching algorithms can lead to incorrect boxes, especially when similar-looking objects co-occur. 2) Poor instance context. Two separate corners preserve few instance semantics, so it is difficult to guarantee getting both two class-specific corners on the same heatmap channel. 3) Unfriendly backbone. The training cost of the hourglass network is high. Accordingly, we build a novel corner-based framework, named Corner2Net. To achieve the corner-matching-free manner, we devise the cascade corner pipeline which progressively predicts the associated corner pair in two steps instead of synchronously searching two independent corners via parallel heads. Corner2Net decouples corner localization and object classification. Both two corners are class-agnostic and the instance-specific bottom-right corner further simplifies its search space. Meanwhile, RoI features with rich semantics are extracted for classification. Popular backbones (e.g., ResNeXt) can be easily connected to Corner2Net. Experimental results on COCO show Corner2Net surpasses all existing corner-based detectors by a large margin in accuracy and speed.
* This paper is accepted by 27th EUROPEAN CONFERENCE ON ARTIFICIAL INTELLIGENCE (ECAI 2024)
Enabling Explainable Recommendation in E-commerce with LLM-powered Product Knowledge Graph
Nov 17, 2024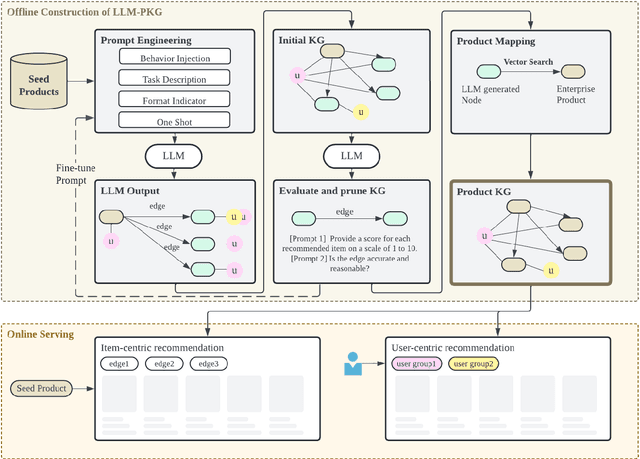



How to leverage large language model's superior capability in e-commerce recommendation has been a hot topic. In this paper, we propose LLM-PKG, an efficient approach that distills the knowledge of LLMs into product knowledge graph (PKG) and then applies PKG to provide explainable recommendations. Specifically, we first build PKG by feeding curated prompts to LLM, and then map LLM response to real enterprise products. To mitigate the risks associated with LLM hallucination, we employ rigorous evaluation and pruning methods to ensure the reliability and availability of the KG. Through an A/B test conducted on an e-commerce website, we demonstrate the effectiveness of LLM-PKG in driving user engagements and transactions significantly.
Fuse4Seg: Image-Level Fusion Based Multi-Modality Medical Image Segmentation
Sep 17, 2024Although multi-modality medical image segmentation holds significant potential for enhancing the diagnosis and understanding of complex diseases by integrating diverse imaging modalities, existing methods predominantly rely on feature-level fusion strategies. We argue the current feature-level fusion strategy is prone to semantic inconsistencies and misalignments across various imaging modalities because it merges features at intermediate layers in a neural network without evaluative control. To mitigate this, we introduce a novel image-level fusion based multi-modality medical image segmentation method, Fuse4Seg, which is a bi-level learning framework designed to model the intertwined dependencies between medical image segmentation and medical image fusion. The image-level fusion process is seamlessly employed to guide and enhance the segmentation results through a layered optimization approach. Besides, the knowledge gained from the segmentation module can effectively enhance the fusion module. This ensures that the resultant fused image is a coherent representation that accurately amalgamates information from all modalities. Moreover, we construct a BraTS-Fuse benchmark based on BraTS dataset, which includes 2040 paired original images, multi-modal fusion images, and ground truth. This benchmark not only serves image-level medical segmentation but is also the largest dataset for medical image fusion to date. Extensive experiments on several public datasets and our benchmark demonstrate the superiority of our approach over prior state-of-the-art (SOTA) methodologies.
DAE-Fuse: An Adaptive Discriminative Autoencoder for Multi-Modality Image Fusion
Sep 16, 2024



Multi-modality image fusion aims to integrate complementary data information from different imaging modalities into a single image. Existing methods often generate either blurry fused images that lose fine-grained semantic information or unnatural fused images that appear perceptually cropped from the inputs. In this work, we propose a novel two-phase discriminative autoencoder framework, termed DAE-Fuse, that generates sharp and natural fused images. In the adversarial feature extraction phase, we introduce two discriminative blocks into the encoder-decoder architecture, providing an additional adversarial loss to better guide feature extraction by reconstructing the source images. While the two discriminative blocks are adapted in the attention-guided cross-modality fusion phase to distinguish the structural differences between the fused output and the source inputs, injecting more naturalness into the results. Extensive experiments on public infrared-visible, medical image fusion, and downstream object detection datasets demonstrate our method's superiority and generalizability in both quantitative and qualitative evaluations.
DynamicTrack: Advancing Gigapixel Tracking in Crowded Scenes
Jul 26, 2024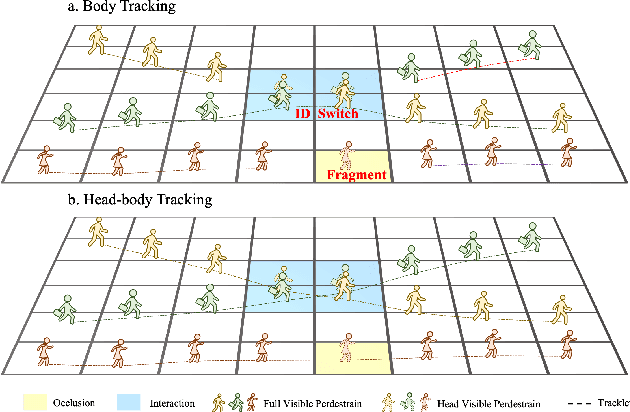
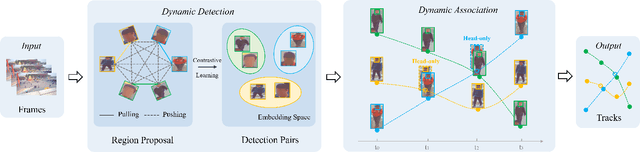
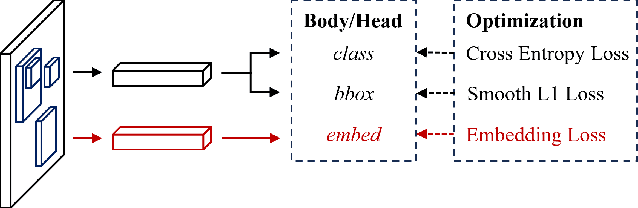

Tracking in gigapixel scenarios holds numerous potential applications in video surveillance and pedestrian analysis. Existing algorithms attempt to perform tracking in crowded scenes by utilizing multiple cameras or group relationships. However, their performance significantly degrades when confronted with complex interaction and occlusion inherent in gigapixel images. In this paper, we introduce DynamicTrack, a dynamic tracking framework designed to address gigapixel tracking challenges in crowded scenes. In particular, we propose a dynamic detector that utilizes contrastive learning to jointly detect the head and body of pedestrians. Building upon this, we design a dynamic association algorithm that effectively utilizes head and body information for matching purposes. Extensive experiments show that our tracker achieves state-of-the-art performance on widely used tracking benchmarks specifically designed for gigapixel crowded scenes.
SaccadeDet: A Novel Dual-Stage Architecture for Rapid and Accurate Detection in Gigapixel Images
Jul 25, 2024The advancement of deep learning in object detection has predominantly focused on megapixel images, leaving a critical gap in the efficient processing of gigapixel images. These super high-resolution images present unique challenges due to their immense size and computational demands. To address this, we introduce 'SaccadeDet', an innovative architecture for gigapixel-level object detection, inspired by the human eye saccadic movement. The cornerstone of SaccadeDet is its ability to strategically select and process image regions, dramatically reducing computational load. This is achieved through a two-stage process: the 'saccade' stage, which identifies regions of probable interest, and the 'gaze' stage, which refines detection in these targeted areas. Our approach, evaluated on the PANDA dataset, not only achieves an 8x speed increase over the state-of-the-art methods but also demonstrates significant potential in gigapixel-level pathology analysis through its application to Whole Slide Imaging.
* This paper is accepted to ECML-PKDD 2024
Deep Learning-Based Quasi-Conformal Surface Registration for Partial 3D Faces Applied to Facial Recognition
May 16, 2024



3D face registration is an important process in which a 3D face model is aligned and mapped to a template face. However, the task of 3D face registration becomes particularly challenging when dealing with partial face data, where only limited facial information is available. To address this challenge, this paper presents a novel deep learning-based approach that combines quasi-conformal geometry with deep neural networks for partial face registration. The proposed framework begins with a Landmark Detection Network that utilizes curvature information to detect the presence of facial features and estimate their corresponding coordinates. These facial landmark features serve as essential guidance for the registration process. To establish a dense correspondence between the partial face and the template surface, a registration network based on quasiconformal theories is employed. The registration network establishes a bijective quasiconformal surface mapping aligning corresponding partial faces based on detected landmarks and curvature values. It consists of the Coefficients Prediction Network, which outputs the optimal Beltrami coefficient representing the surface mapping. The Beltrami coefficient quantifies the local geometric distortion of the mapping. By controlling the magnitude of the Beltrami coefficient through a suitable activation function, the bijectivity and geometric distortion of the mapping can be controlled. The Beltrami coefficient is then fed into the Beltrami solver network to reconstruct the corresponding mapping. The surface registration enables the acquisition of corresponding regions and the establishment of point-wise correspondence between different partial faces, facilitating precise shape comparison through the evaluation of point-wise geometric differences at these corresponding regions. Experimental results demonstrate the effectiveness of the proposed method.
Debiased Novel Category Discovering and Localization
Feb 29, 2024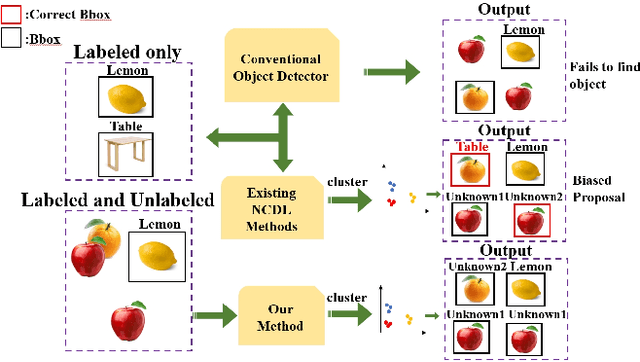

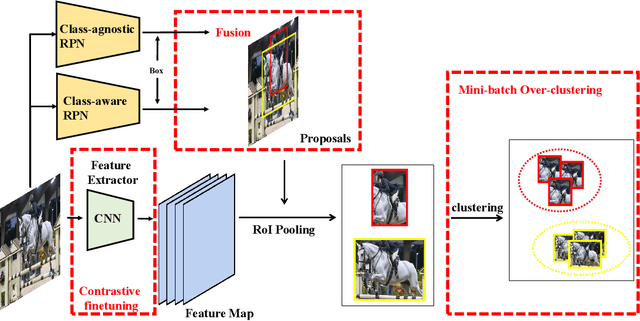

In recent years, object detection in deep learning has experienced rapid development. However, most existing object detection models perform well only on closed-set datasets, ignoring a large number of potential objects whose categories are not defined in the training set. These objects are often identified as background or incorrectly classified as pre-defined categories by the detectors. In this paper, we focus on the challenging problem of Novel Class Discovery and Localization (NCDL), aiming to train detectors that can detect the categories present in the training data, while also actively discover, localize, and cluster new categories. We analyze existing NCDL methods and identify the core issue: object detectors tend to be biased towards seen objects, and this leads to the neglect of unseen targets. To address this issue, we first propose an Debiased Region Mining (DRM) approach that combines class-agnostic Region Proposal Network (RPN) and class-aware RPN in a complementary manner. Additionally, we suggest to improve the representation network through semi-supervised contrastive learning by leveraging unlabeled data. Finally, we adopt a simple and efficient mini-batch K-means clustering method for novel class discovery. We conduct extensive experiments on the NCDL benchmark, and the results demonstrate that the proposed DRM approach significantly outperforms previous methods, establishing a new state-of-the-art.