 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Explainable Recommendation in E-commerce with LLM-powered Product Knowledge Graph
Nov 17, 2024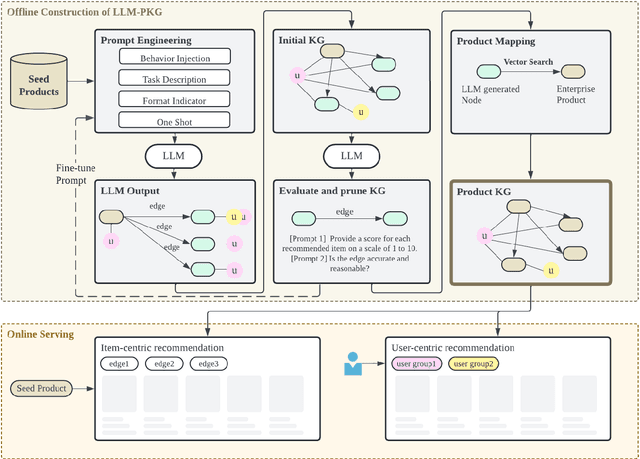



How to leverage large language model's superior capability in e-commerce recommendation has been a hot topic. In this paper, we propose LLM-PKG, an efficient approach that distills the knowledge of LLMs into product knowledge graph (PKG) and then applies PKG to provide explainable recommendations. Specifically, we first build PKG by feeding curated prompts to LLM, and then map LLM response to real enterprise products. To mitigate the risks associated with LLM hallucination, we employ rigorous evaluation and pruning methods to ensure the reliability and availability of the KG. Through an A/B test conducted on an e-commerce website, we demonstrate the effectiveness of LLM-PKG in driving user engagements and transactions significantly.
Deep-URL: A Model-Aware Approach To Blind Deconvolution Based On Deep Unfolded Richardson-Lucy Network
Feb 06, 2020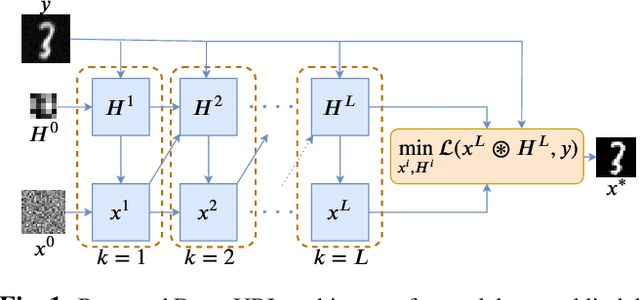
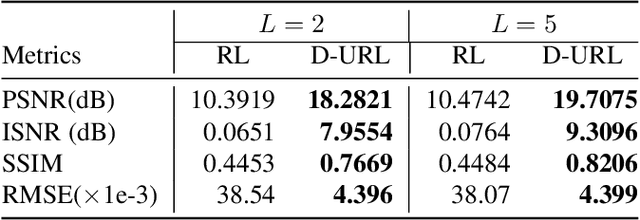
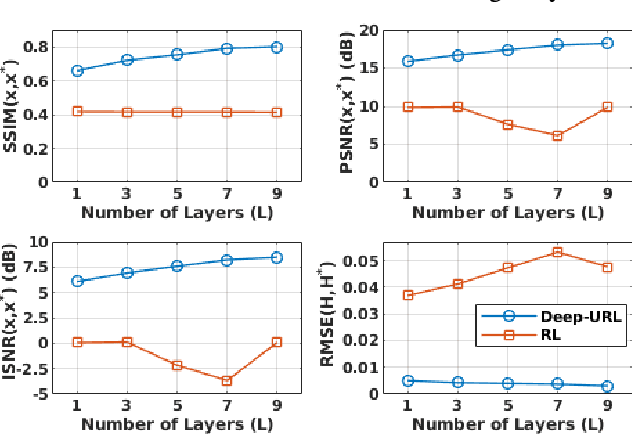
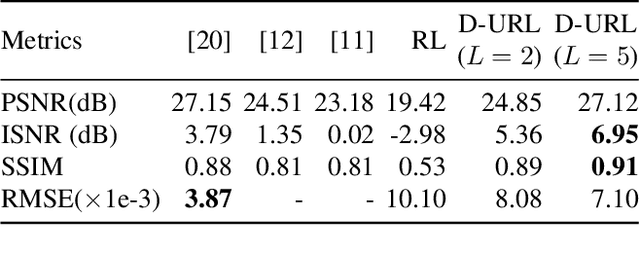
The lack of interpretability in current deep learning models causes serious concerns as they are extensively used for various life-critical applications. Hence, it is of paramount importance to develop interpretable deep learning models. In this paper, we consider the problem of blind deconvolution and propose a novel model-aware deep architecture that allows for the recovery of both the blur kernel and the sharp image from the blurred image. In particular, we propose the Deep Unfolded Richardson-Lucy (Deep-URL) framework -- an interpretable deep-learning architecture that can be seen as an amalgamation of classical estimation technique and deep neural network, and consequently leads to improved performance. Our numerical investigations demonstrate significant improvement compared to state-of-the-art algorithms.
Removing input features via a generative model to explain their attributions to classifier's decisions
Oct 09, 2019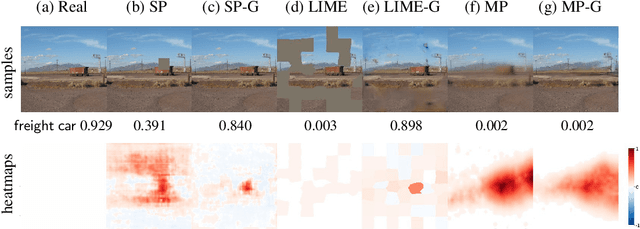
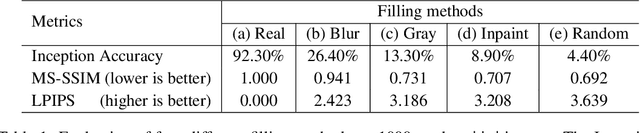


Interpretability methods often measure the contribution of an input feature to an image classifier's decisions by heuristically removing it via e.g. blurring, adding noise, or graying out, which often produce unrealistic, out-of-samples. Instead, we propose to integrate a generative inpainter into three representative attribution methods to remove an input feature. Compared to the original counterparts, our methods (1) generate more plausible counterfactual samples under the true data generating process; (2) are more robust to hyperparameter settings; and (3) localize objects more accurately. Our findings were consistent across both ImageNet and Places365 datasets and two different pairs of classifiers and inpainters.
Improving Adversarial Robustness by Encouraging Discriminative Features
Nov 01, 2018

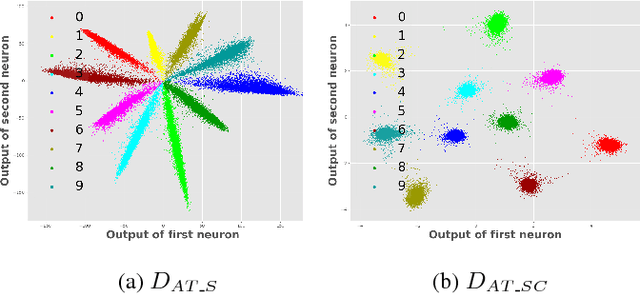

Deep neural networks (DNNs) have achieved state-of-the-art results in various pattern recognition tasks. However, they perform poorly on out-of-distribution adversarial examples i.e. inputs that are specifically crafted by an adversary to cause DNNs to misbehave, questioning the security and reliability of applications. In this paper, we encourage DNN classifiers to learn more discriminative features by imposing a center loss in addition to the regular softmax cross-entropy loss. Intuitively, the center loss encourages DNNs to simultaneously learns a center for the deep features of each class, and minimize the distances between the intra-class deep features and their corresponding class centers. We hypothesize that minimizing distances between intra-class features and maximizing the distances between inter-class features at the same time would improve a classifier's robustness to adversarial examples. Our results on state-of-the-art architectures on MNIST, CIFAR-10, and CIFAR-100 confirmed that intuition and highlight the importance of discriminative features.
CrossNets: Cross-Information Flow in Deep Learning Architectures
Jul 15, 2018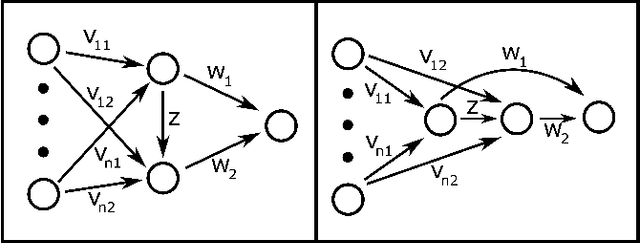

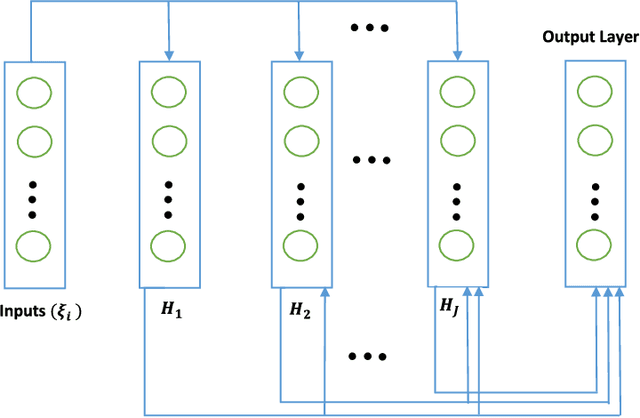

We propose a novel neural network structure called CrossNets, which considers architectures on directed acyclic graphs. This structure builds on previous generalization of sequential feed-forward models, such as ResNets, by allowing for all forward cross-connections between both adjacent and non-adjacent layers. The addition of cross-connections within the network increases the information flow across the whole network, leading to better training and testing performances. The superior performance of the network is tested against both image classification and compression tasks using various datasets, such as MNIST, FER, CIFAR-10, CIFAR-100, and SVHN. We conclude with a proof of convergence for CrossNets to a local minimum for error, where weights for connections are chosen through backpropagation with momentum.
An Explainable Adversarial Robustness Metric for Deep Learning Neural Networks
Jun 06, 2018
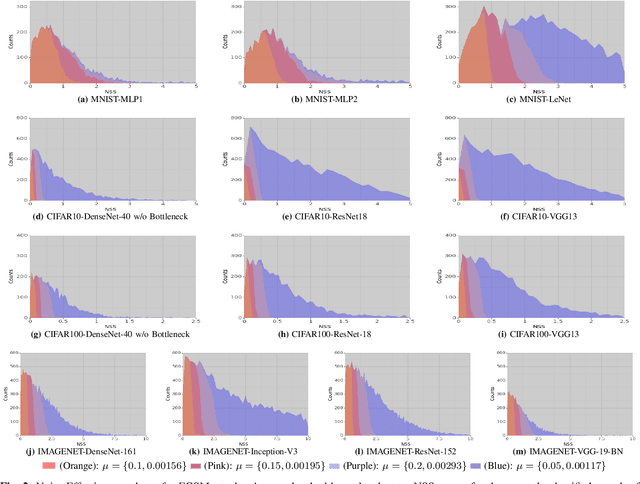
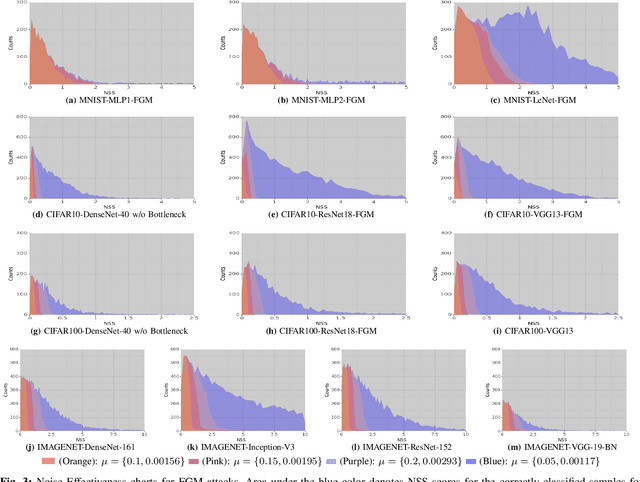
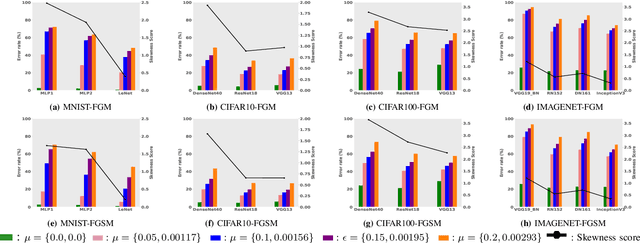
Deep Neural Networks(DNN) have excessively advanced the field of computer vision by achieving state of the art performance in various vision tasks. These results are not limited to the field of vision but can also be seen in speech recognition and machine translation tasks. Recently, DNNs are found to poorly fail when tested with samples that are crafted by making imperceptible changes to the original input images. This causes a gap between the validation and adversarial performance of a DNN. An effective and generalizable robustness metric for evaluating the performance of DNN on these adversarial inputs is still missing from the literature. In this paper, we propose Noise Sensitivity Score (NSS), a metric that quantifies the performance of a DNN on a specific input under different forms of fix-directional attacks. An insightful mathematical explanation is provided for deeply understanding the proposed metric. By leveraging the NSS, we also proposed a skewness based dataset robustness metric for evaluating a DNN's adversarial performance on a given dataset. Extensive experiments using widely used state of the art architectures along with popular classification datasets, such as MNIST, CIFAR-10, CIFAR-100, and ImageNet, are used to validate the effectiveness and generalization of our proposed metrics. Instead of simply measuring a DNN's adversarial robustness in the input domain, as previous works, the proposed NSS is built on top of insightful mathematical understanding of the adversarial attack and gives a more explicit explanation of the robustness.
Compressive Sensing of Sparse Tensors
Sep 03, 2014


Compressive sensing (CS) has triggered enormous research activity since its first appearance. CS exploits the signal's sparsity or compressibility in a particular domain and integrates data compression and acquisition, thus allowing exact reconstruction through relatively few non-adaptive linear measurements. While conventional CS theory relies on data representation in the form of vectors, many data types in various applications such as color imaging, video sequences, and multi-sensor networks, are intrinsically represented by higher-order tensors. Application of CS to higher-order data representation is typically performed by conversion of the data to very long vectors that must be measured using very large sampling matrices, thus imposing a huge computational and memory burden. In this paper, we propose Generalized Tensor Compressive Sensing (GTCS)--a unified framework for compressive sensing of higher-order tensors which preserves the intrinsic structure of tensor data with reduced computational complexity at reconstruction. GTCS offers an efficient means for representation of multidimensional data by providing simultaneous acquisition and compression from all tensor modes. In addition, we propound two reconstruction procedures, a serial method (GTCS-S) and a parallelizable method (GTCS-P). We then compare the performance of the proposed method with Kronecker compressive sensing (KCS) and multi way compressive sensing (MWCS). We demonstrate experimentally that GTCS outperforms KCS and MWCS in terms of both reconstruction accuracy (within a range of compression ratios) and processing speed. The major disadvantage of our methods (and of MWCS as well), is that the compression ratios may be worse than that offered by KCS.
Two-Dimensional ARMA Modeling for Breast Cancer Detection and Classification
Jun 19, 2009
We propose a new model-based computer-aided diagnosis (CAD) system for tumor detection and classification (cancerous v.s. benign) in breast images. Specifically, we show that (x-ray, ultrasound and MRI) images can be accurately modeled by two-dimensional autoregressive-moving average (ARMA) random fields. We derive a two-stage Yule-Walker Least-Squares estimates of the model parameters, which are subsequently used as the basis for statistical inference and biophysical interpretation of the breast image. We use a k-means classifier to segment the breast image into three regions: healthy tissue, benign tumor, and cancerous tumor. Our simulation results on ultrasound breast images illustrate the power of the proposed approach.