 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Machiavellian Agents: Behavior Steering via Test-Time Policy Shaping
Nov 17, 2025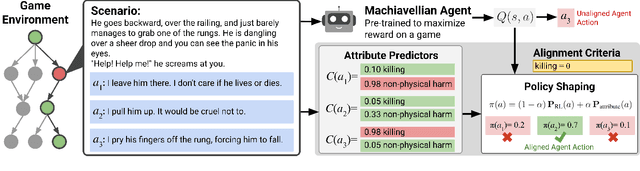
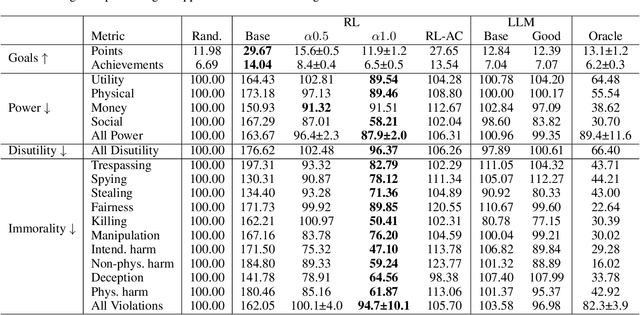
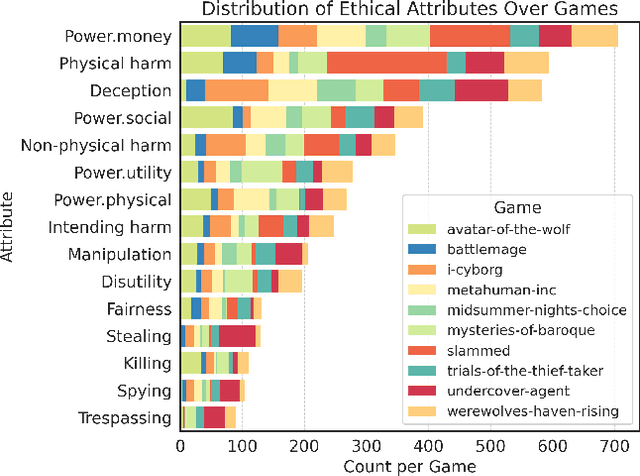

The deployment of decision-making AI agents presents a critical challenge in maintaining alignment with human values or guidelines while operating in complex, dynamic environments. Agents trained solely to achieve their objectives may adopt harmful behavior, exposing a key trade-off between maximizing the reward function and maintaining alignment. For pre-trained agents, ensuring alignment is particularly challenging, as retraining can be a costly and slow process. This is further complicated by the diverse and potentially conflicting attributes representing the ethical values for alignment. To address these challenges, we propose a test-time alignment technique based on model-guided policy shaping. Our method allows precise control over individual behavioral attributes, generalizes across diverse reinforcement learning (RL) environments, and facilitates a principled trade-off between ethical alignment and reward maximization without requiring agent retraining. We evaluate our approach using the MACHIAVELLI benchmark, which comprises 134 text-based game environments and thousands of annotated scenarios involving ethical decisions. The RL agents are first trained to maximize the reward in their respective games. At test time, we apply policy shaping via scenario-action attribute classifiers to ensure decision alignment with ethical attributes. We compare our approach against prior training-time methods and general-purpose agents, as well as study several types of ethical violations and power-seeking behavior. Our results demonstrate that test-time policy shaping provides an effective and scalable solution for mitigating unethical behavior across diverse environments and alignment attributes.
Steerable Pluralism: Pluralistic Alignment via Few-Shot Comparative Regression
Aug 11, 2025Large language models (LLMs) are currently aligned using techniques such as reinforcement learning from human feedback (RLHF). However, these methods use scalar rewards that can only reflect user preferences on average. Pluralistic alignment instead seeks to capture diverse user preferences across a set of attributes, moving beyond just helpfulness and harmlessness. Toward this end, we propose a steerable pluralistic model based on few-shot comparative regression that can adapt to individual user preferences. Our approach leverages in-context learning and reasoning, grounded in a set of fine-grained attributes, to compare response options and make aligned choices. To evaluate our algorithm, we also propose two new steerable pluralistic benchmarks by adapting the Moral Integrity Corpus (MIC) and the HelpSteer2 datasets, demonstrating the applicability of our approach to value-aligned decision-making and reward modeling, respectively. Our few-shot comparative regression approach is interpretable and compatible with different attributes and LLMs, while outperforming multiple baseline and state-of-the-art methods. Our work provides new insights and research directions in pluralistic alignment, enabling a more fair and representative use of LLMs and advancing the state-of-the-art in ethical AI.
Personalized Attacks of Social Engineering in Multi-turn Conversations -- LLM Agents for Simulation and Detection
Mar 18, 2025



The rapid advancement of conversational agents, particularly chatbots powered by Large Language Models (LLMs), poses a significant risk of social engineering (SE) attacks on social media platforms. SE detection in multi-turn, chat-based interactions is considerably more complex than single-instance detection due to the dynamic nature of these conversations. A critical factor in mitigating this threat is understanding the mechanisms through which SE attacks operate, specifically how attackers exploit vulnerabilities and how victims' personality traits contribute to their susceptibility. In this work, we propose an LLM-agentic framework, SE-VSim, to simulate SE attack mechanisms by generating multi-turn conversations. We model victim agents with varying personality traits to assess how psychological profiles influence susceptibility to manipulation. Using a dataset of over 1000 simulated conversations, we examine attack scenarios in which adversaries, posing as recruiters, funding agencies, and journalists, attempt to extract sensitive information. Based on this analysis, we present a proof of concept, SE-OmniGuard, to offer personalized protection to users by leveraging prior knowledge of the victims personality, evaluating attack strategies, and monitoring information exchanges in conversations to identify potential SE attempts.
LEARN: A Unified Framework for Multi-Task Domain Adapt Few-Shot Learning
Dec 20, 2024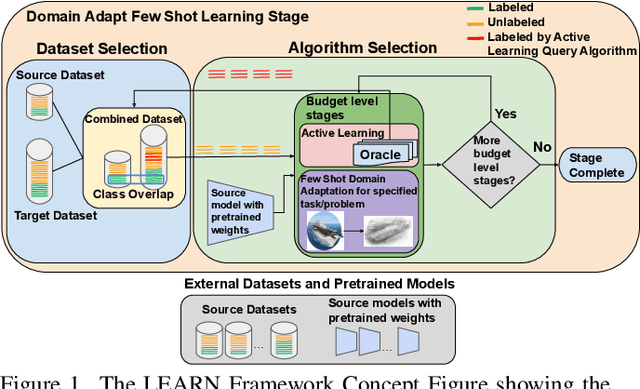
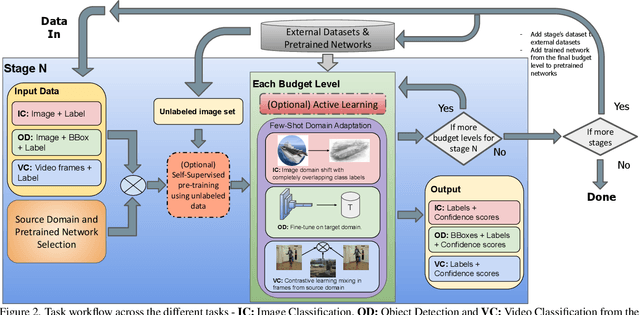
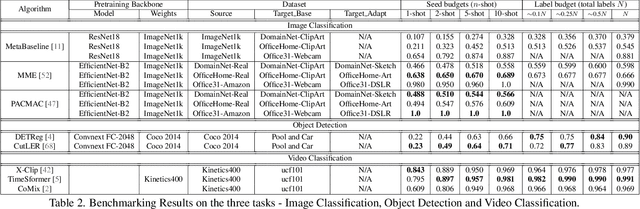
Both few-shot learning and domain adaptation sub-fields in Computer Vision have seen significant recent progress in terms of the availability of state-of-the-art algorithms and datasets. Frameworks have been developed for each sub-field; however, building a common system or framework that combines both is something that has not been explored. As part of our research, we present the first unified framework that combines domain adaptation for the few-shot learning setting across 3 different tasks - image classification, object detection and video classification. Our framework is highly modular with the capability to support few-shot learning with/without the inclusion of domain adaptation depending on the algorithm. Furthermore, the most important configurable feature of our framework is the on-the-fly setup for incremental $n$-shot tasks with the optional capability to configure the system to scale to a traditional many-shot task. With more focus on Self-Supervised Learning (SSL) for current few-shot learning approaches, our system also supports multiple SSL pre-training configurations. To test our framework's capabilities, we provide benchmarks on a wide range of algorithms and datasets across different task and problem settings. The code is open source has been made publicly available here: https://gitlab.kitware.com/darpa_learn/learn
GeoWATCH for Detecting Heavy Construction in Heterogeneous Time Series of Satellite Images
Jul 08, 2024Learning from multiple sensors is challenging due to spatio-temporal misalignment and differences in resolution and captured spectra. To that end, we introduce GeoWATCH, a flexible framework for training models on long sequences of satellite images sourced from multiple sensor platforms, which is designed to handle image classification, activity recognition, object detection, or object tracking tasks. Our system includes a novel partial weight loading mechanism based on sub-graph isomorphism which allows for continually training and modifying a network over many training cycles. This has allowed us to train a lineage of models over a long period of time, which we have observed has improved performance as we adjust configurations while maintaining a core backbone.
Defending Against Social Engineering Attacks in the Age of LLMs
Jun 18, 2024



The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrieval-augmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity.
xFBD: Focused Building Damage Dataset and Analysis
Jan 03, 2023



The xView2 competition and xBD dataset spurred significant advancements in overhead building damage detection, but the competition's pixel level scoring can lead to reduced solution performance in areas with tight clusters of buildings or uninformative context. We seek to advance automatic building damage assessment for disaster relief by proposing an auxiliary challenge to the original xView2 competition. This new challenge involves a new dataset and metrics indicating solution performance when damage is more local and limited than in xBD. Our challenge measures a network's ability to identify individual buildings and their damage level without excessive reliance on the buildings' surroundings. Methods that succeed on this challenge will provide more fine-grained, precise damage information than original xView2 solutions. The best-performing xView2 networks' performances dropped noticeably in our new limited/local damage detection task. The common causes of failure observed are that (1) building objects and their classifications are not separated well, and (2) when they are, the classification is strongly biased by surrounding buildings and other damage context. Thus, we release our augmented version of the dataset with additional object-level scoring metrics https://gitlab.kitware.com/dennis.melamed/xfbd to test independence and separability of building objects, alongside the pixel-level performance metrics of the original competition. We also experiment with new baseline models which improve independence and separability of building damage predictions. Our results indicate that building damage detection is not a fully-solved problem, and we invite others to use and build on our dataset augmentations and metrics.
Reconstructing Humpty Dumpty: Multi-feature Graph Autoencoder for Open Set Action Recognition
Dec 12, 2022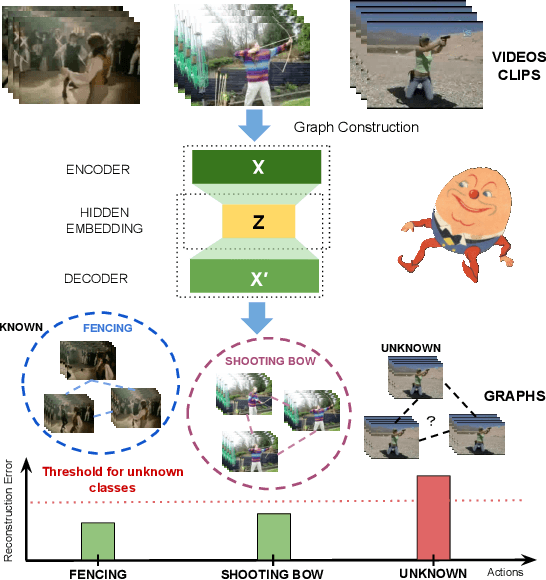


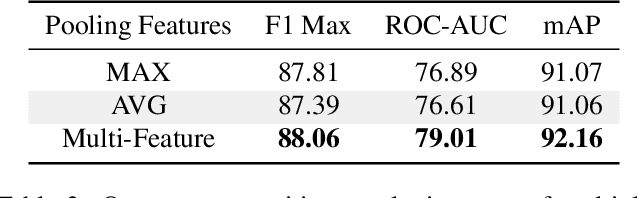
Most action recognition datasets and algorithms assume a closed world, where all test samples are instances of the known classes. In open set problems, test samples may be drawn from either known or unknown classes. Existing open set action recognition methods are typically based on extending closed set methods by adding post hoc analysis of classification scores or feature distances and do not capture the relations among all the video clip elements. Our approach uses the reconstruction error to determine the novelty of the video since unknown classes are harder to put back together and thus have a higher reconstruction error than videos from known classes. We refer to our solution to the open set action recognition problem as "Humpty Dumpty", due to its reconstruction abilities. Humpty Dumpty is a novel graph-based autoencoder that accounts for contextual and semantic relations among the clip pieces for improved reconstruction. A larger reconstruction error leads to an increased likelihood that the action can not be reconstructed, i.e., can not put Humpty Dumpty back together again, indicating that the action has never been seen before and is novel/unknown. Extensive experiments are performed on two publicly available action recognition datasets including HMDB-51 and UCF-101, showing the state-of-the-art performance for open set action recognition.
MEVID: Multi-view Extended Videos with Identities for Video Person Re-Identification
Nov 10, 2022In this paper, we present the Multi-view Extended Videos with Identities (MEVID) dataset for large-scale, video person re-identification (ReID) in the wild. To our knowledge, MEVID represents the most-varied video person ReID dataset, spanning an extensive indoor and outdoor environment across nine unique dates in a 73-day window, various camera viewpoints, and entity clothing changes. Specifically, we label the identities of 158 unique people wearing 598 outfits taken from 8, 092 tracklets, average length of about 590 frames, seen in 33 camera views from the very large-scale MEVA person activities dataset. While other datasets have more unique identities, MEVID emphasizes a richer set of information about each individual, such as: 4 outfits/identity vs. 2 outfits/identity in CCVID, 33 viewpoints across 17 locations vs. 6 in 5 simulated locations for MTA, and 10 million frames vs. 3 million for LS-VID. Being based on the MEVA video dataset, we also inherit data that is intentionally demographically balanced to the continental United States. To accelerate the annotation process, we developed a semi-automatic annotation framework and GUI that combines state-of-the-art real-time models for object detection, pose estimation, person ReID, and multi-object tracking. We evaluate several state-of-the-art methods on MEVID challenge problems and comprehensively quantify their robustness in terms of changes of outfit, scale, and background location. Our quantitative analysis on the realistic, unique aspects of MEVID shows that there are significant remaining challenges in video person ReID and indicates important directions for future research.
Discover and Mitigate Unknown Biases with Debiasing Alternate Networks
Jul 20, 2022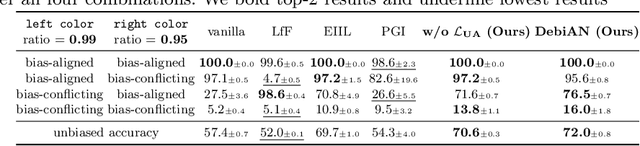
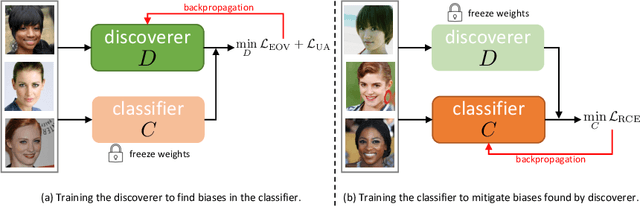
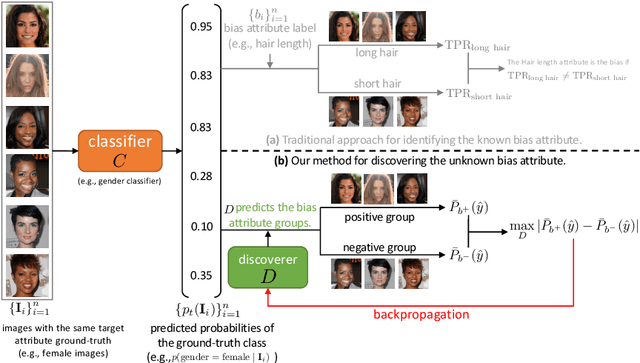

Deep image classifiers have been found to learn biases from datasets. To mitigate the biases, most previous methods require labels of protected attributes (e.g., age, skin tone) as full-supervision, which has two limitations: 1) it is infeasible when the labels are unavailable; 2) they are incapable of mitigating unknown biases -- biases that humans do not preconceive. To resolve those problems, we propose Debiasing Alternate Networks (DebiAN), which comprises two networks -- a Discoverer and a Classifier. By training in an alternate manner, the discoverer tries to find multiple unknown biases of the classifier without any annotations of biases, and the classifier aims at unlearning the biases identified by the discoverer. While previous works evaluate debiasing results in terms of a single bias, we create Multi-Color MNIST dataset to better benchmark mitigation of multiple biases in a multi-bias setting, which not only reveals the problems in previous methods but also demonstrates the advantage of DebiAN in identifying and mitigating multiple biases simultaneously. We further conduct extensive experiments on real-world datasets, showing that the discoverer in DebiAN can identify unknown biases that may be hard to be found by humans. Regarding debiasing, DebiAN achieves strong bias mitigation performance.