 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Activity Recognition in an Open World
Dec 23, 2022
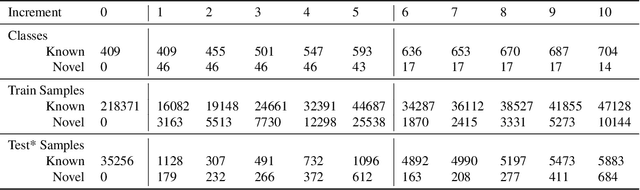

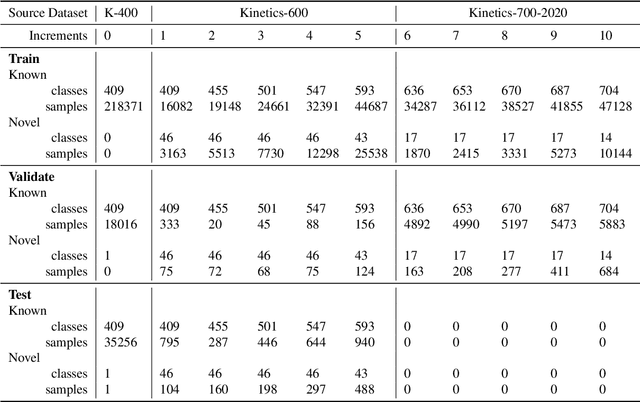
Managing novelty in perception-based human activity recognition (HAR) is critical in realistic settings to improve task performance over time and ensure solution generalization outside of prior seen samples. Novelty manifests in HAR as unseen samples, activities, objects, environments, and sensor changes, among other ways. Novelty may be task-relevant, such as a new class or new features, or task-irrelevant resulting in nuisance novelty, such as never before seen noise, blur, or distorted video recordings. To perform HAR optimally, algorithmic solutions must be tolerant to nuisance novelty, and learn over time in the face of novelty. This paper 1) formalizes the definition of novelty in HAR building upon the prior definition of novelty in classification tasks, 2) proposes an incremental open world learning (OWL) protocol and applies it to the Kinetics datasets to generate a new benchmark KOWL-718, 3) analyzes the performance of current state-of-the-art HAR models when novelty is introduced over time, 4) provides a containerized and packaged pipeline for reproducing the OWL protocol and for modifying for any future updates to Kinetics. The experimental analysis includes an ablation study of how the different models perform under various conditions as annotated by Kinetics-AVA. The protocol as an algorithm for reproducing experiments using the KOWL-718 benchmark will be publicly released with code and containers at https://github.com/prijatelj/human-activity-recognition-in-an-open-world. The code may be used to analyze different annotations and subsets of the Kinetics datasets in an incremental open world fashion, as well as be extended as further updates to Kinetics are released.
Reconstructing Humpty Dumpty: Multi-feature Graph Autoencoder for Open Set Action Recognition
Dec 12, 2022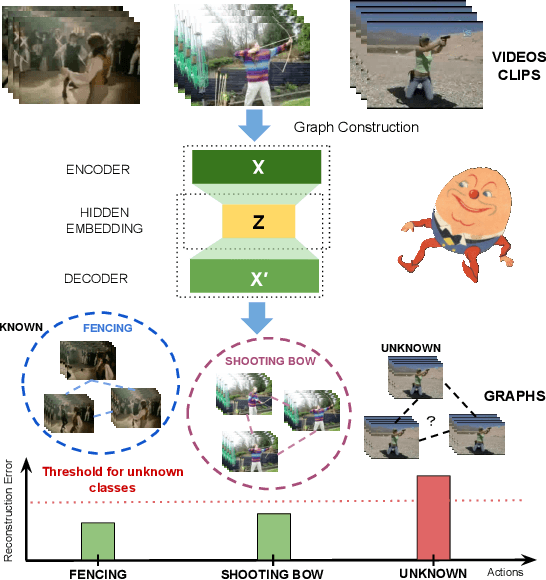


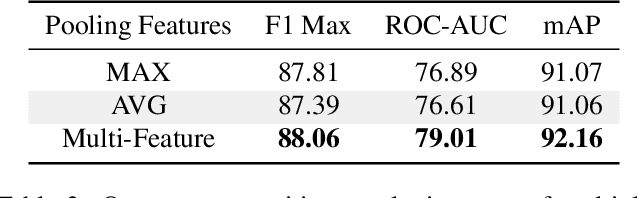
Most action recognition datasets and algorithms assume a closed world, where all test samples are instances of the known classes. In open set problems, test samples may be drawn from either known or unknown classes. Existing open set action recognition methods are typically based on extending closed set methods by adding post hoc analysis of classification scores or feature distances and do not capture the relations among all the video clip elements. Our approach uses the reconstruction error to determine the novelty of the video since unknown classes are harder to put back together and thus have a higher reconstruction error than videos from known classes. We refer to our solution to the open set action recognition problem as "Humpty Dumpty", due to its reconstruction abilities. Humpty Dumpty is a novel graph-based autoencoder that accounts for contextual and semantic relations among the clip pieces for improved reconstruction. A larger reconstruction error leads to an increased likelihood that the action can not be reconstructed, i.e., can not put Humpty Dumpty back together again, indicating that the action has never been seen before and is novel/unknown. Extensive experiments are performed on two publicly available action recognition datasets including HMDB-51 and UCF-101, showing the state-of-the-art performance for open set action recognition.
Vector Learning for Cross Domain Representations
Sep 27, 2018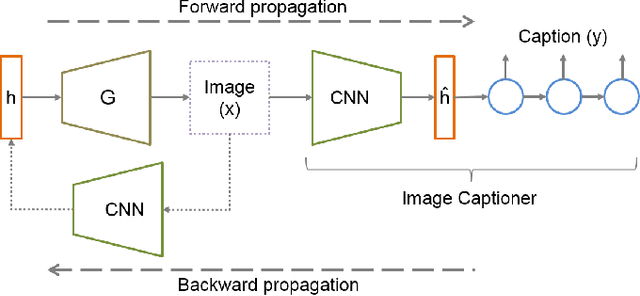


Recently, generative adversarial networks have gained a lot of popularity for image generation tasks. However, such models are associated with complex learning mechanisms and demand very large relevant datasets. This work borrows concepts from image and video captioning models to form an image generative framework. The model is trained in a similar fashion as recurrent captioning model and uses the learned weights for image generation. This is done in an inverse direction, where the input is a caption and the output is an image. The vector representation of the sentence and frames are extracted from an encoder-decoder model which is initially trained on similar sentence and image pairs. Our model conditions image generation on a natural language caption. We leverage a sequence-to-sequence model to generate synthetic captions that have the same meaning for having a robust image generation. One key advantage of our method is that the traditional image captioning datasets can be used for synthetic sentence paraphrases. Results indicate that images generated through multiple captions are better at capturing the semantic meaning of the family of captions.
Semantically Invariant Text-to-Image Generation
Sep 27, 2018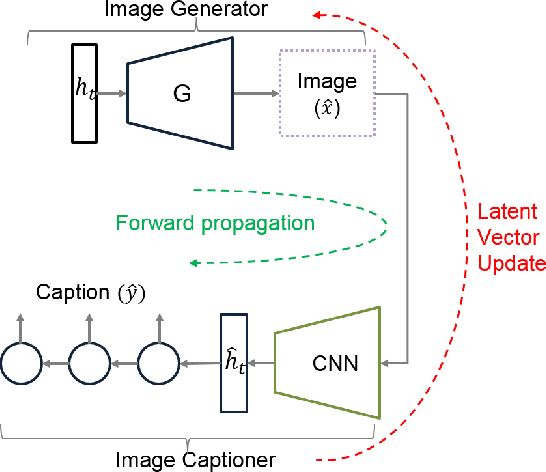
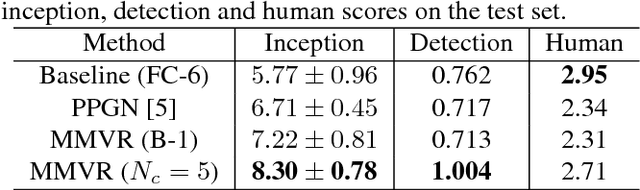

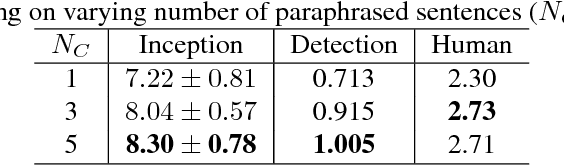
Image captioning has demonstrated models that are capable of generating plausible text given input images or videos. Further, recent work in image generation has shown significant improvements in image quality when text is used as a prior. Our work ties these concepts together by creating an architecture that can enable bidirectional generation of images and text. We call this network Multi-Modal Vector Representation (MMVR). Along with MMVR, we propose two improvements to the text conditioned image generation. Firstly, a n-gram metric based cost function is introduced that generalizes the caption with respect to the image. Secondly, multiple semantically similar sentences are shown to help in generating better images. Qualitative and quantitative evaluations demonstrate that MMVR improves upon existing text conditioned image generation results by over 20%, while integrating visual and text modalities.