 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Activity Recognition in an Open World
Dec 23, 2022
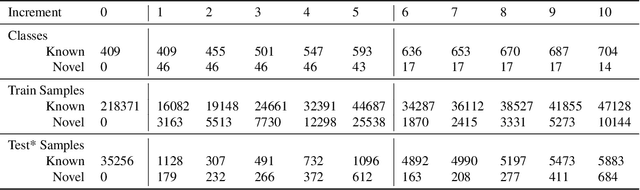

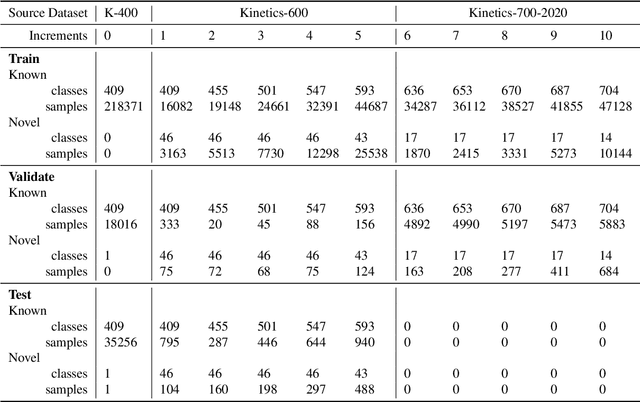
Managing novelty in perception-based human activity recognition (HAR) is critical in realistic settings to improve task performance over time and ensure solution generalization outside of prior seen samples. Novelty manifests in HAR as unseen samples, activities, objects, environments, and sensor changes, among other ways. Novelty may be task-relevant, such as a new class or new features, or task-irrelevant resulting in nuisance novelty, such as never before seen noise, blur, or distorted video recordings. To perform HAR optimally, algorithmic solutions must be tolerant to nuisance novelty, and learn over time in the face of novelty. This paper 1) formalizes the definition of novelty in HAR building upon the prior definition of novelty in classification tasks, 2) proposes an incremental open world learning (OWL) protocol and applies it to the Kinetics datasets to generate a new benchmark KOWL-718, 3) analyzes the performance of current state-of-the-art HAR models when novelty is introduced over time, 4) provides a containerized and packaged pipeline for reproducing the OWL protocol and for modifying for any future updates to Kinetics. The experimental analysis includes an ablation study of how the different models perform under various conditions as annotated by Kinetics-AVA. The protocol as an algorithm for reproducing experiments using the KOWL-718 benchmark will be publicly released with code and containers at https://github.com/prijatelj/human-activity-recognition-in-an-open-world. The code may be used to analyze different annotations and subsets of the Kinetics datasets in an incremental open world fashion, as well as be extended as further updates to Kinetics are released.
Handwriting Recognition with Novelty
May 17, 2021
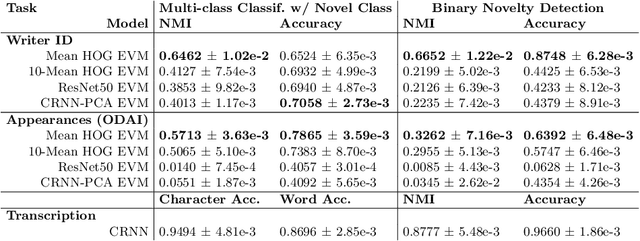

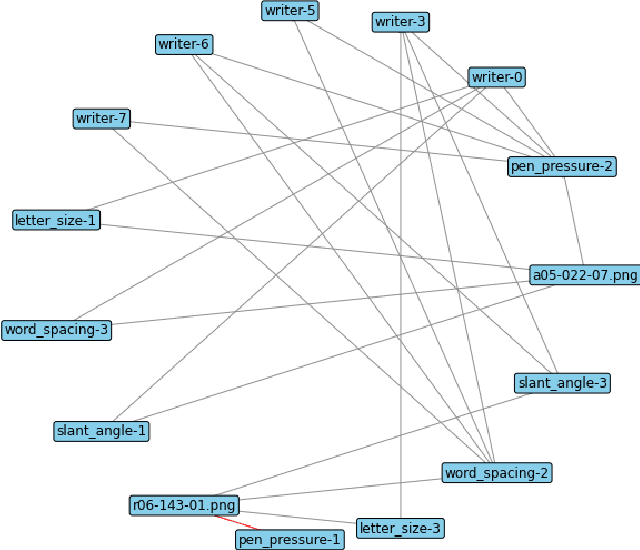
This paper introduces an agent-centric approach to handle novelty in the visual recognition domain of handwriting recognition (HWR). An ideal transcription agent would rival or surpass human perception, being able to recognize known and new characters in an image, and detect any stylistic changes that may occur within or across documents. A key confound is the presence of novelty, which has continued to stymie even the best machine learning-based algorithms for these tasks. In handwritten documents, novelty can be a change in writer, character attributes, writing attributes, or overall document appearance, among other things. Instead of looking at each aspect independently, we suggest that an integrated agent that can process known characters and novelties simultaneously is a better strategy. This paper formalizes the domain of handwriting recognition with novelty, describes a baseline agent, introduces an evaluation protocol with benchmark data, and provides experimentation to set the state-of-the-art. Results show feasibility for the agent-centric approach, but more work is needed to approach human-levels of reading ability, giving the HWR community a formal basis to build upon as they solve this challenging problem.
Measuring Human Perception to Improve Handwritten Document Transcription
Apr 10, 2019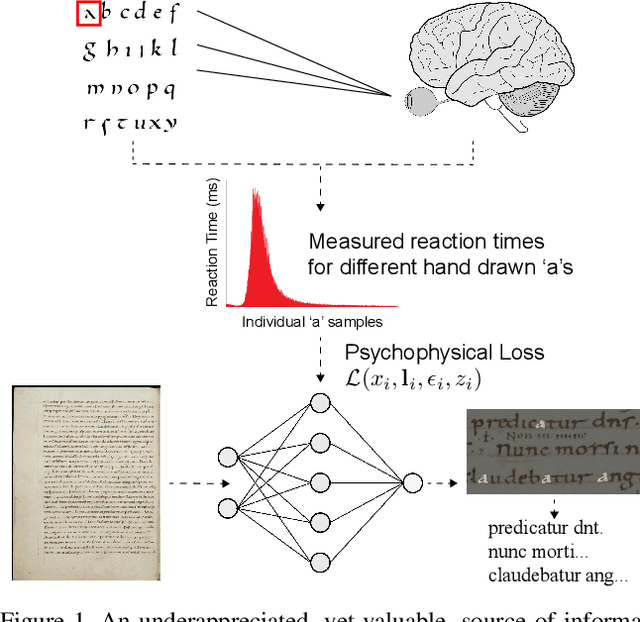

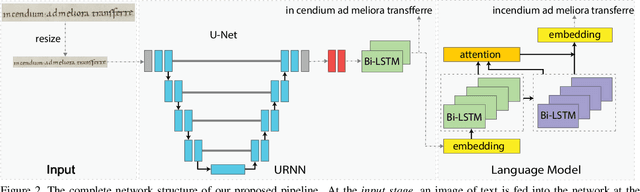

The subtleties of human perception, as measured by vision scientists through the use of psychophysics, are important clues to the internal workings of visual recognition. For instance, measured reaction time can indicate whether a visual stimulus is easy for a subject to recognize, or whether it is hard. In this paper, we consider how to incorporate psychophysical measurements of visual perception into the loss function of a deep neural network being trained for a recognition task, under the assumption that such information can enforce consistency with human behavior. As a case study to assess the viability of this approach, we look at the problem of handwritten document transcription. While good progress has been made towards automatically transcribing modern handwriting, significant challenges remain in transcribing historical documents. Here we work towards a comprehensive transcription solution for Medieval manuscripts that combines networks trained using our novel loss formulation with natural language processing elements. In a baseline assessment, reliable performance is demonstrated for the standard IAM and RIMES datasets. Further, we go on to show feasibility for our approach on a previously published dataset and a new dataset of digitized Latin manuscripts, originally produced by scribes in the Cloister of St. Gall around the middle of the 9th century.