 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Guardrails for Open-World Decision Making in Autonomous Drone Swarms
May 29, 2025
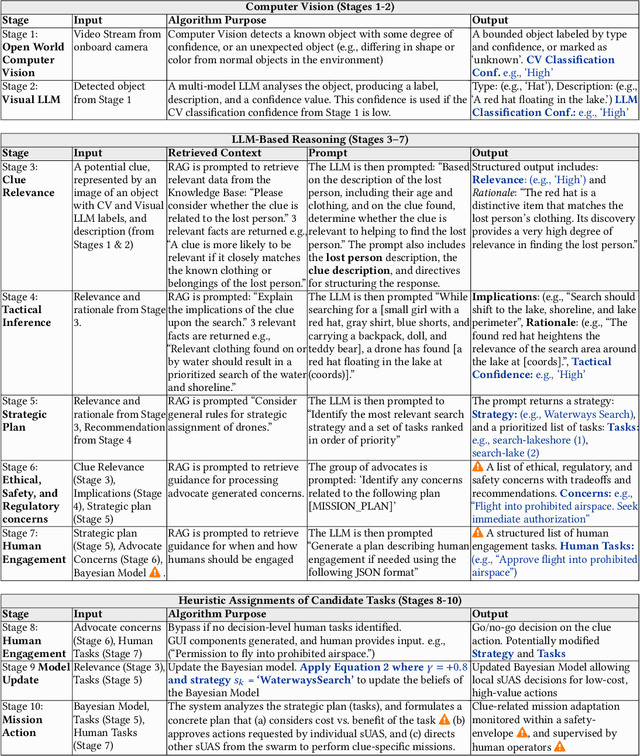

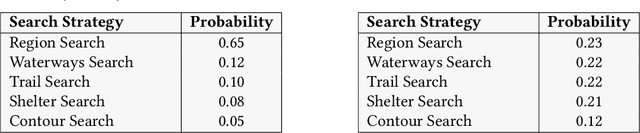
Small Uncrewed Aerial Systems (sUAS) are increasingly deployed as autonomous swarms in search-and-rescue and other disaster-response scenarios. In these settings, they use computer vision (CV) to detect objects of interest and autonomously adapt their missions. However, traditional CV systems often struggle to recognize unfamiliar objects in open-world environments or to infer their relevance for mission planning. To address this, we incorporate large language models (LLMs) to reason about detected objects and their implications. While LLMs can offer valuable insights, they are also prone to hallucinations and may produce incorrect, misleading, or unsafe recommendations. To ensure safe and sensible decision-making under uncertainty, high-level decisions must be governed by cognitive guardrails. This article presents the design, simulation, and real-world integration of these guardrails for sUAS swarms in search-and-rescue missions.
Story Grammar Semantic Matching for Literary Study
Feb 17, 2025
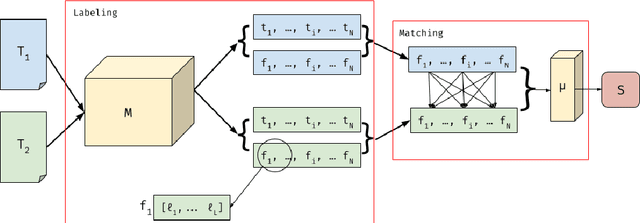
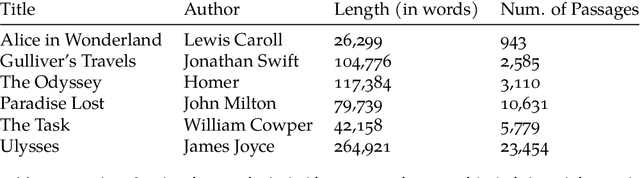
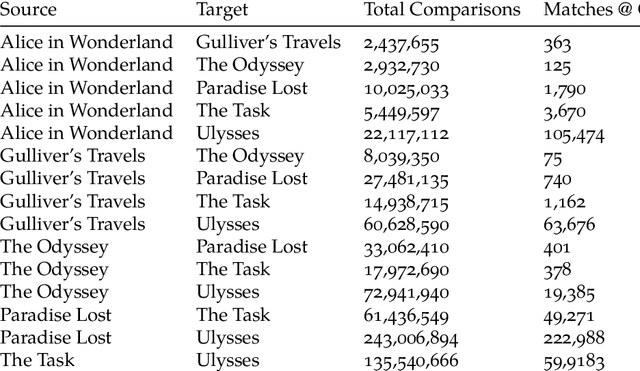
In Natural Language Processing (NLP), semantic matching algorithms have traditionally relied on the feature of word co-occurrence to measure semantic similarity. While this feature approach has proven valuable in many contexts, its simplistic nature limits its analytical and explanatory power when used to understand literary texts. To address these limitations, we propose a more transparent approach that makes use of story structure and related elements. Using a BERT language model pipeline, we label prose and epic poetry with story element labels and perform semantic matching by only considering these labels as features. This new method, Story Grammar Semantic Matching, guides literary scholars to allusions and other semantic similarities across texts in a way that allows for characterizing patterns and literary technique.
Psych-Occlusion: Using Visual Psychophysics for Aerial Detection of Occluded Persons during Search and Rescue
Dec 07, 2024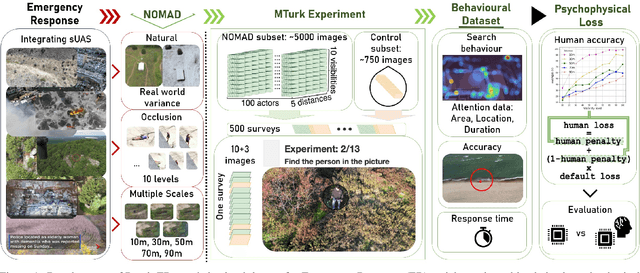



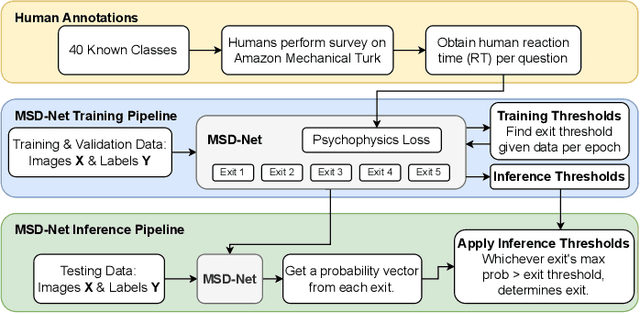
The success of Emergency Response (ER) scenarios, such as search and rescue, is often dependent upon the prompt location of a lost or injured person. With the increasing use of small Unmanned Aerial Systems (sUAS) as "eyes in the sky" during ER scenarios, efficient detection of persons from aerial views plays a crucial role in achieving a successful mission outcome. Fatigue of human operators during prolonged ER missions, coupled with limited human resources, highlights the need for sUAS equipped with Computer Vision (CV) capabilities to aid in finding the person from aerial views. However, the performance of CV models onboard sUAS substantially degrades under real-life rigorous conditions of a typical ER scenario, where person search is hampered by occlusion and low target resolution. To address these challenges, we extracted images from the NOMAD dataset and performed a crowdsource experiment to collect behavioural measurements when humans were asked to "find the person in the picture". We exemplify the use of our behavioral dataset, Psych-ER, by using its human accuracy data to adapt the loss function of a detection model. We tested our loss adaptation on a RetinaNet model evaluated on NOMAD against increasing distance and occlusion, with our psychophysical loss adaptation showing improvements over the baseline at higher distances across different levels of occlusion, without degrading performance at closer distances. To the best of our knowledge, our work is the first human-guided approach to address the location task of a detection model, while addressing real-world challenges of aerial search and rescue. All datasets and code can be found at: https://github.com/ArtRuss/NOMAD.
N-Modal Contrastive Losses with Applications to Social Media Data in Trimodal Space
Mar 18, 2024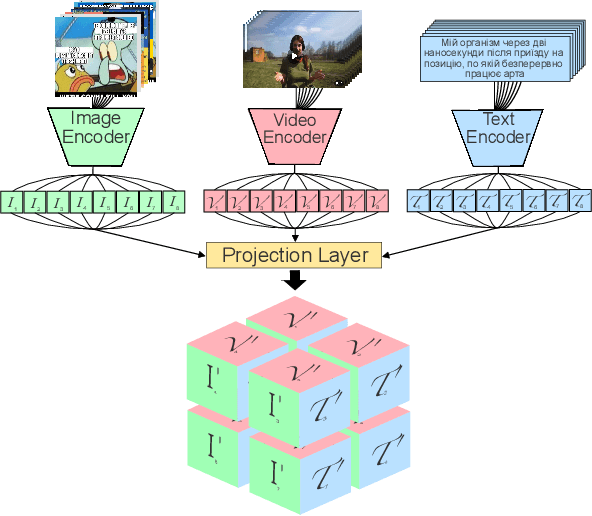
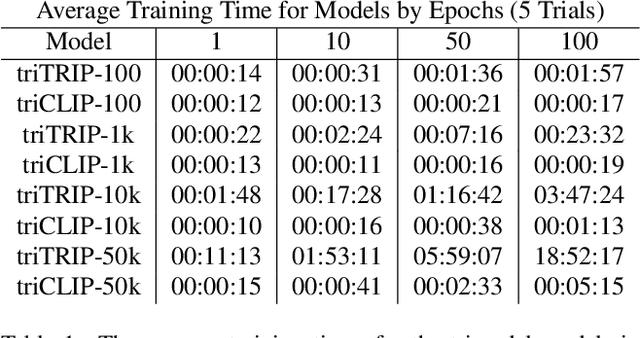
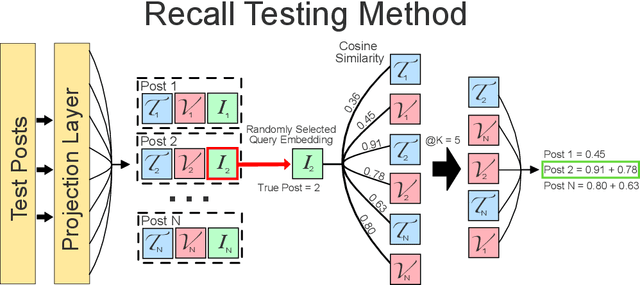

The social media landscape of conflict dynamics has grown increasingly multi-modal. Recent advancements in model architectures such as CLIP have enabled researchers to begin studying the interplay between the modalities of text and images in a shared latent space. However, CLIP models fail to handle situations on social media when modalities present in a post expand above two. Social media dynamics often require understanding the interplay between not only text and images, but video as well. In this paper we explore an extension of the contrastive loss function to allow for any number of modalities, and demonstrate its usefulness in trimodal spaces on social media. By extending CLIP into three dimensions we can further aide understanding social media landscapes where all three modalities are present (an increasingly common situation). We use a newly collected public data set of Telegram posts containing all three modalities to train, and then demonstrate the usefulness of, a trimodal model in two OSINT scenarios: classifying a social media artifact post as either pro-Russian or pro-Ukrainian and identifying which account a given artifact originated from. While trimodal CLIP models have been explored before (though not on social media data), we also display a novel quadmodal CLIP model. This model can learn the interplay between text, image, video, and audio. We demonstrate new state-of-the-art baseline results on retrieval for quadmodel models moving forward.
Pixel-Grounded Prototypical Part Networks
Sep 25, 2023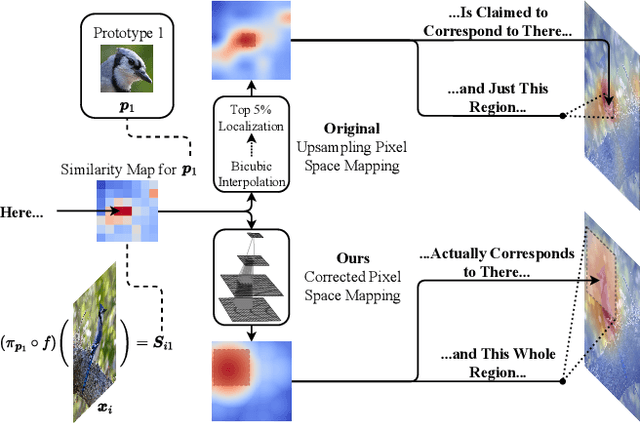
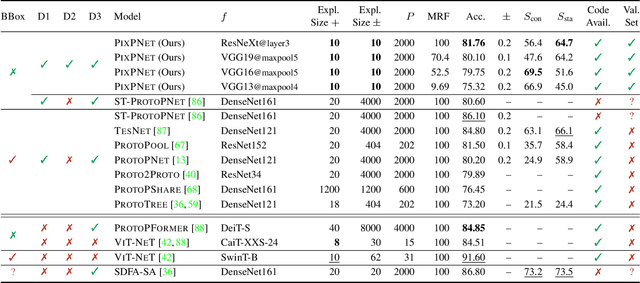
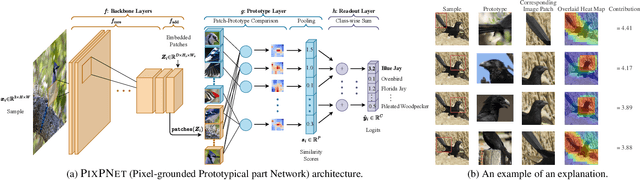
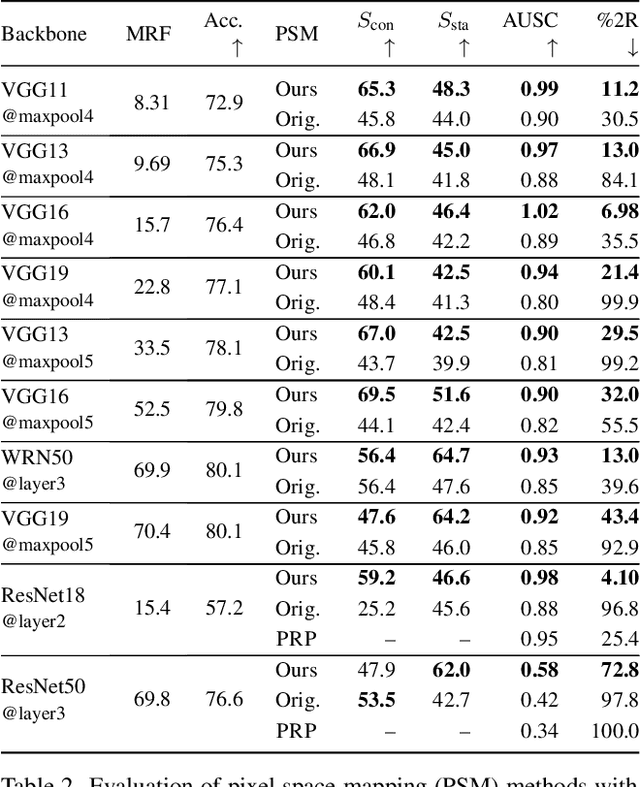
Prototypical part neural networks (ProtoPartNNs), namely PROTOPNET and its derivatives, are an intrinsically interpretable approach to machine learning. Their prototype learning scheme enables intuitive explanations of the form, this (prototype) looks like that (testing image patch). But, does this actually look like that? In this work, we delve into why object part localization and associated heat maps in past work are misleading. Rather than localizing to object parts, existing ProtoPartNNs localize to the entire image, contrary to generated explanatory visualizations. We argue that detraction from these underlying issues is due to the alluring nature of visualizations and an over-reliance on intuition. To alleviate these issues, we devise new receptive field-based architectural constraints for meaningful localization and a principled pixel space mapping for ProtoPartNNs. To improve interpretability, we propose additional architectural improvements, including a simplified classification head. We also make additional corrections to PROTOPNET and its derivatives, such as the use of a validation set, rather than a test set, to evaluate generalization during training. Our approach, PIXPNET (Pixel-grounded Prototypical part Network), is the only ProtoPartNN that truly learns and localizes to prototypical object parts. We demonstrate that PIXPNET achieves quantifiably improved interpretability without sacrificing accuracy.
NOMAD: A Natural, Occluded, Multi-scale Aerial Dataset, for Emergency Response Scenarios
Sep 18, 2023



With the increasing reliance on small Unmanned Aerial Systems (sUAS) for Emergency Response Scenarios, such as Search and Rescue, the integration of computer vision capabilities has become a key factor in mission success. Nevertheless, computer vision performance for detecting humans severely degrades when shifting from ground to aerial views. Several aerial datasets have been created to mitigate this problem, however, none of them has specifically addressed the issue of occlusion, a critical component in Emergency Response Scenarios. Natural Occluded Multi-scale Aerial Dataset (NOMAD) presents a benchmark for human detection under occluded aerial views, with five different aerial distances and rich imagery variance. NOMAD is composed of 100 different Actors, all performing sequences of walking, laying and hiding. It includes 42,825 frames, extracted from 5.4k resolution videos, and manually annotated with a bounding box and a label describing 10 different visibility levels, categorized according to the percentage of the human body visible inside the bounding box. This allows computer vision models to be evaluated on their detection performance across different ranges of occlusion. NOMAD is designed to improve the effectiveness of aerial search and rescue and to enhance collaboration between sUAS and humans, by providing a new benchmark dataset for human detection under occluded aerial views.
C-CLIP: Contrastive Image-Text Encoders to Close the Descriptive-Commentative Gap
Sep 06, 2023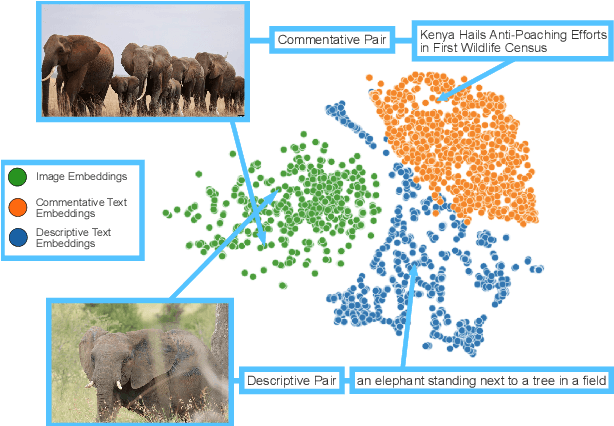


The interplay between the image and comment on a social media post is one of high importance for understanding its overall message. Recent strides in multimodal embedding models, namely CLIP, have provided an avenue forward in relating image and text. However the current training regime for CLIP models is insufficient for matching content found on social media, regardless of site or language. Current CLIP training data is based on what we call ``descriptive'' text: text in which an image is merely described. This is something rarely seen on social media, where the vast majority of text content is ``commentative'' in nature. The captions provide commentary and broader context related to the image, rather than describing what is in it. Current CLIP models perform poorly on retrieval tasks where image-caption pairs display a commentative relationship. Closing this gap would be beneficial for several important application areas related to social media. For instance, it would allow groups focused on Open-Source Intelligence Operations (OSINT) to further aid efforts during disaster events, such as the ongoing Russian invasion of Ukraine, by easily exposing data to non-technical users for discovery and analysis. In order to close this gap we demonstrate that training contrastive image-text encoders on explicitly commentative pairs results in large improvements in retrieval results, with the results extending across a variety of non-English languages.
Has the Virtualization of the Face Changed Facial Perception? A Study of the Impact of Augmented Reality on Facial Perception
Mar 01, 2023



Augmented reality and other photo editing filters are popular methods used to modify images, especially images of faces, posted online. Considering the important role of human facial perception in social communication, how does exposure to an increasing number of modified faces online affect human facial perception? In this paper we present the results of six surveys designed to measure familiarity with different styles of facial filters, perceived strangeness of faces edited with different facial filters, and ability to discern whether images are filtered or not. Our results indicate that faces filtered with photo editing filters that change the image color tones, modify facial structure, or add facial beautification tend to be perceived similarly to unmodified faces; however, faces filtered with augmented reality filters (\textit{i.e.,} filters that overlay digital objects) are perceived differently from unmodified faces. We also found that responses differed based on different survey question phrasings, indicating that the shift in facial perception due to the prevalence of filtered images is noisy to detect. A better understanding of shifts in facial perception caused by facial filters will help us build online spaces more responsibly and could inform the training of more accurate and equitable facial recognition models, especially those trained with human psychophysical annotations.
Measuring Human Perception to Improve Open Set Recognition
Sep 11, 2022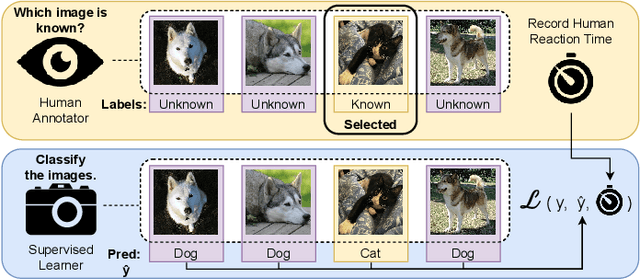

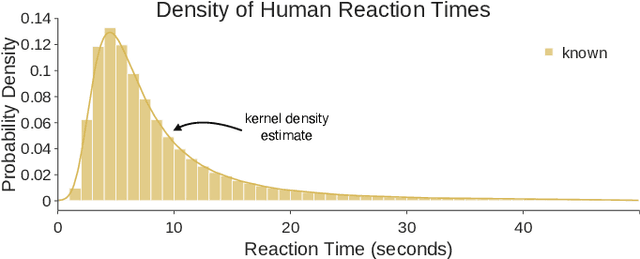
The human ability to recognize when an object is known or novel currently outperforms all open set recognition algorithms. Human perception as measured by the methods and procedures of visual psychophysics from psychology can provide an additional data stream for managing novelty in visual recognition tasks in computer vision. For instance, measured reaction time from human subjects can offer insight as to whether a known class sample may be confused with a novel one. In this work, we designed and performed a large-scale behavioral experiment that collected over 200,000 human reaction time measurements associated with object recognition. The data collected indicated reaction time varies meaningfully across objects at the sample level. We therefore designed a new psychophysical loss function that enforces consistency with human behavior in deep networks which exhibit variable reaction time for different images. As in biological vision, this approach allows us to achieve good open set recognition performance in regimes with limited labeled training data. Through experiments using data from ImageNet, significant improvement is observed when training Multi-Scale DenseNets with this new formulation: models trained with our loss function significantly improved top-1 validation accuracy by 7%, top-1 test accuracy on known samples by 18%, and top-1 test accuracy on unknown samples by 33%. We compared our method to 10 open set recognition methods from the literature, which were all outperformed on multiple metrics.
Analyzing the Impact of Shape & Context on the Face Recognition Performance of Deep Networks
Aug 05, 2022
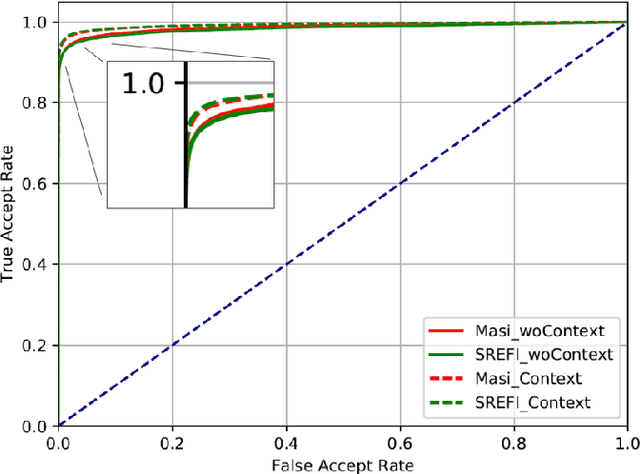
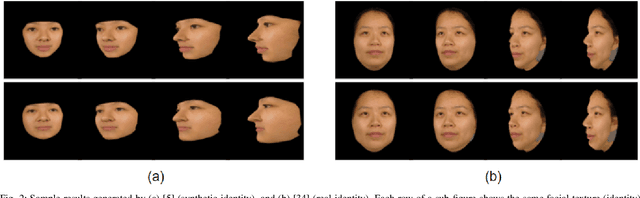
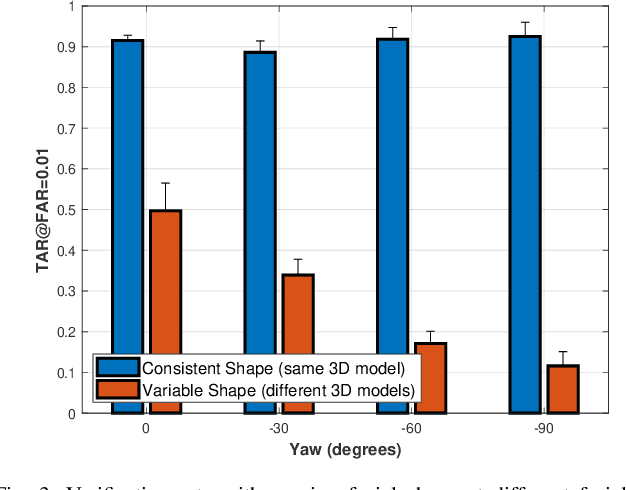
In this article, we analyze how changing the underlying 3D shape of the base identity in face images can distort their overall appearance, especially from the perspective of deep face recognition. As done in popular training data augmentation schemes, we graphically render real and synthetic face images with randomly chosen or best-fitting 3D face models to generate novel views of the base identity. We compare deep features generated from these images to assess the perturbation these renderings introduce into the original identity. We perform this analysis at various degrees of facial yaw with the base identities varying in gender and ethnicity. Additionally, we investigate if adding some form of context and background pixels in these rendered images, when used as training data, further improves the downstream performance of a face recognition model. Our experiments demonstrate the significance of facial shape in accurate face matching and underpin the importance of contextual data for network training.