 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-CLIP: Contrastive Image-Text Encoders to Close the Descriptive-Commentative Gap
Paper and Code
Sep 06, 2023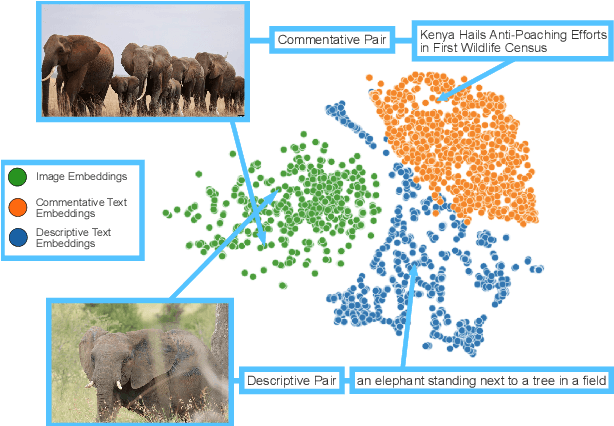


The interplay between the image and comment on a social media post is one of high importance for understanding its overall message. Recent strides in multimodal embedding models, namely CLIP, have provided an avenue forward in relating image and text. However the current training regime for CLIP models is insufficient for matching content found on social media, regardless of site or language. Current CLIP training data is based on what we call ``descriptive'' text: text in which an image is merely described. This is something rarely seen on social media, where the vast majority of text content is ``commentative'' in nature. The captions provide commentary and broader context related to the image, rather than describing what is in it. Current CLIP models perform poorly on retrieval tasks where image-caption pairs display a commentative relationship. Closing this gap would be beneficial for several important application areas related to social media. For instance, it would allow groups focused on Open-Source Intelligence Operations (OSINT) to further aid efforts during disaster events, such as the ongoing Russian invasion of Ukraine, by easily exposing data to non-technical users for discovery and analysis. In order to close this gap we demonstrate that training contrastive image-text encoders on explicitly commentative pairs results in large improvements in retrieval results, with the results extending across a variety of non-English languages.