 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssemblyBench: Physics-Aware Assembly of Complex Industrial Objects
May 13, 2026Assembling objects from parts requires understanding multimodal instructions, linking them to 3D components, and predicting physically plausible 6-DoF motions for each assembly step. Existing datasets focus on simplified scenarios, overlooking shape complexities and assembly trajectories in industrial assemblies. We introduce AssemblyBench, a synthetic dataset of 2,789 industrial objects with multimodal instruction manuals, corresponding 3D part models, and part assembly trajectories. We also propose a transformer-based model, AssemblyDyno, which uses the instructional manual and the 3D shape of each part to jointly predict assembly order and part assembly trajectories. AssemblyDyno outperforms prior works in both assembly pose estimation and trajectory feasibility, where the latter is evaluated by our physics-based simulations.
Understanding Dynamic Compute Allocation in Recurrent Transformers
Feb 09, 2026Token-level adaptive computation seeks to reduce inference cost by allocating more computation to harder tokens and less to easier ones. However, prior work is primarily evaluated on natural-language benchmarks using task-level metrics, where token-level difficulty is unobservable and confounded with architectural factors, making it unclear whether compute allocation truly aligns with underlying complexity. We address this gap through three contributions. First, we introduce a complexity-controlled evaluation paradigm using algorithmic and synthetic language tasks with parameterized difficulty, enabling direct testing of token-level compute allocation. Second, we propose ANIRA, a unified recurrent Transformer framework that supports per-token variable-depth computation while isolating compute allocation decisions from other model factors. Third, we use this framework to conduct a systematic analysis of token-level adaptive computation across alignment with complexity, generalization, and decision timing. Our results show that compute allocation aligned with task complexity can emerge without explicit difficulty supervision, but such alignment does not imply algorithmic generalization: models fail to extrapolate to unseen input sizes despite allocating additional computation. We further find that early compute decisions rely on static structural cues, whereas online halting more closely tracks algorithmic execution state.
Auto-Vocabulary 3D Object Detection
Dec 18, 2025



Open-vocabulary 3D object detection methods are able to localize 3D boxes of classes unseen during training. Despite the name, existing methods rely on user-specified classes both at training and inference. We propose to study Auto-Vocabulary 3D Object Detection (AV3DOD), where the classes are automatically generated for the detected objects without any user input. To this end, we introduce Semantic Score (SS) to evaluate the quality of the generated class names. We then develop a novel framework, AV3DOD, which leverages 2D vision-language models (VLMs) to generate rich semantic candidates through image captioning, pseudo 3D box generation, and feature-space semantics expansion. AV3DOD achieves the state-of-the-art (SOTA) performance on both localization (mAP) and semantic quality (SS) on the ScanNetV2 and SUNRGB-D datasets. Notably, it surpasses the SOTA, CoDA, by 3.48 overall mAP and attains a 24.5% relative improvement in SS on ScanNetV2.
Programmatic Video Prediction Using Large Language Models
May 20, 2025The task of estimating the world model describing the dynamics of a real world process assumes immense importance for anticipating and preparing for future outcomes. For applications such as video surveillance, robotics applications, autonomous driving, etc. this objective entails synthesizing plausible visual futures, given a few frames of a video to set the visual context. Towards this end, we propose ProgGen, which undertakes the task of video frame prediction by representing the dynamics of the video using a set of neuro-symbolic, human-interpretable set of states (one per frame) by leveraging the inductive biases of Large (Vision) Language Models (LLM/VLM). In particular, ProgGen utilizes LLM/VLM to synthesize programs: (i) to estimate the states of the video, given the visual context (i.e. the frames); (ii) to predict the states corresponding to future time steps by estimating the transition dynamics; (iii) to render the predicted states as visual RGB-frames. Empirical evaluations reveal that our proposed method outperforms competing techniques at the task of video frame prediction in two challenging environments: (i) PhyWorld (ii) Cart Pole. Additionally, ProgGen permits counter-factual reasoning and interpretable video generation attesting to its effectiveness and generalizability for video generation tasks.
FreBIS: Frequency-Based Stratification for Neural Implicit Surface Representations
Apr 28, 2025Neural implicit surface representation techniques are in high demand for advancing technologies in augmented reality/virtual reality, digital twins, autonomous navigation, and many other fields. With their ability to model object surfaces in a scene as a continuous function, such techniques have made remarkable strides recently, especially over classical 3D surface reconstruction methods, such as those that use voxels or point clouds. However, these methods struggle with scenes that have varied and complex surfaces principally because they model any given scene with a single encoder network that is tasked to capture all of low through high-surface frequency information in the scene simultaneously. In this work, we propose a novel, neural implicit surface representation approach called FreBIS to overcome this challenge. FreBIS works by stratifying the scene based on the frequency of surfaces into multiple frequency levels, with each level (or a group of levels) encoded by a dedicated encoder. Moreover, FreBIS encourages these encoders to capture complementary information by promoting mutual dissimilarity of the encoded features via a novel, redundancy-aware weighting module. Empirical evaluations on the challenging BlendedMVS dataset indicate that replacing the standard encoder in an off-the-shelf neural surface reconstruction method with our frequency-stratified encoders yields significant improvements. These enhancements are evident both in the quality of the reconstructed 3D surfaces and in the fidelity of their renderings from any viewpoint.
Multimodal Diffusion Bridge with Attention-Based SAR Fusion for Satellite Image Cloud Removal
Apr 04, 2025Deep learning has achieved some success in addressing the challenge of cloud removal in optical satellite images, by fusing with synthetic aperture radar (SAR) images. Recently, diffusion models have emerged as powerful tools for cloud removal, delivering higher-quality estimation by sampling from cloud-free distributions, compared to earlier methods. However, diffusion models initiate sampling from pure Gaussian noise, which complicates the sampling trajectory and results in suboptimal performance. Also, current methods fall short in effectively fusing SAR and optical data. To address these limitations, we propose Diffusion Bridges for Cloud Removal, DB-CR, which directly bridges between the cloudy and cloud-free image distributions. In addition, we propose a novel multimodal diffusion bridge architecture with a two-branch backbone for multimodal image restoration, incorporating an efficient backbone and dedicated cross-modality fusion blocks to effectively extract and fuse features from synthetic aperture radar (SAR) and optical images. By formulating cloud removal as a diffusion-bridge problem and leveraging this tailored architecture, DB-CR achieves high-fidelity results while being computationally efficient. We evaluated DB-CR on the SEN12MS-CR cloud-removal dataset, demonstrating that it achieves state-of-the-art results.
Recovering Pulse Waves from Video Using Deep Unrolling and Deep Equilibrium Models
Mar 21, 2025Camera-based monitoring of vital signs, also known as imaging photoplethysmography (iPPG), has seen applications in driver-monitoring, perfusion assessment in surgical settings, affective computing, and more. iPPG involves sensing the underlying cardiac pulse from video of the skin and estimating vital signs such as the heart rate or a full pulse waveform. Some previous iPPG methods impose model-based sparse priors on the pulse signals and use iterative optimization for pulse wave recovery, while others use end-to-end black-box deep learning methods. In contrast, we introduce methods that combine signal processing and deep learning methods in an inverse problem framework. Our methods estimate the underlying pulse signal and heart rate from facial video by learning deep-network-based denoising operators that leverage deep algorithm unfolding and deep equilibrium models. Experiments show that our methods can denoise an acquired signal from the face and infer the correct underlying pulse rate, achieving state-of-the-art heart rate estimation performance on well-known benchmarks, all with less than one-fifth the number of learnable parameters as the closest competing method.
Time-Series U-Net with Recurrence for Noise-Robust Imaging Photoplethysmography
Mar 21, 2025Remote estimation of vital signs enables health monitoring for situations in which contact-based devices are either not available, too intrusive, or too expensive. In this paper, we present a modular, interpretable pipeline for pulse signal estimation from video of the face that achieves state-of-the-art results on publicly available datasets.Our imaging photoplethysmography (iPPG) system consists of three modules: face and landmark detection, time-series extraction, and pulse signal/pulse rate estimation. Unlike many deep learning methods that make use of a single black-box model that maps directly from input video to output signal or heart rate, our modular approach enables each of the three parts of the pipeline to be interpreted individually. The pulse signal estimation module, which we call TURNIP (Time-Series U-Net with Recurrence for Noise-Robust Imaging Photoplethysmography), allows the system to faithfully reconstruct the underlying pulse signal waveform and uses it to measure heart rate and pulse rate variability metrics, even in the presence of motion. When parts of the face are occluded due to extreme head poses, our system explicitly detects such "self-occluded" regions and maintains estimation robustness despite the missing information. Our algorithm provides reliable heart rate estimates without the need for specialized sensors or contact with the skin, outperforming previous iPPG methods on both color (RGB) and near-infrared (NIR) datasets.
Evaluating Large Vision-and-Language Models on Children's Mathematical Olympiads
Jun 22, 2024Recent years have seen a significant progress in the general-purpose problem solving abilities of large vision and language models (LVLMs), such as ChatGPT, Gemini, etc.; some of these breakthroughs even seem to enable AI models to outperform human abilities in varied tasks that demand higher-order cognitive skills. Are the current large AI models indeed capable of generalized problem solving as humans do? A systematic analysis of AI capabilities for joint vision and text reasoning, however, is missing in the current scientific literature. In this paper, we make an effort towards filling this gap, by evaluating state-of-the-art LVLMs on their mathematical and algorithmic reasoning abilities using visuo-linguistic problems from children's Olympiads. Specifically, we consider problems from the Mathematical Kangaroo (MK) Olympiad, which is a popular international competition targeted at children from grades 1-12, that tests children's deeper mathematical abilities using puzzles that are appropriately gauged to their age and skills. Using the puzzles from MK, we created a dataset, dubbed SMART-840, consisting of 840 problems from years 2020-2024. With our dataset, we analyze LVLMs power on mathematical reasoning; their responses on our puzzles offer a direct way to compare against that of children. Our results show that modern LVLMs do demonstrate increasingly powerful reasoning skills in solving problems for higher grades, but lack the foundations to correctly answer problems designed for younger children. Further analysis shows that there is no significant correlation between the reasoning capabilities of AI models and that of young children, and their capabilities appear to be based on a different type of reasoning than the cumulative knowledge that underlies children's mathematics and logic skills.
Gear-NeRF: Free-Viewpoint Rendering and Tracking with Motion-aware Spatio-Temporal Sampling
Jun 06, 2024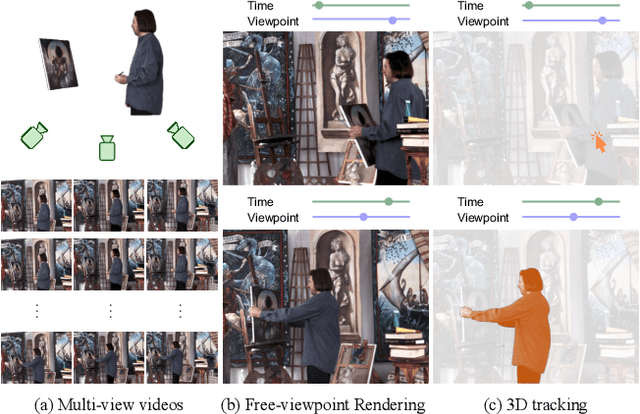
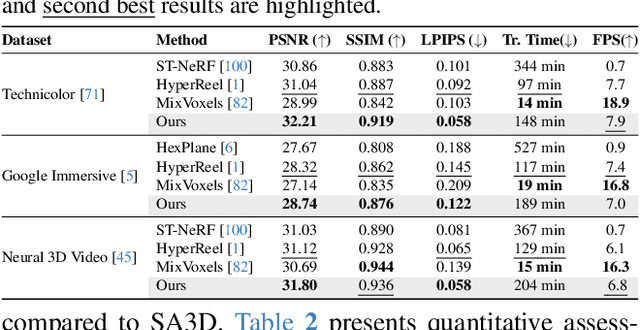
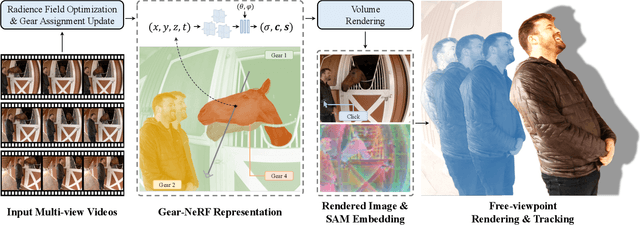
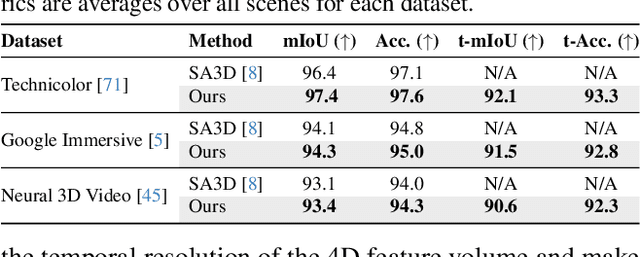
Extensions of Neural Radiance Fields (NeRFs) to model dynamic scenes have enabled their near photo-realistic, free-viewpoint rendering. Although these methods have shown some potential in creating immersive experiences, two drawbacks limit their ubiquity: (i) a significant reduction in reconstruction quality when the computing budget is limited, and (ii) a lack of semantic understanding of the underlying scenes. To address these issues, we introduce Gear-NeRF, which leverages semantic information from powerful image segmentation models. Our approach presents a principled way for learning a spatio-temporal (4D) semantic embedding, based on which we introduce the concept of gears to allow for stratified modeling of dynamic regions of the scene based on the extent of their motion. Such differentiation allows us to adjust the spatio-temporal sampling resolution for each region in proportion to its motion scale, achieving more photo-realistic dynamic novel view synthesis. At the same time, almost for free, our approach enables free-viewpoint tracking of objects of interest - a functionality not yet achieved by existing NeRF-based methods. Empirical studies validate the effectiveness of our method, where we achieve state-of-the-art rendering and tracking performance on multiple challenging datasets.