 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Series U-Net with Recurrence for Noise-Robust Imaging Photoplethysmography
Mar 21, 2025Remote estimation of vital signs enables health monitoring for situations in which contact-based devices are either not available, too intrusive, or too expensive. In this paper, we present a modular, interpretable pipeline for pulse signal estimation from video of the face that achieves state-of-the-art results on publicly available datasets.Our imaging photoplethysmography (iPPG) system consists of three modules: face and landmark detection, time-series extraction, and pulse signal/pulse rate estimation. Unlike many deep learning methods that make use of a single black-box model that maps directly from input video to output signal or heart rate, our modular approach enables each of the three parts of the pipeline to be interpreted individually. The pulse signal estimation module, which we call TURNIP (Time-Series U-Net with Recurrence for Noise-Robust Imaging Photoplethysmography), allows the system to faithfully reconstruct the underlying pulse signal waveform and uses it to measure heart rate and pulse rate variability metrics, even in the presence of motion. When parts of the face are occluded due to extreme head poses, our system explicitly detects such "self-occluded" regions and maintains estimation robustness despite the missing information. Our algorithm provides reliable heart rate estimates without the need for specialized sensors or contact with the skin, outperforming previous iPPG methods on both color (RGB) and near-infrared (NIR) datasets.
Geometry of Score Based Generative Models
Feb 09, 2023In this work, we look at Score-based generative models (also called diffusion generative models) from a geometric perspective. From a new view point, we prove that both the forward and backward process of adding noise and generating from noise are Wasserstein gradient flow in the space of probability measures. We are the first to prove this connection. Our understanding of Score-based (and Diffusion) generative models have matured and become more complete by drawing ideas from different fields like Bayesian inference, control theory, stochastic differential equation and Schrodinger bridge. However, many open questions and challenges remain. One problem, for example, is how to decrease the sampling time? We demonstrate that looking from geometric perspective enables us to answer many of these questions and provide new interpretations to some known results. Furthermore, geometric perspective enables us to devise an intuitive geometric solution to the problem of faster sampling. By augmenting traditional score-based generative models with a projection step, we show that we can generate high quality images with significantly fewer sampling-steps.
Divide and Compose with Score Based Generative Models
Feb 05, 2023While score based generative models, or diffusion models, have found success in image synthesis, they are often coupled with text data or image label to be able to manipulate and conditionally generate images. Even though manipulation of images by changing the text prompt is possible, our understanding of the text embedding and our ability to modify it to edit images is quite limited. Towards the direction of having more control over image manipulation and conditional generation, we propose to learn image components in an unsupervised manner so that we can compose those components to generate and manipulate images in informed manner. Taking inspiration from energy based models, we interpret different score components as the gradient of different energy functions. We show how score based learning allows us to learn interesting components and we can visualize them through generation. We also show how this novel decomposition allows us to compose, generate and modify images in interesting ways akin to dreaming. We make our code available at https://github.com/sandeshgh/Score-based-disentanglement
Self-Supervised Decomposition, Disentanglement and Prediction of Video Sequences while Interpreting Dynamics: A Koopman Perspective
Oct 01, 2021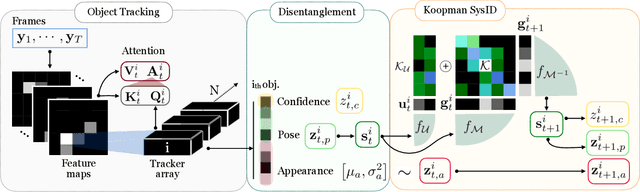
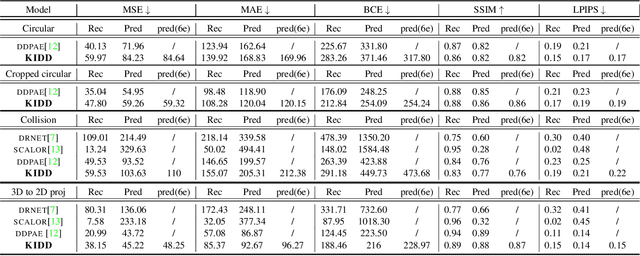
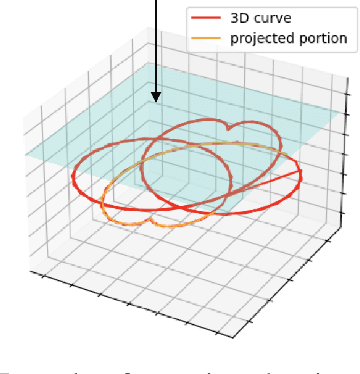

Human interpretation of the world encompasses the use of symbols to categorize sensory inputs and compose them in a hierarchical manner. One of the long-term objectives of Computer Vision and Artificial Intelligence is to endow machines with the capacity of structuring and interpreting the world as we do. Towards this goal, recent methods have successfully been able to decompose and disentangle video sequences into their composing objects and dynamics, in a self-supervised fashion. However, there has been a scarce effort in giving interpretation to the dynamics of the scene. We propose a method to decompose a video into moving objects and their attributes, and model each object's dynamics with linear system identification tools, by means of a Koopman embedding. This allows interpretation, manipulation and extrapolation of the dynamics of the different objects by employing the Koopman operator K. We test our method in various synthetic datasets and successfully forecast challenging trajectories while interpreting them.