 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Masked Jigsaw Puzzles with Diffusion Vision Transformers
Apr 10, 2024



Solving image and video jigsaw puzzles poses the challenging task of rearranging image fragments or video frames from unordered sequences to restore meaningful images and video sequences. Existing approaches often hinge on discriminative models tasked with predicting either the absolute positions of puzzle elements or the permutation actions applied to the original data. Unfortunately, these methods face limitations in effectively solving puzzles with a large number of elements. In this paper, we propose JPDVT, an innovative approach that harnesses diffusion transformers to address this challenge. Specifically, we generate positional information for image patches or video frames, conditioned on their underlying visual content. This information is then employed to accurately assemble the puzzle pieces in their correct positions, even in scenarios involving missing pieces. Our method achieves state-of-the-art performance on several datasets.
Inferring Relational Potentials in Interacting Systems
Oct 23, 2023Systems consisting of interacting agents are prevalent in the world, ranging from dynamical systems in physics to complex biological networks. To build systems which can interact robustly in the real world, it is thus important to be able to infer the precise interactions governing such systems. Existing approaches typically discover such interactions by explicitly modeling the feed-forward dynamics of the trajectories. In this work, we propose Neural Interaction Inference with Potentials (NIIP) as an alternative approach to discover such interactions that enables greater flexibility in trajectory modeling: it discovers a set of relational potentials, represented as energy functions, which when minimized reconstruct the original trajectory. NIIP assigns low energy to the subset of trajectories which respect the relational constraints observed. We illustrate that with these representations NIIP displays unique capabilities in test-time. First, it allows trajectory manipulation, such as interchanging interaction types across separately trained models, as well as trajectory forecasting. Additionally, it allows adding external hand-crafted potentials at test-time. Finally, NIIP enables the detection of out-of-distribution samples and anomalies without explicit training. Website: https://energy-based-model.github.io/interaction-potentials.
Learning Transferable Object-Centric Diffeomorphic Transformations for Data Augmentation in Medical Image Segmentation
Jul 25, 2023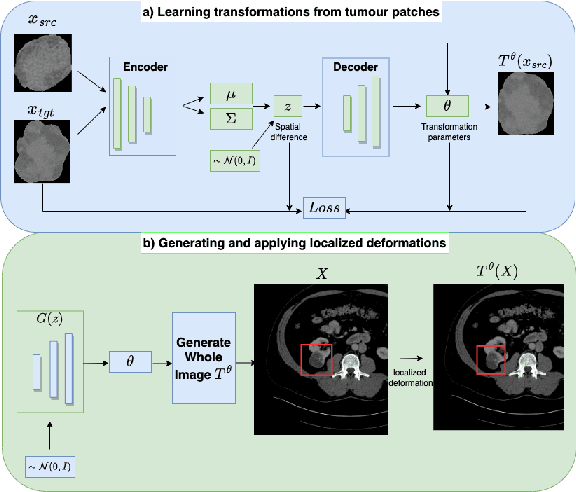
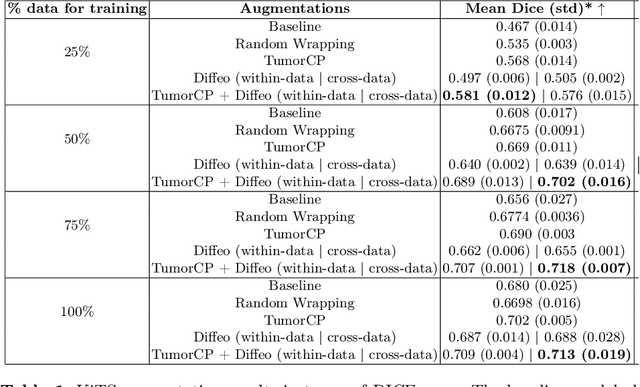

Obtaining labelled data in medical image segmentation is challenging due to the need for pixel-level annotations by experts. Recent works have shown that augmenting the object of interest with deformable transformations can help mitigate this challenge. However, these transformations have been learned globally for the image, limiting their transferability across datasets or applicability in problems where image alignment is difficult. While object-centric augmentations provide a great opportunity to overcome these issues, existing works are only focused on position and random transformations without considering shape variations of the objects. To this end, we propose a novel object-centric data augmentation model that is able to learn the shape variations for the objects of interest and augment the object in place without modifying the rest of the image. We demonstrated its effectiveness in improving kidney tumour segmentation when leveraging shape variations learned both from within the same dataset and transferred from external datasets.
Geometry of Score Based Generative Models
Feb 09, 2023In this work, we look at Score-based generative models (also called diffusion generative models) from a geometric perspective. From a new view point, we prove that both the forward and backward process of adding noise and generating from noise are Wasserstein gradient flow in the space of probability measures. We are the first to prove this connection. Our understanding of Score-based (and Diffusion) generative models have matured and become more complete by drawing ideas from different fields like Bayesian inference, control theory, stochastic differential equation and Schrodinger bridge. However, many open questions and challenges remain. One problem, for example, is how to decrease the sampling time? We demonstrate that looking from geometric perspective enables us to answer many of these questions and provide new interpretations to some known results. Furthermore, geometric perspective enables us to devise an intuitive geometric solution to the problem of faster sampling. By augmenting traditional score-based generative models with a projection step, we show that we can generate high quality images with significantly fewer sampling-steps.
Divide and Compose with Score Based Generative Models
Feb 05, 2023While score based generative models, or diffusion models, have found success in image synthesis, they are often coupled with text data or image label to be able to manipulate and conditionally generate images. Even though manipulation of images by changing the text prompt is possible, our understanding of the text embedding and our ability to modify it to edit images is quite limited. Towards the direction of having more control over image manipulation and conditional generation, we propose to learn image components in an unsupervised manner so that we can compose those components to generate and manipulate images in informed manner. Taking inspiration from energy based models, we interpret different score components as the gradient of different energy functions. We show how score based learning allows us to learn interesting components and we can visualize them through generation. We also show how this novel decomposition allows us to compose, generate and modify images in interesting ways akin to dreaming. We make our code available at https://github.com/sandeshgh/Score-based-disentanglement
Explanation Uncertainty with Decision Boundary Awareness
Oct 05, 2022
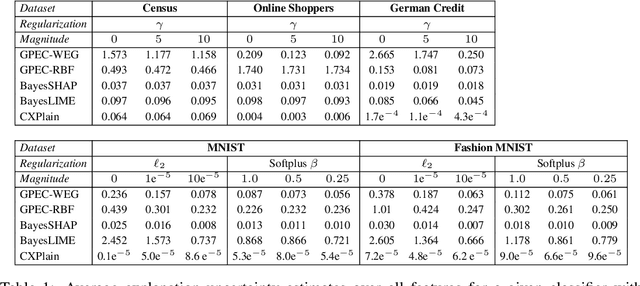
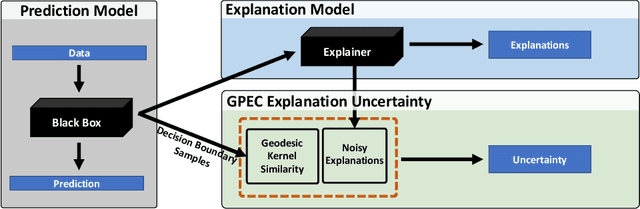
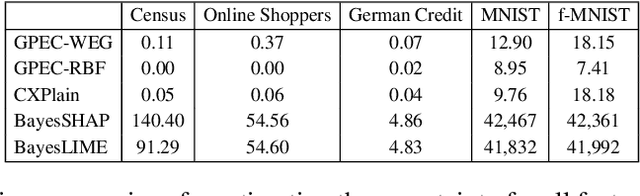
Post-hoc explanation methods have become increasingly depended upon for understanding black-box classifiers in high-stakes applications, precipitating a need for reliable explanations. While numerous explanation methods have been proposed, recent works have shown that many existing methods can be inconsistent or unstable. In addition, high-performing classifiers are often highly nonlinear and can exhibit complex behavior around the decision boundary, leading to brittle or misleading local explanations. Therefore, there is an impending need to quantify the uncertainty of such explanation methods in order to understand when explanations are trustworthy. We introduce a novel uncertainty quantification method parameterized by a Gaussian Process model, which combines the uncertainty approximation of existing methods with a novel geodesic-based similarity which captures the complexity of the target black-box decision boundary. The proposed framework is highly flexible; it can be used with any black-box classifier and feature attribution method to amortize uncertainty estimates for explanations. We show theoretically that our proposed geodesic-based kernel similarity increases with the complexity of the decision boundary. Empirical results on multiple tabular and image datasets show that our decision boundary-aware uncertainty estimate improves understanding of explanations as compared to existing methods.
Unsupervised Approaches for Out-Of-Distribution Dermoscopic Lesion Detection
Nov 08, 2021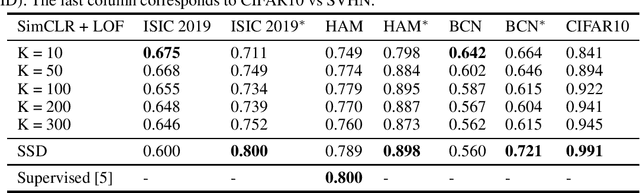

There are limited works showing the efficacy of unsupervised Out-of-Distribution (OOD) methods on complex medical data. Here, we present preliminary findings of our unsupervised OOD detection algorithm, SimCLR-LOF, as well as a recent state of the art approach (SSD), applied on medical images. SimCLR-LOF learns semantically meaningful features using SimCLR and uses LOF for scoring if a test sample is OOD. We evaluated on the multi-source International Skin Imaging Collaboration (ISIC) 2019 dataset, and show results that are competitive with SSD as well as with recent supervised approaches applied on the same data.
Self-Supervised Decomposition, Disentanglement and Prediction of Video Sequences while Interpreting Dynamics: A Koopman Perspective
Oct 01, 2021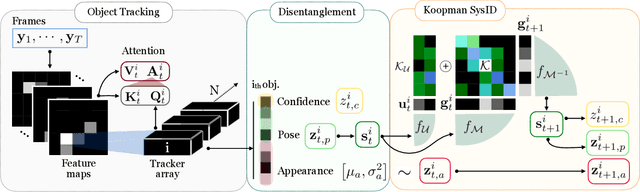
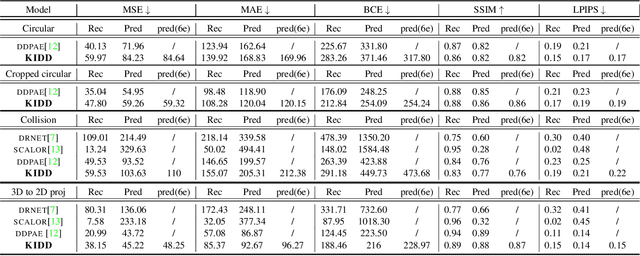
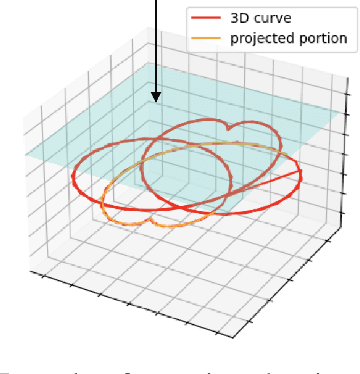

Human interpretation of the world encompasses the use of symbols to categorize sensory inputs and compose them in a hierarchical manner. One of the long-term objectives of Computer Vision and Artificial Intelligence is to endow machines with the capacity of structuring and interpreting the world as we do. Towards this goal, recent methods have successfully been able to decompose and disentangle video sequences into their composing objects and dynamics, in a self-supervised fashion. However, there has been a scarce effort in giving interpretation to the dynamics of the scene. We propose a method to decompose a video into moving objects and their attributes, and model each object's dynamics with linear system identification tools, by means of a Koopman embedding. This allows interpretation, manipulation and extrapolation of the dynamics of the different objects by employing the Koopman operator K. We test our method in various synthetic datasets and successfully forecast challenging trajectories while interpreting them.
Reliable Estimation of KL Divergence using a Discriminator in Reproducing Kernel Hilbert Space
Sep 29, 2021


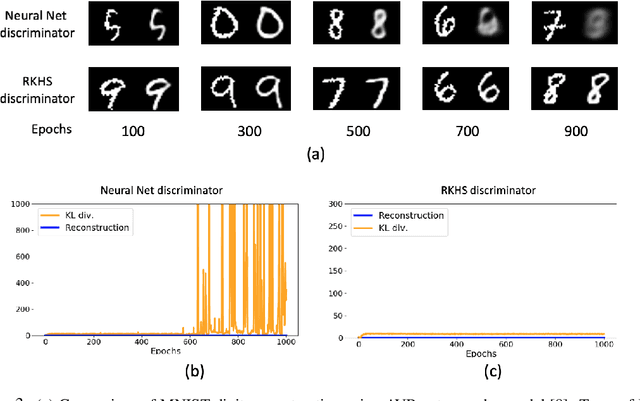
Estimating Kullback Leibler (KL) divergence from samples of two distributions is essential in many machine learning problems. Variational methods using neural network discriminator have been proposed to achieve this task in a scalable manner. However, we noted that most of these methods using neural network discriminators suffer from high fluctuations (variance) in estimates and instability in training. In this paper, we look at this issue from statistical learning theory and function space complexity perspective to understand why this happens and how to solve it. We argue that the cause of these pathologies is lack of control over the complexity of the neural network discriminator function and could be mitigated by controlling it. To achieve this objective, we 1) present a novel construction of the discriminator in the Reproducing Kernel Hilbert Space (RKHS), 2) theoretically relate the error probability bound of the KL estimates to the complexity of the discriminator in the RKHS space, 3) present a scalable way to control the complexity (RKHS norm) of the discriminator for a reliable estimation of KL divergence, and 4) prove the consistency of the proposed estimator. In three different applications of KL divergence : estimation of KL, estimation of mutual information and Variational Bayes, we show that by controlling the complexity as developed in the theory, we are able to reduce the variance of KL estimates and stabilize the training
* 27 pages, 3 figures. arXiv admin note: text overlap with arXiv:2002.11187
Enhancing Mixup-based Semi-Supervised Learning with Explicit Lipschitz Regularization
Sep 23, 2020
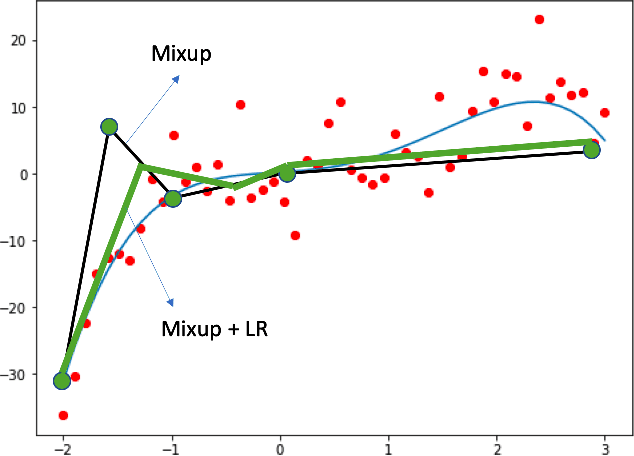
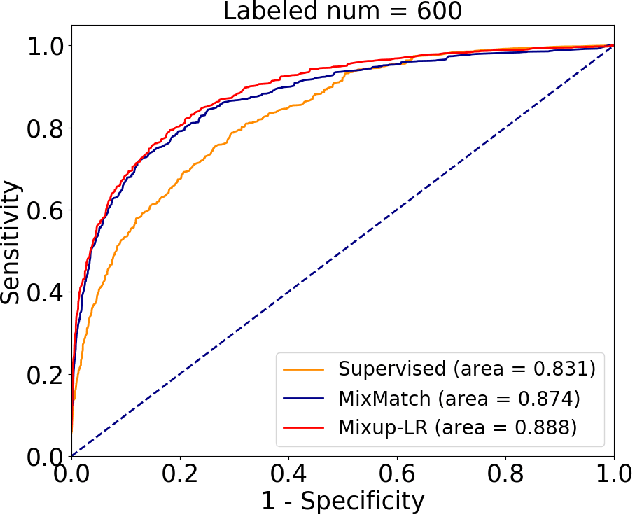
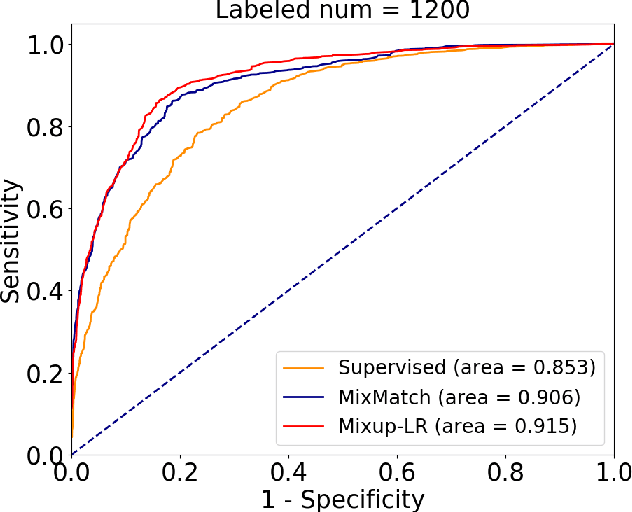
The success of deep learning relies on the availability of large-scale annotated data sets, the acquisition of which can be costly, requiring expert domain knowledge. Semi-supervised learning (SSL) mitigates this challenge by exploiting the behavior of the neural function on large unlabeled data. The smoothness of the neural function is a commonly used assumption exploited in SSL. A successful example is the adoption of mixup strategy in SSL that enforces the global smoothness of the neural function by encouraging it to behave linearly when interpolating between training examples. Despite its empirical success, however, the theoretical underpinning of how mixup regularizes the neural function has not been fully understood. In this paper, we offer a theoretically substantiated proposition that mixup improves the smoothness of the neural function by bounding the Lipschitz constant of the gradient function of the neural networks. We then propose that this can be strengthened by simultaneously constraining the Lipschitz constant of the neural function itself through adversarial Lipschitz regularization, encouraging the neural function to behave linearly while also constraining the slope of this linear function. On three benchmark data sets and one real-world biomedical data set, we demonstrate that this combined regularization results in improved generalization performance of SSL when learning from a small amount of labeled data. We further demonstrate the robustness of the presented method against single-step adversarial attacks. Our code is available at https://github.com/Prasanna1991/Mixup-LR.