 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Additive Decompositions: Interpretability Through Separability
Jun 01, 2026Interpretable machine learning requires models that are accurate and structurally faithful to the data. Existing explainability methods rely heavily on additive representations (e.g., Generalized Additive Models (GAMs), SHapley Additive exPlanations (SHAP), functional ANOVA), which can suffer from signal cancellation and off-support extrapolation in the presence of strong interactions. We propose Tensor Separation Learning (TSL), a regression model that learns a sum of rank-1 products of univariate per-feature functions via a stagewise greedy procedure with orthogonal refitting. By enforcing separability, TSL avoids the information loss inherent in additive projections caused by marginalizing higher-order interactions. The learned TSL model can be fully reconstructed from first-order partial dependence functions, up to constant factors. This stage-wise correspondence ensures that the resulting visualizations are faithful to the fitted components. We establish approximation-rate guarantees for functions with bounded mixed $p$-th order partial derivatives and demonstrate that TSL competes with black-box models on regression benchmarks.
KVServe: Service-Aware KV Cache Compression for Communication-Efficient Disaggregated LLM Serving
May 13, 2026LLMs are widely adopted in production, pushing inference systems to their limits. Disaggregated LLM serving (e.g., PD separation and KV state disaggregation) improves scalability and cost efficiency, but it also turns KV into an explicit payload crossing network and storage boundaries, making KV a dominant end-to-end bottleneck. Existing KV compression are typically static runtime configurations, despite production service context varies over time in workload mix, bandwidth, and SLO/quality budgets. As a result, a fixed choice can be suboptimal or even increase latency. We present \emph{KVServe}, the first service-aware and adaptive KV communication compression framework for disaggregated LLM serving: KVServe (1) unifies KV compression into a modular strategy space with new components and cross-method recomposition; (2) introduces Bayesian Profiling Engine that efficiently searches this space and distills a 3D Pareto candidate set, reducing $50\times$ offline search overhead; and (3) deploys a Service-Aware Online Controller that combines an analytical latency model with a lightweight bandit to select profiles under constraints and correct offline-to-online mismatch. Integrated into vLLM and evaluated across datasets, models, GPUs and networks, KVServe achieves up to $9.13\times$ JCT speedup in PD-separated serving and up to $32.8\times$ TTFT reduction in KV-disaggregated serving.
KRONE: Hierarchical and Modular Log Anomaly Detection
Feb 07, 2026Log anomaly detection is crucial for uncovering system failures and security risks. Although logs originate from nested component executions with clear boundaries, this structure is lost when they are stored as flat sequences. As a result, state-of-the-art methods risk missing true dependencies within executions while learning spurious ones across unrelated events. We propose KRONE, the first hierarchical anomaly detection framework that automatically derives execution hierarchies from flat logs for modular multi-level anomaly detection. At its core, the KRONE Log Abstraction Model captures application-specific semantic hierarchies from log data. This hierarchy is then leveraged to recursively decompose log sequences into multiple levels of coherent execution chunks, referred to as KRONE Seqs, transforming sequence-level anomaly detection into a set of modular KRONE Seq-level detection tasks. For each test KRONE Seq, KRONE employs a hybrid modular detection mechanism that dynamically routes between an efficient level-independent Local-Context detector, which rapidly filters normal sequences, and a Nested-Aware detector that incorporates cross-level semantic dependencies and supports LLM-based anomaly detection and explanation. KRONE further optimizes hierarchical detection through cached result reuse and early-exit strategies. Experiments on three public benchmarks and one industrial dataset from ByteDance Cloud demonstrate that KRONE achieves consistent improvements in detection accuracy, F1-score, data efficiency, resource efficiency, and interpretability. KRONE improves the F1-score by more than 10 percentage points over prior methods while reducing LLM usage to only a small fraction of the test data.
Fast Estimation of Partial Dependence Functions using Trees
Oct 17, 2024
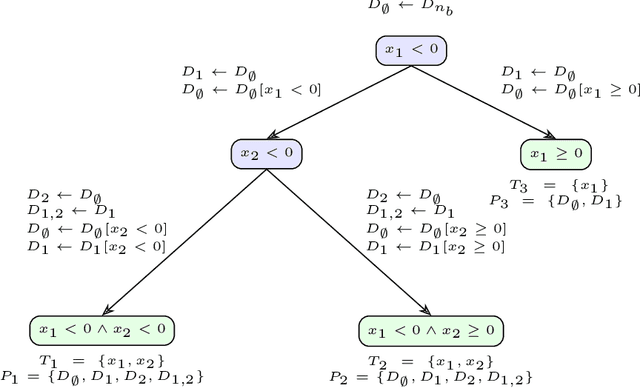
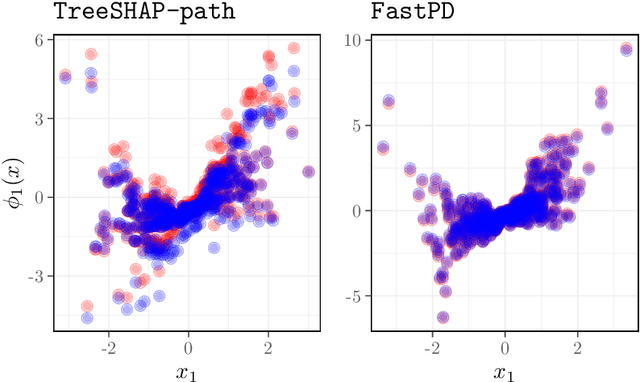
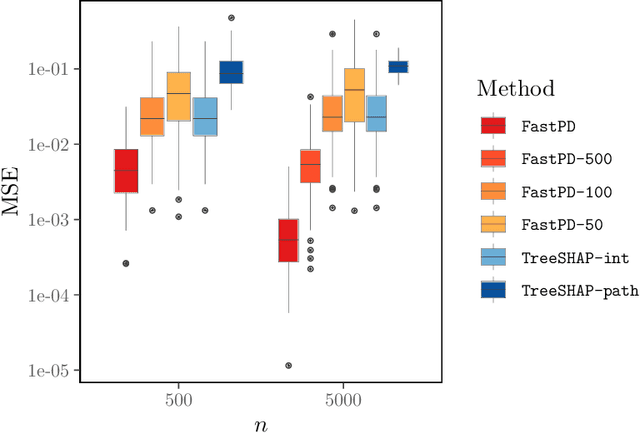
Many existing interpretation methods are based on Partial Dependence (PD) functions that, for a pre-trained machine learning model, capture how a subset of the features affects the predictions by averaging over the remaining features. Notable methods include Shapley additive explanations (SHAP) which computes feature contributions based on a game theoretical interpretation and PD plots (i.e., 1-dim PD functions) that capture average marginal main effects. Recent work has connected these approaches using a functional decomposition and argues that SHAP values can be misleading since they merge main and interaction effects into a single local effect. A major advantage of SHAP compared to other PD-based interpretations, however, has been the availability of fast estimation techniques, such as \texttt{TreeSHAP}. In this paper, we propose a new tree-based estimator, \texttt{FastPD}, which efficiently estimates arbitrary PD functions. We show that \texttt{FastPD} consistently estimates the desired population quantity -- in contrast to path-dependent \texttt{TreeSHAP} which is inconsistent when features are correlated. For moderately deep trees, \texttt{FastPD} improves the complexity of existing methods from quadratic to linear in the number of observations. By estimating PD functions for arbitrary feature subsets, \texttt{FastPD} can be used to extract PD-based interpretations such as SHAP, PD plots and higher order interaction effects.
FT K-Means: A High-Performance K-Means on GPU with Fault Tolerance
Aug 02, 2024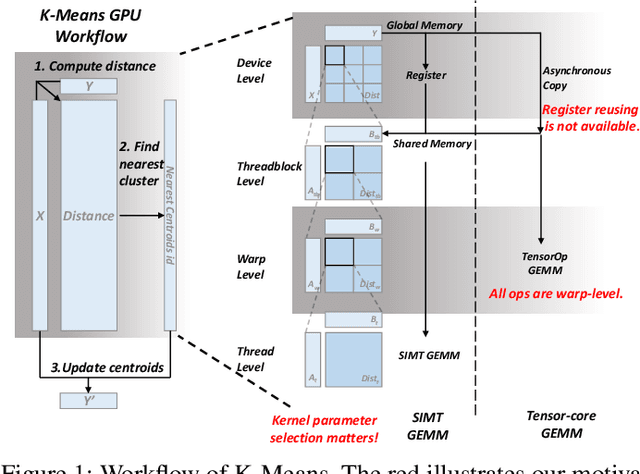
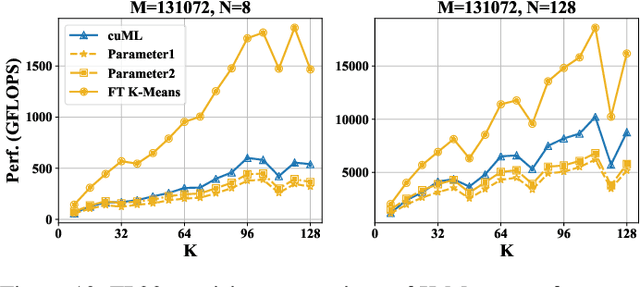
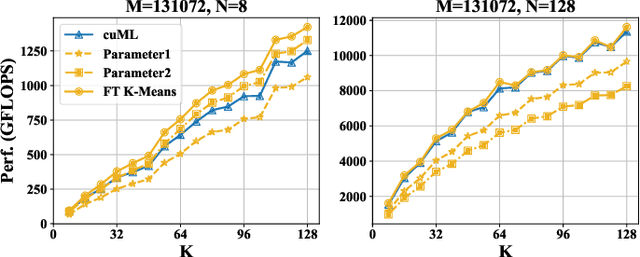
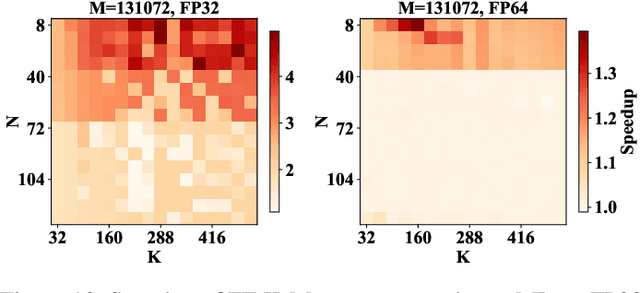
K-Means is a widely used algorithm in clustering, however, its efficiency is primarily constrained by the computational cost of distance computing. Existing implementations suffer from suboptimal utilization of computational units and lack resilience against soft errors. To address these challenges, we introduce FT K-Means, a high-performance GPU-accelerated implementation of K-Means with online fault tolerance. We first present a stepwise optimization strategy that achieves competitive performance compared to NVIDIA's cuML library. We further improve FT K-Means with a template-based code generation framework that supports different data types and adapts to different input shapes. A novel warp-level tensor-core error correction scheme is proposed to address the failure of existing fault tolerance methods due to memory asynchronization during copy operations. Our experimental evaluations on NVIDIA T4 GPU and A100 GPU demonstrate that FT K-Means without fault tolerance outperforms cuML's K-Means implementation, showing a performance increase of 10\%-300\% in scenarios involving irregular data shapes. Moreover, the fault tolerance feature of FT K-Means introduces only an overhead of 11\%, maintaining robust performance even with tens of errors injected per second.
3D-HGS: 3D Half-Gaussian Splatting
Jun 04, 2024Photo-realistic 3D Reconstruction is a fundamental problem in 3D computer vision. This domain has seen considerable advancements owing to the advent of recent neural rendering techniques. These techniques predominantly aim to focus on learning volumetric representations of 3D scenes and refining these representations via loss functions derived from rendering. Among these, 3D Gaussian Splatting (3D-GS) has emerged as a significant method, surpassing Neural Radiance Fields (NeRFs). 3D-GS uses parameterized 3D Gaussians for modeling both spatial locations and color information, combined with a tile-based fast rendering technique. Despite its superior rendering performance and speed, the use of 3D Gaussian kernels has inherent limitations in accurately representing discontinuous functions, notably at edges and corners for shape discontinuities, and across varying textures for color discontinuities. To address this problem, we propose to employ 3D Half-Gaussian (3D-HGS) kernels, which can be used as a plug-and-play kernel. Our experiments demonstrate their capability to improve the performance of current 3D-GS related methods and achieve state-of-the-art rendering performance on various datasets without compromising rendering speed.
Solving Masked Jigsaw Puzzles with Diffusion Vision Transformers
Apr 10, 2024



Solving image and video jigsaw puzzles poses the challenging task of rearranging image fragments or video frames from unordered sequences to restore meaningful images and video sequences. Existing approaches often hinge on discriminative models tasked with predicting either the absolute positions of puzzle elements or the permutation actions applied to the original data. Unfortunately, these methods face limitations in effectively solving puzzles with a large number of elements. In this paper, we propose JPDVT, an innovative approach that harnesses diffusion transformers to address this challenge. Specifically, we generate positional information for image patches or video frames, conditioned on their underlying visual content. This information is then employed to accurately assemble the puzzle pieces in their correct positions, even in scenarios involving missing pieces. Our method achieves state-of-the-art performance on several datasets.
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Mar 21, 2024



Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
Knowledge-aware Alert Aggregation in Large-scale Cloud Systems: a Hybrid Approach
Mar 11, 2024Due to the scale and complexity of cloud systems, a system failure would trigger an "alert storm", i.e., massive correlated alerts. Although these alerts can be traced back to a few root causes, the overwhelming number makes it infeasible for manual handling. Alert aggregation is thus critical to help engineers concentrate on the root cause and facilitate failure resolution. Existing methods typically utilize semantic similarity-based methods or statistical methods to aggregate alerts. However, semantic similarity-based methods overlook the causal rationale of alerts, while statistical methods can hardly handle infrequent alerts. To tackle these limitations, we introduce leveraging external knowledge, i.e., Standard Operation Procedure (SOP) of alerts as a supplement. We propose COLA, a novel hybrid approach based on correlation mining and LLM (Large Language Model) reasoning for online alert aggregation. The correlation mining module effectively captures the temporal and spatial relations between alerts, measuring their correlations in an efficient manner. Subsequently, only uncertain pairs with low confidence are forwarded to the LLM reasoning module for detailed analysis. This hybrid design harnesses both statistical evidence for frequent alerts and the reasoning capabilities of computationally intensive LLMs, ensuring the overall efficiency of COLA in handling large volumes of alerts in practical scenarios. We evaluate COLA on three datasets collected from the production environment of a large-scale cloud platform. The experimental results show COLA achieves F1-scores from 0.901 to 0.930, outperforming state-of-the-art methods and achieving comparable efficiency. We also share our experience in deploying COLA in our real-world cloud system, Cloud X.
FaultProfIT: Hierarchical Fault Profiling of Incident Tickets in Large-scale Cloud Systems
Feb 27, 2024Postmortem analysis is essential in the management of incidents within cloud systems, which provides valuable insights to improve system's reliability and robustness. At CloudA, fault pattern profiling is performed during the postmortem phase, which involves the classification of incidents' faults into unique categories, referred to as fault pattern. By aggregating and analyzing these fault patterns, engineers can discern common faults, vulnerable components and emerging fault trends. However, this process is currently conducted by manual labeling, which has inherent drawbacks. On the one hand, the sheer volume of incidents means only the most severe ones are analyzed, causing a skewed overview of fault patterns. On the other hand, the complexity of the task demands extensive domain knowledge, which leads to errors and inconsistencies. To address these limitations, we propose an automated approach, named FaultProfIT, for Fault pattern Profiling of Incident Tickets. It leverages hierarchy-guided contrastive learning to train a hierarchy-aware incident encoder and predicts fault patterns with enhanced incident representations. We evaluate FaultProfIT using the production incidents from CloudA. The results demonstrate that FaultProfIT outperforms state-of-the-art methods. Our ablation study and analysis also verify the effectiveness of hierarchy-guided contrastive learning. Additionally, we have deployed FaultProfIT at CloudA for six months. To date, FaultProfIT has analyzed 10,000+ incidents from 30+ cloud services, successfully revealing several fault trends that have informed system improvements.