 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFT-Transformer: Resilient and Reliable Transformer with End-to-End Fault Tolerant Attention
Apr 03, 2025Transformer models leverage self-attention mechanisms to capture complex dependencies, demonstrating exceptional performance in various applications. However, the long-duration high-load computations required for model inference impose stringent reliability demands on the computing platform, as soft errors that occur during execution can significantly degrade model performance. Existing fault tolerance methods protect each operation separately using decoupled kernels, incurring substantial computational and memory overhead. In this paper, we propose a novel error-resilient framework for Transformer models, integrating end-to-end fault tolerant attention (EFTA) to improve inference reliability against soft errors. Our approach enables error detection and correction within a fully fused attention kernel, reducing redundant data access and thereby mitigating memory faults. To further enhance error coverage and reduce overhead, we design a hybrid fault tolerance scheme tailored for the EFTA, introducing for the first time: 1) architecture-aware algorithm-based fault tolerance (ABFT) using tensor checksum, which minimizes inter-thread communication overhead on tensor cores during error detection; 2) selective neuron value restriction, which selectively applies adaptive fault tolerance constraints to neuron values, balancing error coverage and overhead; 3) unified verification, reusing checksums to streamline multiple computation steps into a single verification process. Experimental results show that EFTA achieves up to 7.56x speedup over traditional methods with an average fault tolerance overhead of 13.9%.
FT K-Means: A High-Performance K-Means on GPU with Fault Tolerance
Aug 02, 2024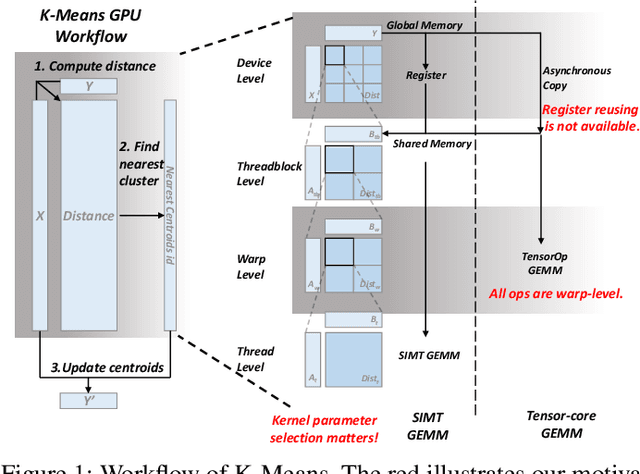
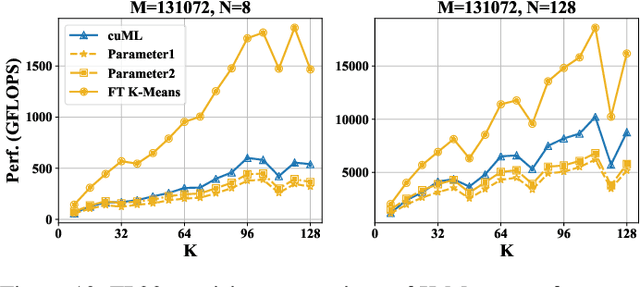
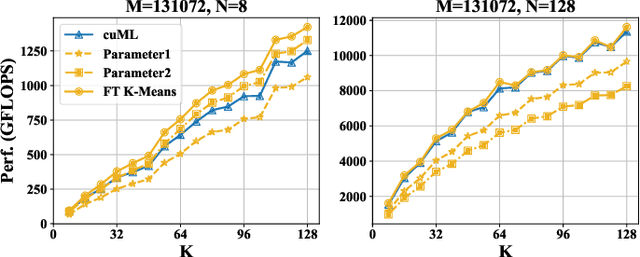
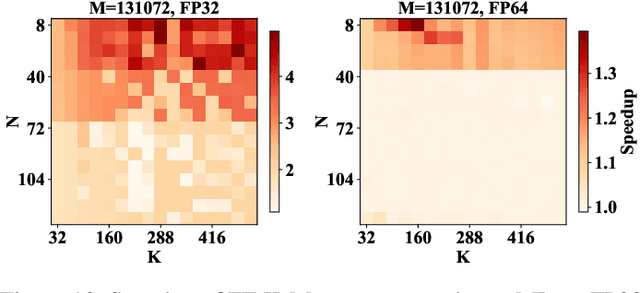
K-Means is a widely used algorithm in clustering, however, its efficiency is primarily constrained by the computational cost of distance computing. Existing implementations suffer from suboptimal utilization of computational units and lack resilience against soft errors. To address these challenges, we introduce FT K-Means, a high-performance GPU-accelerated implementation of K-Means with online fault tolerance. We first present a stepwise optimization strategy that achieves competitive performance compared to NVIDIA's cuML library. We further improve FT K-Means with a template-based code generation framework that supports different data types and adapts to different input shapes. A novel warp-level tensor-core error correction scheme is proposed to address the failure of existing fault tolerance methods due to memory asynchronization during copy operations. Our experimental evaluations on NVIDIA T4 GPU and A100 GPU demonstrate that FT K-Means without fault tolerance outperforms cuML's K-Means implementation, showing a performance increase of 10\%-300\% in scenarios involving irregular data shapes. Moreover, the fault tolerance feature of FT K-Means introduces only an overhead of 11\%, maintaining robust performance even with tens of errors injected per second.
SRN-SZ: Deep Leaning-Based Scientific Error-bounded Lossy Compression with Super-resolution Neural Networks
Sep 07, 2023



The fast growth of computational power and scales of modern super-computing systems have raised great challenges for the management of exascale scientific data. To maintain the usability of scientific data, error-bound lossy compression is proposed and developed as an essential technique for the size reduction of scientific data with constrained data distortion. Among the diverse datasets generated by various scientific simulations, certain datasets cannot be effectively compressed by existing error-bounded lossy compressors with traditional techniques. The recent success of Artificial Intelligence has inspired several researchers to integrate neural networks into error-bounded lossy compressors. However, those works still suffer from limited compression ratios and/or extremely low efficiencies. To address those issues and improve the compression on the hard-to-compress datasets, in this paper, we propose SRN-SZ, which is a deep learning-based scientific error-bounded lossy compressor leveraging the hierarchical data grid expansion paradigm implemented by super-resolution neural networks. SRN-SZ applies the most advanced super-resolution network HAT for its compression, which is free of time-costing per-data training. In experiments compared with various state-of-the-art compressors, SRN-SZ achieves up to 75% compression ratio improvements under the same error bound and up to 80% compression ratio improvements under the same PSNR than the second-best compressor.
ByteTransformer: A High-Performance Transformer Boosted for Variable-Length Inputs
Oct 06, 2022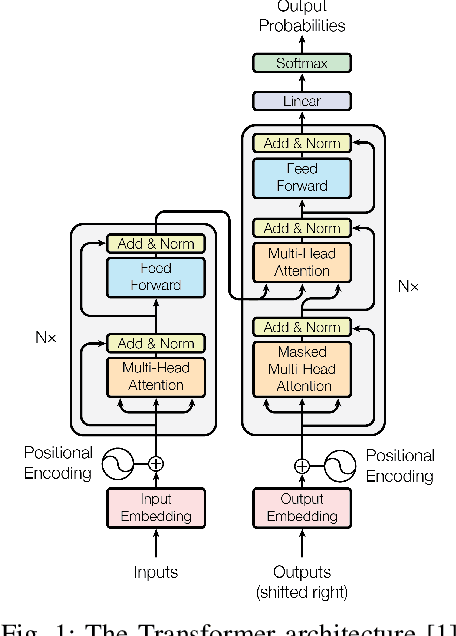
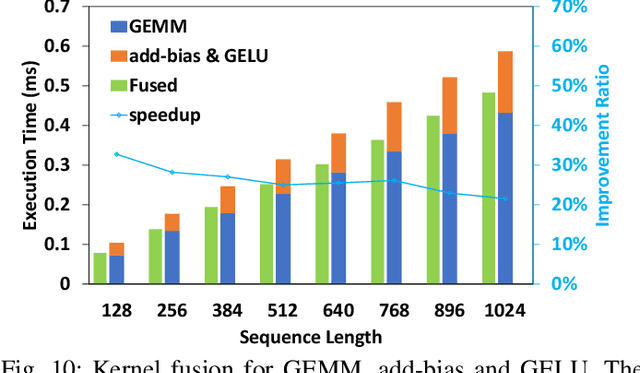
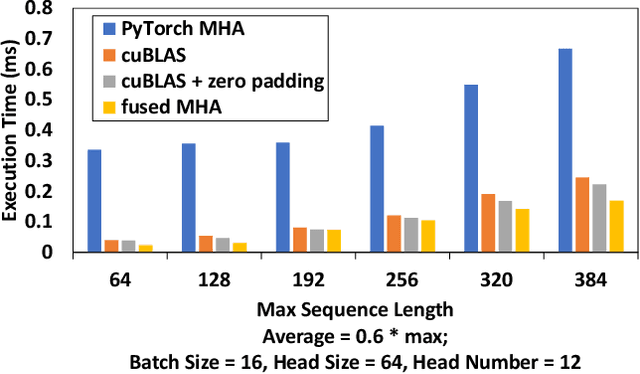
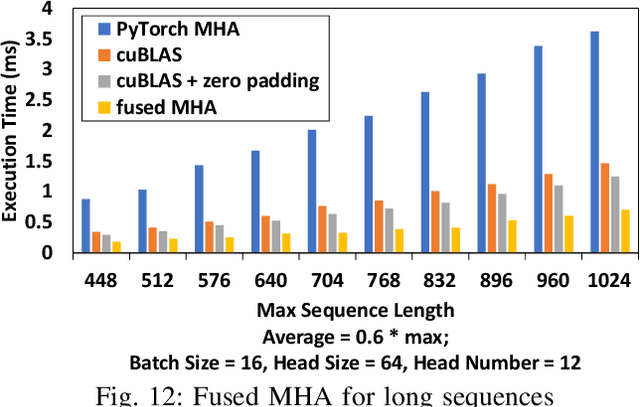
Transformer is the cornerstone model of Natural Language Processing (NLP) over the past decade. Despite its great success in Deep Learning (DL) applications, the increasingly growing parameter space required by transformer models boosts the demand on accelerating the performance of transformer models. In addition, NLP problems can commonly be faced with variable-length sequences since their word numbers can vary among sentences. Existing DL frameworks need to pad variable-length sequences to the maximal length, which, however, leads to significant memory and computational overhead. In this paper, we present ByteTransformer, a high-performance transformer boosted for variable-length inputs. We propose a zero padding algorithm that enables the whole transformer to be free from redundant computations on useless padded tokens. Besides the algorithmic level optimization, we provide architectural-aware optimizations for transformer functioning modules, especially the performance-critical algorithm, multi-head attention (MHA). Experimental results on an NVIDIA A100 GPU with variable-length sequence inputs validate that our fused MHA (FMHA) outperforms the standard PyTorch MHA by 6.13X. The end-to-end performance of ByteTransformer for a standard BERT transformer model surpasses the state-of-the-art Transformer frameworks, such as PyTorch JIT, TensorFlow XLA, Tencent TurboTransformer and NVIDIA FasterTransformer, by 87\%, 131\%, 138\% and 46\%, respectively.
Multi-granularity Association Learning Framework for on-the-fly Fine-Grained Sketch-based Image Retrieval
Jan 13, 2022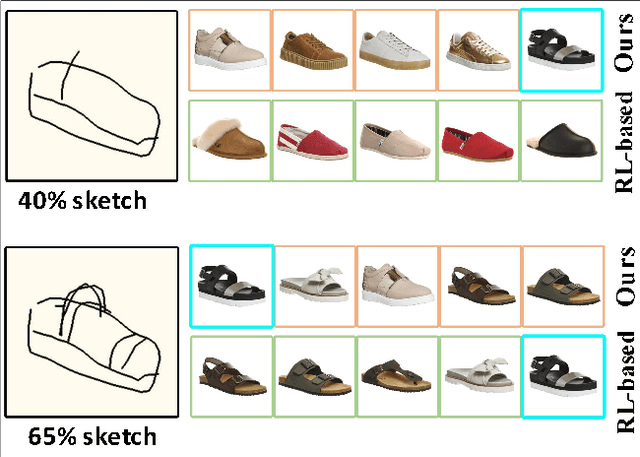
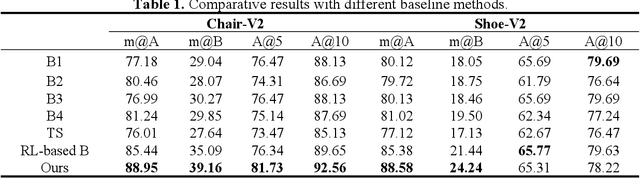
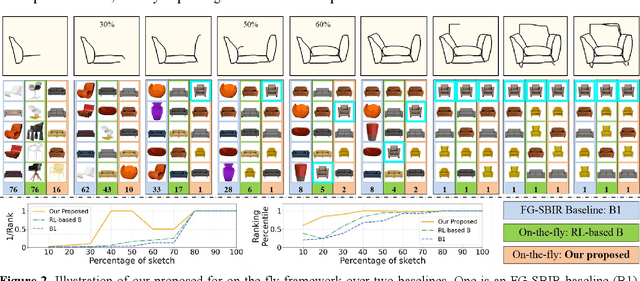
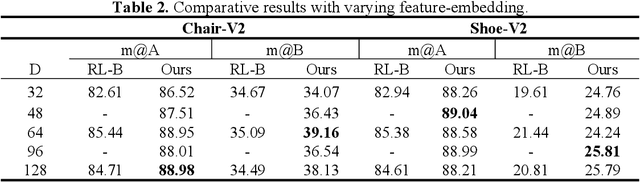
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo in a given query sketch. However, its widespread applicability is limited by the fact that it is difficult to draw a complete sketch for most people, and the drawing process often takes time. In this study, we aim to retrieve the target photo with the least number of strokes possible (incomplete sketch), named on-the-fly FG-SBIR (Bhunia et al. 2020), which starts retrieving at each stroke as soon as the drawing begins. We consider that there is a significant correlation among these incomplete sketches in the sketch drawing episode of each photo. To learn more efficient joint embedding space shared between the photo and its incomplete sketches, we propose a multi-granularity association learning framework that further optimizes the embedding space of all incomplete sketches. Specifically, based on the integrity of the sketch, we can divide a complete sketch episode into several stages, each of which corresponds to a simple linear mapping layer. Moreover, our framework guides the vector space representation of the current sketch to approximate that of its later sketches to realize the retrieval performance of the sketch with fewer strokes to approach that of the sketch with more strokes. In the experiments, we proposed more realistic challenges, and our method achieved superior early retrieval efficiency over the state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
An Efficient and Accurate Rough Set for Feature Selection, Classification and Knowledge Representation
Jan 12, 2022
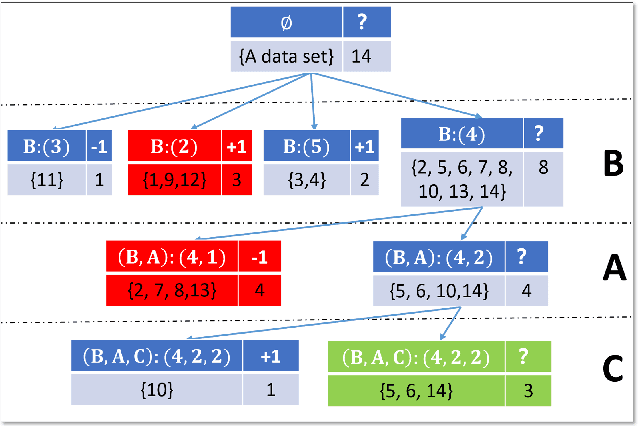
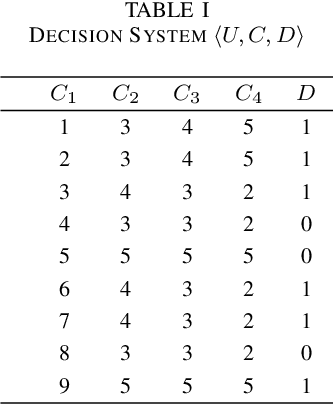
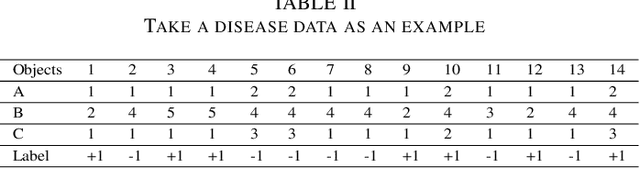
This paper present a strong data mining method based on rough set, which can realize feature selection, classification and knowledge representation at the same time. Rough set has good interpretability, and is a popular method for feature selections. But low efficiency and low accuracy are its main drawbacks that limits its application ability. In this paper,corresponding to the accuracy, we first find the ineffectiveness of rough set because of overfitting, especially in processing noise attribute, and propose a robust measurement for an attribute, called relative importance.we proposed the concept of "rough concept tree" for knowledge representation and classification. Experimental results on public benchmark data sets show that the proposed framework achieves higher accurcy than seven popular or the state-of-the-art feature selection methods.
Exploring Autoencoder-Based Error-Bounded Compression for Scientific Data
May 25, 2021
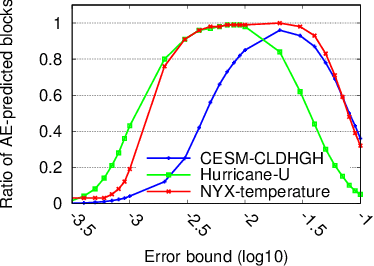
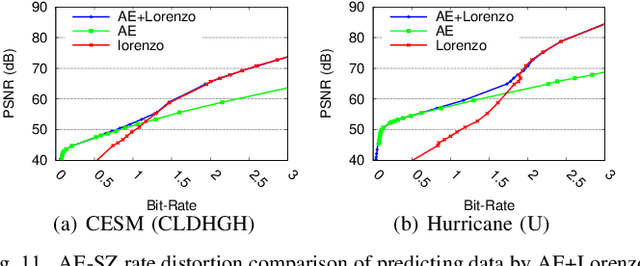

Error-bounded lossy compression is becoming an indispensable technique for the success of today's scientific projects with vast volumes of data produced during the simulations or instrument data acquisitions. Not only can it significantly reduce data size, but it also can control the compression errors based on user-specified error bounds. Autoencoder (AE) models have been widely used in image compression, but few AE-based compression approaches support error-bounding features, which are highly required by scientific applications. To address this issue, we explore using convolutional autoencoders to improve error-bounded lossy compression for scientific data, with the following three key contributions. (1) We provide an in-depth investigation of the characteristics of various autoencoder models and develop an error-bounded autoencoder-based framework in terms of the SZ model. (2) We optimize the compression quality for main stages in our designed AE-based error-bounded compression framework, fine-tuning the block sizes and latent sizes and also optimizing the compression efficiency of latent vectors. (3) We evaluate our proposed solution using five real-world scientific datasets and comparing them with six other related works. Experiments show that our solution exhibits a very competitive compression quality from among all the compressors in our tests. In absolute terms, it can obtain a much better compression quality (100% ~ 800% improvement in compression ratio with the same data distortion) compared with SZ2.1 and ZFP in cases with a high compression ratio.
Ball k-means
May 02, 2020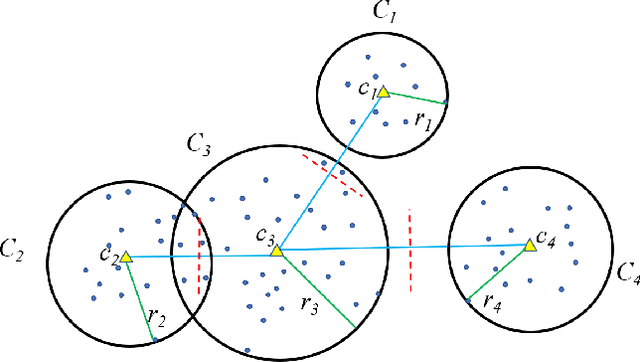
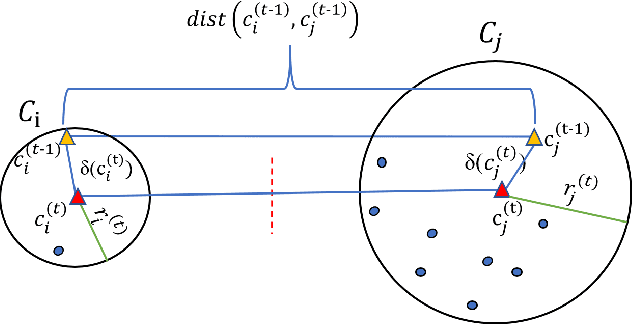
This paper presents a novel accelerated exact k-means algorithm called the Ball k-means algorithm, which uses a ball to describe a cluster, focusing on reducing the point-centroid distance computation. The Ball k-means can accurately find the neighbor clusters for each cluster resulting distance computations only between a point and its neighbor clusters' centroids instead of all centroids. Moreover, each cluster can be divided into a stable area and an active area, and the later one can be further divided into annulus areas. The assigned cluster of the points in the stable area is not changed in the current iteration while the points in the annulus area will be adjusted within a few neighbor clusters in the current iteration. Also, there are no upper or lower bounds in the proposed Ball k-means. Furthermore, reducing centroid-centroid distance computation between iterations makes it efficient for large k clustering. The fast speed, no extra parameters and simple design of the Ball k-means make it an all-around replacement of the naive k-means algorithm.
Algorithm-Based Fault Tolerance for Convolutional Neural Networks
Mar 27, 2020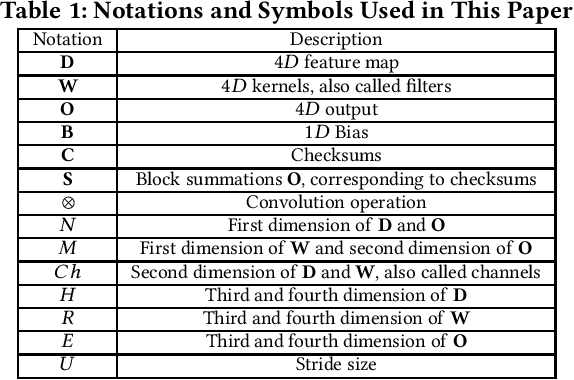
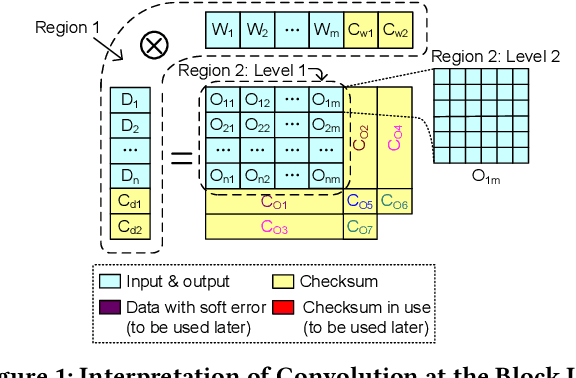
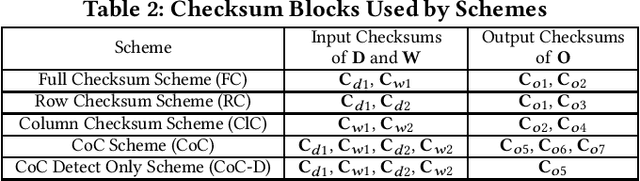
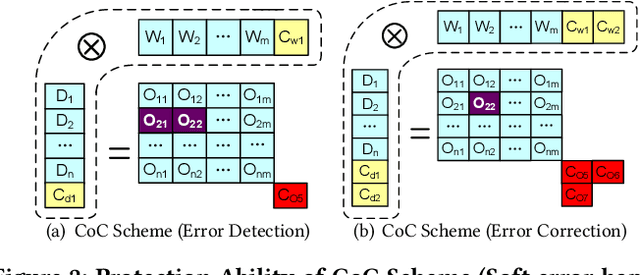
Convolutional neural networks (CNNs) are becoming more and more important for solving challenging and critical problems in many fields. CNN inference applications have been deployed in safety-critical systems, which may suffer from soft errors caused by high-energy particles, high temperature, or abnormal voltage. Of critical importance is ensuring the stability of the CNN inference process against soft errors. Traditional fault tolerance methods are not suitable for CNN inference because error-correcting code is unable to protect computational components, instruction duplication techniques incur high overhead, and existing algorithm-based fault tolerance (ABFT) schemes cannot protect all convolution implementations. In this paper, we focus on how to protect the CNN inference process against soft errors as efficiently as possible, with the following three contributions. (1) We propose several systematic ABFT schemes based on checksum techniques and analyze their pros and cons thoroughly. Unlike traditional ABFT based on matrix-matrix multiplication, our schemes support any convolution implementations. (2) We design a novel workflow integrating all the proposed schemes to obtain a high detection/correction ability with limited total runtime overhead. (3) We perform our evaluation using ImageNet with well-known CNN models including AlexNet, VGG-19, ResNet-18, and YOLOv2. Experimental results demonstrate that our implementation can handle soft errors with very limited runtime overhead (4%~8% in both error-free and error-injected situations).
Normalization of Input-output Shared Embeddings in Text Generation Models
Jan 24, 2020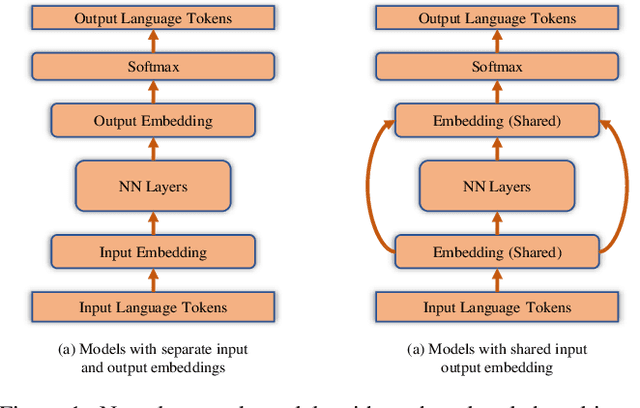


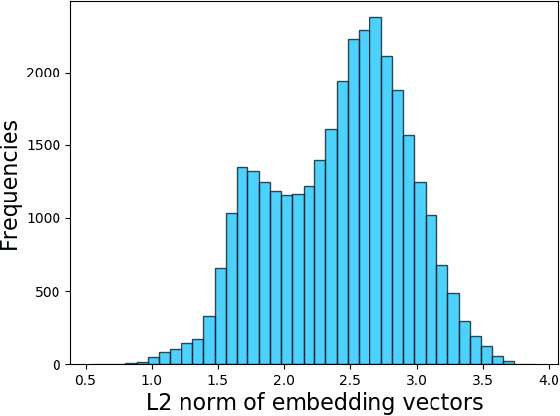
Neural Network based models have been state-of-the-art models for various Natural Language Processing tasks, however, the input and output dimension problem in the networks has still not been fully resolved, especially in text generation tasks (e.g. Machine Translation, Text Summarization), in which input and output both have huge sizes of vocabularies. Therefore, input-output embedding weight sharing has been introduced and adopted widely, which remains to be improved. Based on linear algebra and statistical theories, this paper locates the shortcoming of existed input-output embedding weight sharing method, then raises methods for improving input-output weight shared embedding, among which methods of normalization of embedding weight matrices show best performance. These methods are nearly computational cost-free, can get combined with other embedding techniques, and show good effectiveness when applied on state-of-the-art Neural Network models. For Transformer-big models, the normalization techniques can get at best 0.6 BLEU improvement compared to the original version of model on WMT'16 En-De dataset, and similar BLEU improvements on IWSLT 14' datasets. For DynamicConv models, 0.5 BLEU improvement can be attained on WMT'16 En-De dataset, and 0.41 BLEU improvement on IWSLT 14' De-En translation task is achieved.