 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP model is an Efficient Online Lifelong Learner
May 24, 2024Online Lifelong Learning (OLL) addresses the challenge of learning from continuous and non-stationary data streams. Existing online lifelong learning methods based on image classification models often require preset conditions such as the total number of classes or maximum memory capacity, which hinders the realization of real never-ending learning and renders them impractical for real-world scenarios. In this work, we propose that vision-language models, such as Contrastive Language-Image Pretraining (CLIP), are more suitable candidates for online lifelong learning. We discover that maintaining symmetry between image and text is crucial during Parameter-Efficient Tuning (PET) for CLIP model in online lifelong learning. To this end, we introduce the Symmetric Image-Text (SIT) tuning strategy. We conduct extensive experiments on multiple lifelong learning benchmark datasets and elucidate the effectiveness of SIT through gradient analysis. Additionally, we assess the impact of lifelong learning on generalizability of CLIP and found that tuning the image encoder is beneficial for lifelong learning, while tuning the text encoder aids in zero-shot learning.
Rethinking Class-Incremental Learning from a Dynamic Imbalanced Learning Perspective
May 24, 2024



Deep neural networks suffer from catastrophic forgetting when continually learning new concepts. In this paper, we analyze this problem from a data imbalance point of view. We argue that the imbalance between old task and new task data contributes to forgetting of the old tasks. Moreover, the increasing imbalance ratio during incremental learning further aggravates the problem. To address the dynamic imbalance issue, we propose Uniform Prototype Contrastive Learning (UPCL), where uniform and compact features are learned. Specifically, we generate a set of non-learnable uniform prototypes before each task starts. Then we assign these uniform prototypes to each class and guide the feature learning through prototype contrastive learning. We also dynamically adjust the relative margin between old and new classes so that the feature distribution will be maintained balanced and compact. Finally, we demonstrate through extensive experiments that the proposed method achieves state-of-the-art performance on several benchmark datasets including CIFAR100, ImageNet100 and TinyImageNet.
ByteTransformer: A High-Performance Transformer Boosted for Variable-Length Inputs
Oct 06, 2022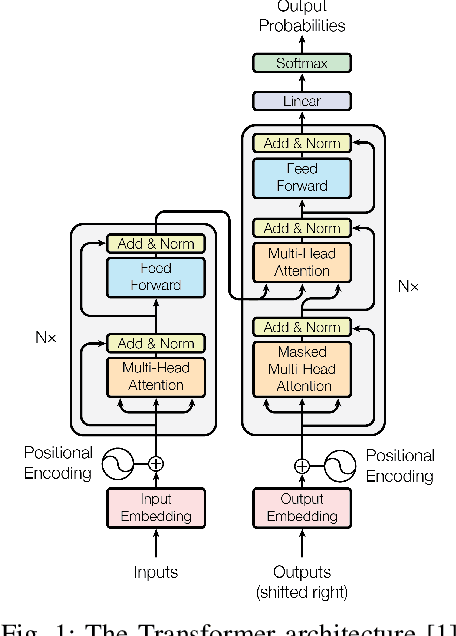
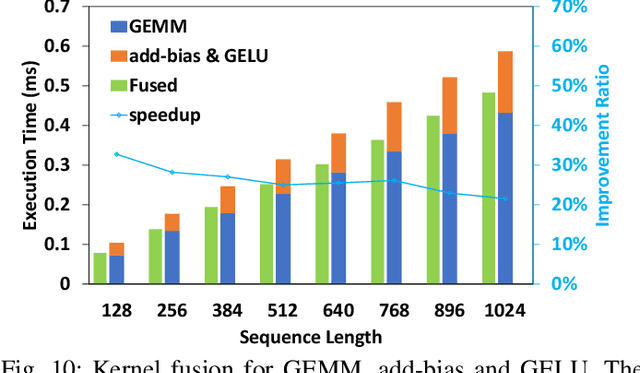
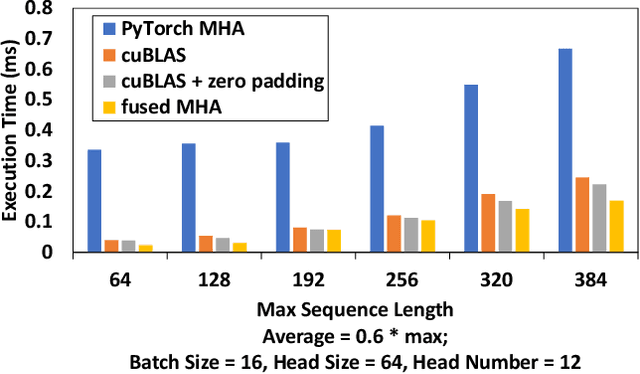
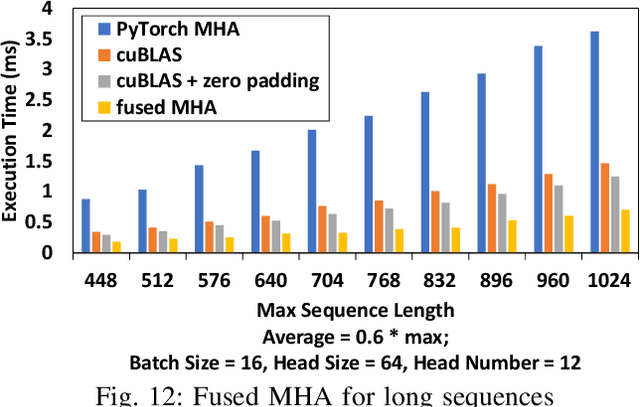
Transformer is the cornerstone model of Natural Language Processing (NLP) over the past decade. Despite its great success in Deep Learning (DL) applications, the increasingly growing parameter space required by transformer models boosts the demand on accelerating the performance of transformer models. In addition, NLP problems can commonly be faced with variable-length sequences since their word numbers can vary among sentences. Existing DL frameworks need to pad variable-length sequences to the maximal length, which, however, leads to significant memory and computational overhead. In this paper, we present ByteTransformer, a high-performance transformer boosted for variable-length inputs. We propose a zero padding algorithm that enables the whole transformer to be free from redundant computations on useless padded tokens. Besides the algorithmic level optimization, we provide architectural-aware optimizations for transformer functioning modules, especially the performance-critical algorithm, multi-head attention (MHA). Experimental results on an NVIDIA A100 GPU with variable-length sequence inputs validate that our fused MHA (FMHA) outperforms the standard PyTorch MHA by 6.13X. The end-to-end performance of ByteTransformer for a standard BERT transformer model surpasses the state-of-the-art Transformer frameworks, such as PyTorch JIT, TensorFlow XLA, Tencent TurboTransformer and NVIDIA FasterTransformer, by 87\%, 131\%, 138\% and 46\%, respectively.
Bolt: Bridging the Gap between Auto-tuners and Hardware-native Performance
Oct 25, 2021
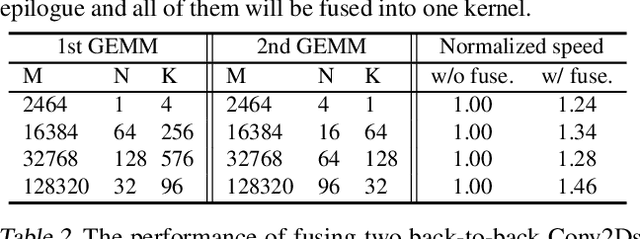
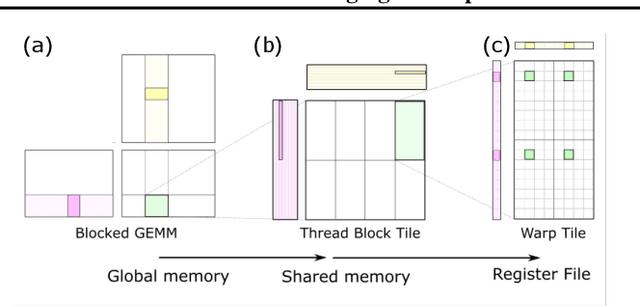

Today's auto-tuners (e.g., AutoTVM, Ansor) generate efficient tensor programs by navigating a large search space to identify effective implementations, but they do so with opaque hardware details. Thus, their performance could fall behind that of hardware-native libraries (e.g., cuBLAS, cuDNN), which are hand-optimized by device vendors to extract high performance. On the other hand, these vendor libraries have a fixed set of supported functions and lack the customization and automation support afforded by auto-tuners. Bolt is based on the recent trend that vendor libraries are increasingly modularized and reconfigurable via declarative control (e.g., CUTLASS). It enables a novel approach that bridges this gap and achieves the best of both worlds, via hardware-native templated search. Bolt provides new opportunities to rethink end-to-end tensor optimizations at the graph, operator, and model levels. Bolt demonstrates this concept by prototyping on a popular auto-tuner in TVM and a class of widely-used platforms (i.e., NVIDIA GPUs) -- both in large deployment in our production environment. Bolt improves the inference speed of common convolutional neural networks by 2.5x on average over the state of the art, and it auto-tunes these models within 20 minutes.
An End-to-End Autofocus Camera for Iris on the Move
Jun 29, 2021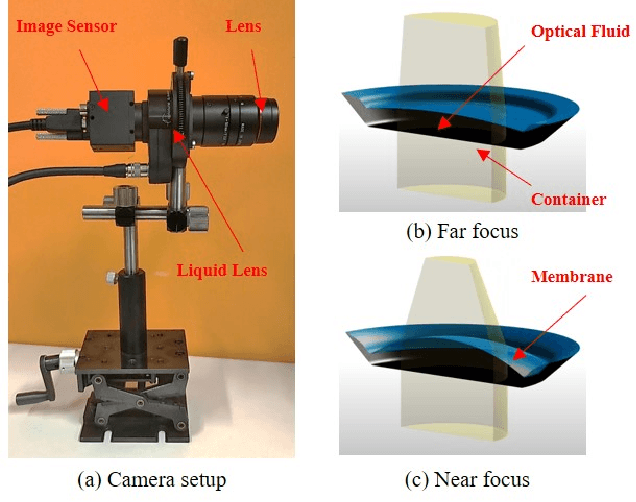

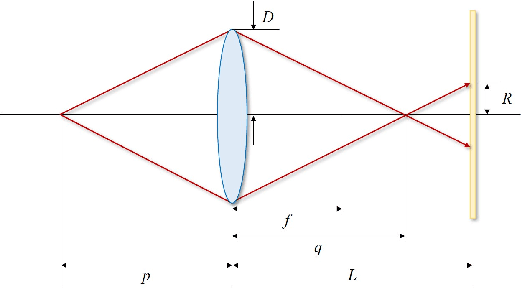
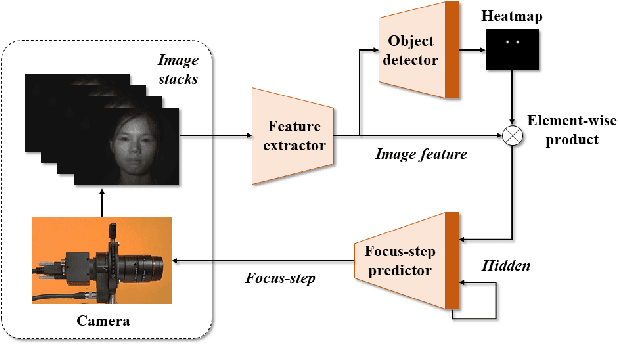
For distant iris recognition, a long focal length lens is generally used to ensure the resolution ofiris images, which reduces the depth of field and leads to potential defocus blur. To accommodate users at different distances, it is necessary to control focus quickly and accurately. While for users in motion, it is expected to maintain the correct focus on the iris area continuously. In this paper, we introduced a novel rapid autofocus camera for active refocusing ofthe iris area ofthe moving objects using a focus-tunable lens. Our end-to-end computational algorithm can predict the best focus position from one single blurred image and generate a lens diopter control signal automatically. This scene-based active manipulation method enables real-time focus tracking of the iris area ofa moving object. We built a testing bench to collect real-world focal stacks for evaluation of the autofocus methods. Our camera has reached an autofocus speed ofover 50 fps. The results demonstrate the advantages of our proposed camera for biometric perception in static and dynamic scenes. The code is available at https://github.com/Debatrix/AquulaCam.
UNIT: Unifying Tensorized Instruction Compilation
Jan 21, 2021

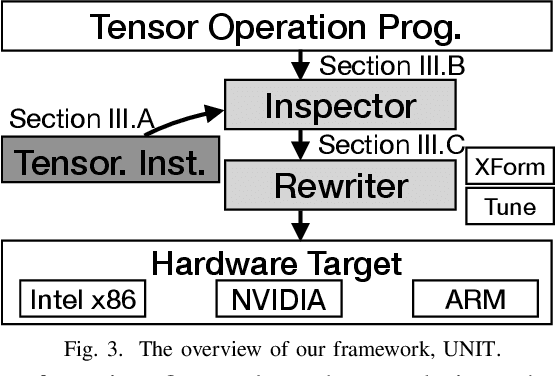

Because of the increasing demand for computation in DNN, researchers develope both hardware and software mechanisms to reduce the compute and memory burden. A widely adopted approach is to use mixed precision data types. However, it is hard to leverage mixed precision without hardware support because of the overhead of data casting. Hardware vendors offer tensorized instructions for mixed-precision tensor operations, like Intel VNNI, Tensor Core, and ARM-DOT. These instructions involve a computing idiom that reduces multiple low precision elements into one high precision element. The lack of compilation techniques for this makes it hard to utilize these instructions: Using vendor-provided libraries for computationally-intensive kernels is inflexible and prevents further optimizations, and manually writing hardware intrinsics is error-prone and difficult for programmers. Some prior works address this problem by creating compilers for each instruction. This requires excessive effort when it comes to many tensorized instructions. In this work, we develop a compiler framework to unify the compilation for these instructions -- a unified semantics abstraction eases the integration of new instructions, and reuses the analysis and transformations. Tensorized instructions from different platforms can be compiled via UNIT with moderate effort for favorable performance. Given a tensorized instruction and a tensor operation, UNIT automatically detects the applicability, transforms the loop organization of the operation,and rewrites the loop body to leverage the tensorized instruction. According to our evaluation, UNIT can target various mainstream hardware platforms. The generated end-to-end inference model achieves 1.3x speedup over Intel oneDNN on an x86 CPU, 1.75x speedup over Nvidia cuDNN on an NvidiaGPU, and 1.13x speedup over a carefully tuned TVM solution for ARM DOT on an ARM CPU.
HAWQV3: Dyadic Neural Network Quantization
Nov 20, 2020
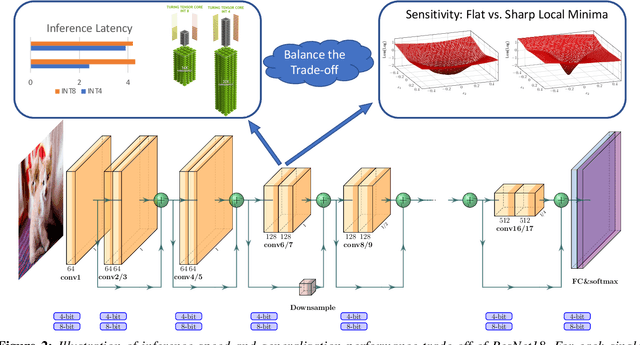
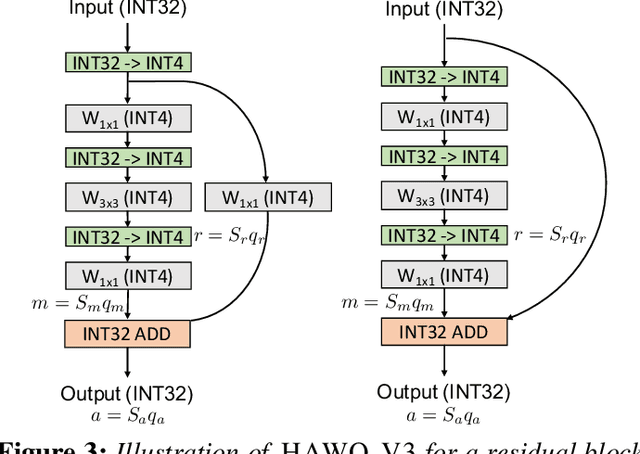
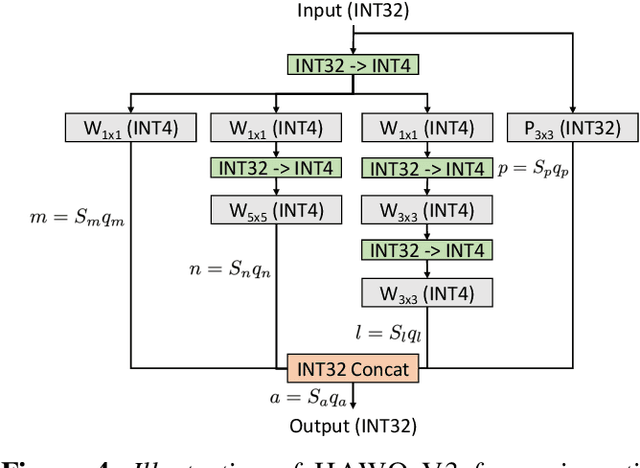
Quantization is one of the key techniques used to make Neural Networks (NNs) faster and more energy efficient. However, current low precision quantization algorithms often have the hidden cost of conversion back and forth from floating point to quantized integer values. This hidden cost limits the latency improvement realized by quantizing NNs. To address this, we present HAWQV3, a novel dyadic quantization framework. The contributions of HAWQV3 are the following. (i) The entire inference process consists of only integer multiplication, addition, and bit shifting in INT4/8 mixed precision, without any floating point operations/casting or even integer division. (ii) We pose the mixed-precision quantization as an integer linear programming problem, where the bit precision setting is computed to minimize model perturbation, while observing application specific constraints on memory footprint, latency, and BOPS. (iii) To verify our approach, we develop the first open source 4-bit mixed-precision quantization in TVM, and we directly deploy the quantized models to T4 GPUs using only the Turing Tensor Cores. We observe an average speed up of $1.45\times$ for uniform 4-bit, as compared to uniform 8-bit, precision for ResNet50. (iv) We extensively test the proposed dyadic quantization approach on multiple different NNs, including ResNet18/50 and InceptionV3, for various model compression levels with/without mixed precision. For instance, we achieve an accuracy of $78.50\%$ with dyadic INT8 quantization, which is more than $4\%$ higher than prior integer-only work for InceptionV3. Furthermore, we show that mixed-precision INT4/8 quantization can be used to achieve higher speed ups, as compared to INT8 inference, with minimal impact on accuracy. For example, for ResNet50 we can reduce INT8 latency by $23\%$ with mixed precision and still achieve $76.73\%$ accuracy.
Recognition Oriented Iris Image Quality Assessment in the Feature Space
Sep 27, 2020



A large portion of iris images captured in real world scenarios are poor quality due to the uncontrolled environment and the non-cooperative subject. To ensure that the recognition algorithm is not affected by low-quality images, traditional hand-crafted factors based methods discard most images, which will cause system timeout and disrupt user experience. In this paper, we propose a recognition-oriented quality metric and assessment method for iris image to deal with the problem. The method regards the iris image embeddings Distance in Feature Space (DFS) as the quality metric and the prediction is based on deep neural networks with the attention mechanism. The quality metric proposed in this paper can significantly improve the performance of the recognition algorithm while reducing the number of images discarded for recognition, which is advantageous over hand-crafted factors based iris quality assessment methods. The relationship between Image Rejection Rate (IRR) and Equal Error Rate (EER) is proposed to evaluate the performance of the quality assessment algorithm under the same image quality distribution and the same recognition algorithm. Compared with hand-crafted factors based methods, the proposed method is a trial to bridge the gap between the image quality assessment and biometric recognition. The code is available at https://github.com/Debatrix/DFSNet.
Face Anti-Spoofing by Learning Polarization Cues in a Real-World Scenario
Mar 19, 2020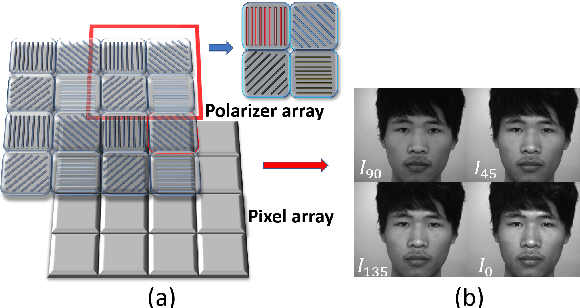

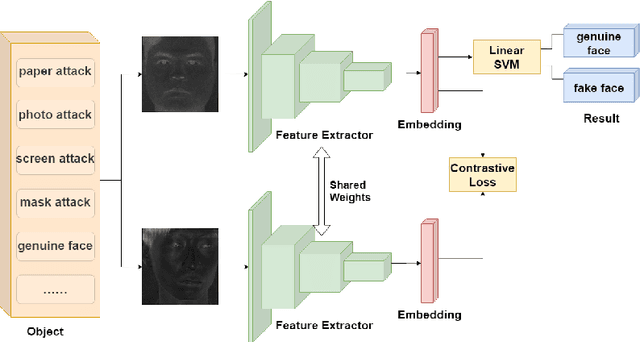
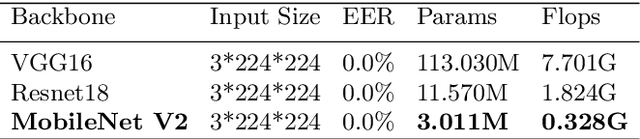
Face anti-spoofing is the key to preventing security breaches in biometric recognition applications. Existing software-based and hardware-based face liveness detection methods are effective in constrained environments or designated datasets only. Deep learning method using RGB and infrared images demands a large amount of training data for new attacks. In this paper, we present a face anti-spoofing method in a real-world scenario by automatic learning the physical characteristics in polarization images of a real face compared to a deceptive attack. A computational framework is developed to extract and classify the unique face features using convolutional neural networks and SVM together. Our real-time polarized face anti-spoofing (PAAS) detection method uses a on-chip integrated polarization imaging sensor with optimized processing algorithms. Extensive experiments demonstrate the advantages of the PAAS technique to counter diverse face spoofing attacks (print, replay, mask) in uncontrolled indoor and outdoor conditions by learning polarized face images of 33 people. A four-directional polarized face image dataset is released to inspire future applications within biometric anti-spoofing field.
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
Oct 05, 2018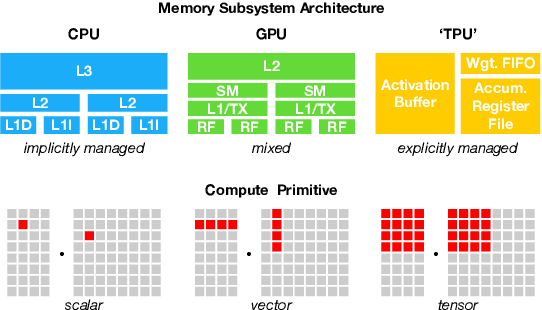
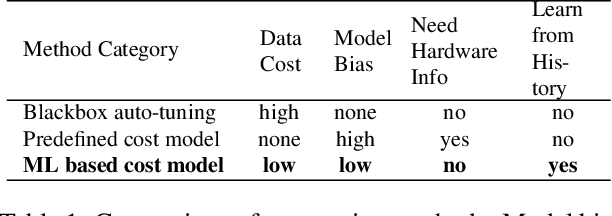
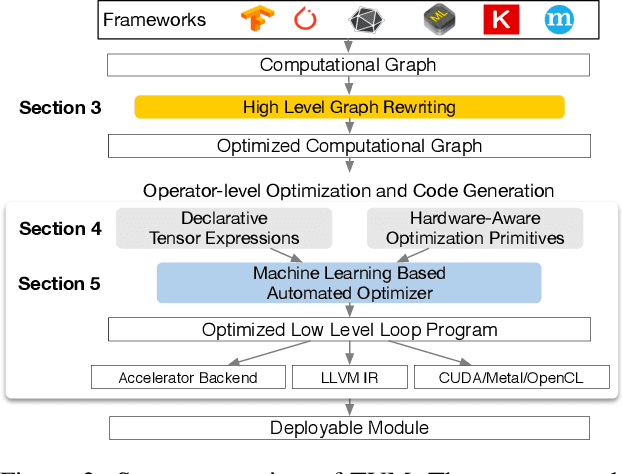
There is an increasing need to bring machine learning to a wide diversity of hardware devices. Current frameworks rely on vendor-specific operator libraries and optimize for a narrow range of server-class GPUs. Deploying workloads to new platforms -- such as mobile phones, embedded devices, and accelerators (e.g., FPGAs, ASICs) -- requires significant manual effort. We propose TVM, a compiler that exposes graph-level and operator-level optimizations to provide performance portability to deep learning workloads across diverse hardware back-ends. TVM solves optimization challenges specific to deep learning, such as high-level operator fusion, mapping to arbitrary hardware primitives, and memory latency hiding. It also automates optimization of low-level programs to hardware characteristics by employing a novel, learning-based cost modeling method for rapid exploration of code optimizations. Experimental results show that TVM delivers performance across hardware back-ends that are competitive with state-of-the-art, hand-tuned libraries for low-power CPU, mobile GPU, and server-class GPUs. We also demonstrate TVM's ability to target new accelerator back-ends, such as the FPGA-based generic deep learning accelerator. The system is open sourced and in production use inside several major companies.