 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBolt: Bridging the Gap between Auto-tuners and Hardware-native Performance
Paper and Code
Oct 25, 2021
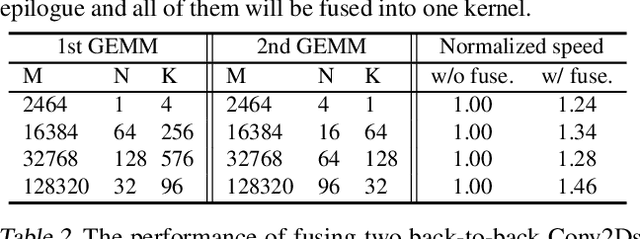

Today's auto-tuners (e.g., AutoTVM, Ansor) generate efficient tensor programs by navigating a large search space to identify effective implementations, but they do so with opaque hardware details. Thus, their performance could fall behind that of hardware-native libraries (e.g., cuBLAS, cuDNN), which are hand-optimized by device vendors to extract high performance. On the other hand, these vendor libraries have a fixed set of supported functions and lack the customization and automation support afforded by auto-tuners. Bolt is based on the recent trend that vendor libraries are increasingly modularized and reconfigurable via declarative control (e.g., CUTLASS). It enables a novel approach that bridges this gap and achieves the best of both worlds, via hardware-native templated search. Bolt provides new opportunities to rethink end-to-end tensor optimizations at the graph, operator, and model levels. Bolt demonstrates this concept by prototyping on a popular auto-tuner in TVM and a class of widely-used platforms (i.e., NVIDIA GPUs) -- both in large deployment in our production environment. Bolt improves the inference speed of common convolutional neural networks by 2.5x on average over the state of the art, and it auto-tunes these models within 20 minutes.