 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2-Router: A New Paradigm for LLM Routing with Reasoning
Feb 02, 2026As LLMs proliferate with diverse capabilities and costs, LLM routing has emerged by learning to predict each LLM's quality and cost for a given query, then selecting the one with high quality and low cost. However, existing routers implicitly assume a single fixed quality and cost per LLM for each query, ignoring that the same LLM's quality varies with its output length. This causes routers to exclude powerful LLMs when their estimated cost exceeds the budget, missing the opportunity that these LLMs could still deliver high quality at reduced cost with shorter outputs. To address this, we introduce R2-Router, which treats output length budget as a controllable variable and jointly selects the best LLM and length budget, enforcing the budget via length-constrained instructions. This enables R2-Router to discover that a powerful LLM with constrained output can outperform a weaker LLM at comparable cost-efficient configurations invisible to prior methods. Together with the router framework, we construct R2-Bench, the first routing dataset capturing LLM behavior across diverse output length budgets. Experiments show that R2-Router achieves state-of-the-art performance at 4-5x lower cost compared with existing routers. This work opens a new direction: routing as reasoning, where routers evolve from reactive selectors to deliberate reasoners that explore which LLM to use and at what cost budget.
Let the Barbarians In: How AI Can Accelerate Systems Performance Research
Dec 22, 2025Artificial Intelligence (AI) is beginning to transform the research process by automating the discovery of new solutions. This shift depends on the availability of reliable verifiers, which AI-driven approaches require to validate candidate solutions. Research focused on improving systems performance is especially well-suited to this paradigm because system performance problems naturally admit such verifiers: candidates can be implemented in real systems or simulators and evaluated against predefined workloads. We term this iterative cycle of generation, evaluation, and refinement AI-Driven Research for Systems (ADRS). Using several open-source ADRS instances (i.e., OpenEvolve, GEPA, and ShinkaEvolve), we demonstrate across ten case studies (e.g., multi-region cloud scheduling, mixture-of-experts load balancing, LLM-based SQL, transaction scheduling) that ADRS-generated solutions can match or even outperform human state-of-the-art designs. Based on these findings, we outline best practices (e.g., level of prompt specification, amount of feedback, robust evaluation) for effectively using ADRS, and we discuss future research directions and their implications. Although we do not yet have a universal recipe for applying ADRS across all of systems research, we hope our preliminary findings, together with the challenges we identify, offer meaningful guidance for future work as researcher effort shifts increasingly toward problem formulation and strategic oversight. Note: This paper is an extension of our prior work [14]. It adds extensive evaluation across multiple ADRS frameworks and provides deeper analysis and insights into best practices.
EXP-Bench: Can AI Conduct AI Research Experiments?
May 30, 2025



Automating AI research holds immense potential for accelerating scientific progress, yet current AI agents struggle with the complexities of rigorous, end-to-end experimentation. We introduce EXP-Bench, a novel benchmark designed to systematically evaluate AI agents on complete research experiments sourced from influential AI publications. Given a research question and incomplete starter code, EXP-Bench challenges AI agents to formulate hypotheses, design and implement experimental procedures, execute them, and analyze results. To enable the creation of such intricate and authentic tasks with high-fidelity, we design a semi-autonomous pipeline to extract and structure crucial experimental details from these research papers and their associated open-source code. With the pipeline, EXP-Bench curated 461 AI research tasks from 51 top-tier AI research papers. Evaluations of leading LLM-based agents, such as OpenHands and IterativeAgent on EXP-Bench demonstrate partial capabilities: while scores on individual experimental aspects such as design or implementation correctness occasionally reach 20-35%, the success rate for complete, executable experiments was a mere 0.5%. By identifying these bottlenecks and providing realistic step-by-step experiment procedures, EXP-Bench serves as a vital tool for future AI agents to improve their ability to conduct AI research experiments. EXP-Bench is open-sourced at https://github.com/Just-Curieous/Curie/tree/main/benchmark/exp_bench.
Prism: Unleashing GPU Sharing for Cost-Efficient Multi-LLM Serving
May 06, 2025



Serving large language models (LLMs) is expensive, especially for providers hosting many models, making cost reduction essential. The unique workload patterns of serving multiple LLMs (i.e., multi-LLM serving) create new opportunities and challenges for this task. The long-tail popularity of models and their long idle periods present opportunities to improve utilization through GPU sharing. However, existing GPU sharing systems lack the ability to adjust their resource allocation and sharing policies at runtime, making them ineffective at meeting latency service-level objectives (SLOs) under rapidly fluctuating workloads. This paper presents Prism, a multi-LLM serving system that unleashes the full potential of GPU sharing to achieve both cost efficiency and SLO attainment. At its core, Prism tackles a key limitation of existing systems$\unicode{x2014}$the lack of $\textit{cross-model memory coordination}$, which is essential for flexibly sharing GPU memory across models under dynamic workloads. Prism achieves this with two key designs. First, it supports on-demand memory allocation by dynamically mapping physical to virtual memory pages, allowing flexible memory redistribution among models that space- and time-share a GPU. Second, it improves memory efficiency through a two-level scheduling policy that dynamically adjusts sharing strategies based on models' runtime demands. Evaluations on real-world traces show that Prism achieves more than $2\times$ cost savings and $3.3\times$ SLO attainment compared to state-of-the-art systems.
S*: Test Time Scaling for Code Generation
Feb 20, 2025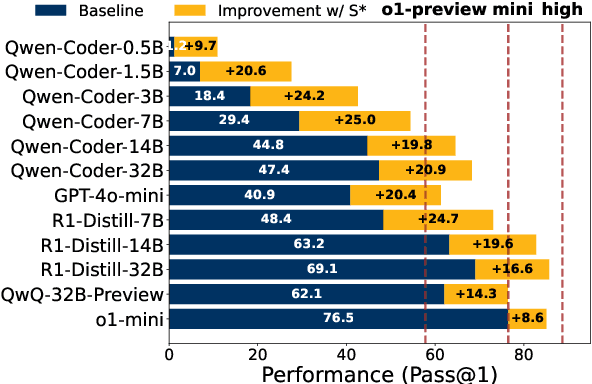
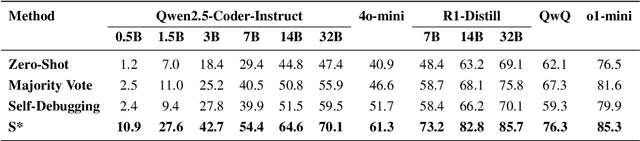
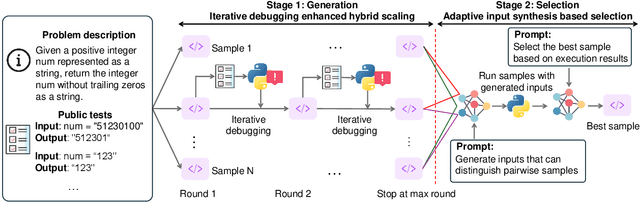
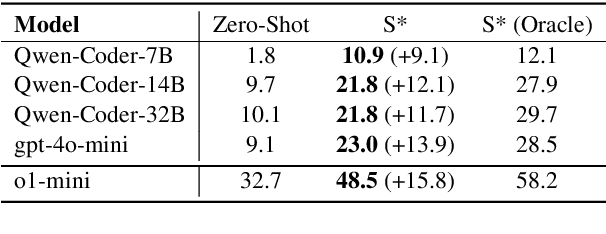
Increasing test-time compute for LLMs shows promise across domains but remains underexplored in code generation, despite extensive study in math. In this paper, we propose S*, the first hybrid test-time scaling framework that substantially improves the coverage and selection accuracy of generated code. S* extends the existing parallel scaling paradigm with sequential scaling to push performance boundaries. It further leverages a novel selection mechanism that adaptively generates distinguishing inputs for pairwise comparison, combined with execution-grounded information to robustly identify correct solutions. We evaluate across 12 Large Language Models and Large Reasoning Model and show: (1) S* consistently improves performance across model families and sizes, enabling a 3B model to outperform GPT-4o-mini; (2) S* enables non-reasoning models to surpass reasoning models - GPT-4o-mini with S* outperforms o1-preview by 3.7% on LiveCodeBench; (3) S* further boosts state-of-the-art reasoning models - DeepSeek-R1-Distill-Qwen-32B with S* achieves 85.7% on LiveCodeBench, approaching o1 (high) at 88.5%. Code will be available under https://github.com/NovaSky-AI/SkyThought.
BlendServe: Optimizing Offline Inference for Auto-regressive Large Models with Resource-aware Batching
Nov 25, 2024



Offline batch inference, which leverages the flexibility of request batching to achieve higher throughput and lower costs, is becoming more popular for latency-insensitive applications. Meanwhile, recent progress in model capability and modality makes requests more diverse in compute and memory demands, creating unique opportunities for throughput improvement by resource overlapping. However, a request schedule that maximizes resource overlapping can conflict with the schedule that maximizes prefix sharing, a widely-used performance optimization, causing sub-optimal inference throughput. We present BlendServe, a system that maximizes resource utilization of offline batch inference by combining the benefits of resource overlapping and prefix sharing using a resource-aware prefix tree. BlendServe exploits the relaxed latency requirements in offline batch inference to reorder and overlap requests with varied resource demands while ensuring high prefix sharing. We evaluate BlendServe on a variety of synthetic multi-modal workloads and show that it provides up to $1.44\times$ throughput boost compared to widely-used industry standards, vLLM and SGLang.
Symbolic Distillation for Learned TCP Congestion Control
Oct 24, 2022



Recent advances in TCP congestion control (CC) have achieved tremendous success with deep reinforcement learning (RL) approaches, which use feedforward neural networks (NN) to learn complex environment conditions and make better decisions. However, such "black-box" policies lack interpretability and reliability, and often, they need to operate outside the traditional TCP datapath due to the use of complex NNs. This paper proposes a novel two-stage solution to achieve the best of both worlds: first to train a deep RL agent, then distill its (over-)parameterized NN policy into white-box, light-weight rules in the form of symbolic expressions that are much easier to understand and to implement in constrained environments. At the core of our proposal is a novel symbolic branching algorithm that enables the rule to be aware of the context in terms of various network conditions, eventually converting the NN policy into a symbolic tree. The distilled symbolic rules preserve and often improve performance over state-of-the-art NN policies while being faster and simpler than a standard neural network. We validate the performance of our distilled symbolic rules on both simulation and emulation environments. Our code is available at https://github.com/VITA-Group/SymbolicPCC.
Bolt: Bridging the Gap between Auto-tuners and Hardware-native Performance
Oct 25, 2021
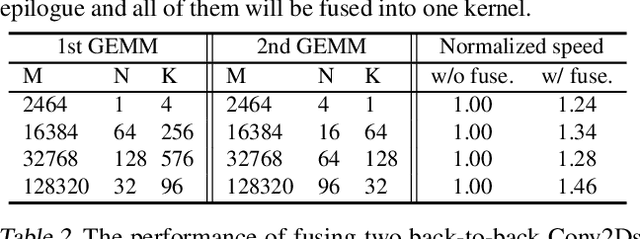
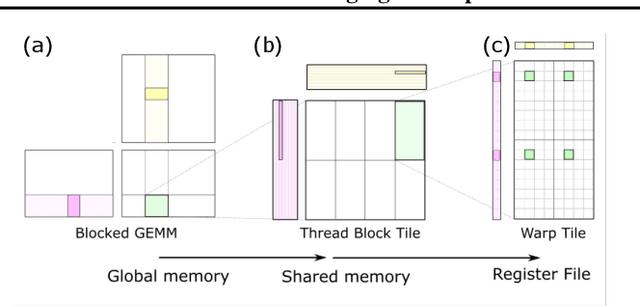

Today's auto-tuners (e.g., AutoTVM, Ansor) generate efficient tensor programs by navigating a large search space to identify effective implementations, but they do so with opaque hardware details. Thus, their performance could fall behind that of hardware-native libraries (e.g., cuBLAS, cuDNN), which are hand-optimized by device vendors to extract high performance. On the other hand, these vendor libraries have a fixed set of supported functions and lack the customization and automation support afforded by auto-tuners. Bolt is based on the recent trend that vendor libraries are increasingly modularized and reconfigurable via declarative control (e.g., CUTLASS). It enables a novel approach that bridges this gap and achieves the best of both worlds, via hardware-native templated search. Bolt provides new opportunities to rethink end-to-end tensor optimizations at the graph, operator, and model levels. Bolt demonstrates this concept by prototyping on a popular auto-tuner in TVM and a class of widely-used platforms (i.e., NVIDIA GPUs) -- both in large deployment in our production environment. Bolt improves the inference speed of common convolutional neural networks by 2.5x on average over the state of the art, and it auto-tunes these models within 20 minutes.