 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlm-mux: Orchestrating small language models for reasoning
Oct 06, 2025With the rapid development of language models, the number of small language models (SLMs) has grown significantly. Although they do not achieve state-of-the-art accuracy, they are more efficient and often excel at specific tasks. This raises a natural question: can multiple SLMs be orchestrated into a system where each contributes effectively, achieving higher accuracy than any individual model? Existing orchestration methods have primarily targeted frontier models (e.g., GPT-4) and perform suboptimally when applied to SLMs. To address this gap, we propose a three-stage approach for orchestrating SLMs. First, we introduce SLM-MUX, a multi-model architecture that effectively coordinates multiple SLMs. Building on this, we develop two optimization strategies: (i) a model selection search that identifies the most complementary SLMs from a given pool, and (ii) test-time scaling tailored to SLM-MUX. Our approach delivers strong results: Compared to existing orchestration methods, our approach achieves up to 13.4% improvement on MATH, 8.8% on GPQA, and 7.0% on GSM8K. With just two SLMS, SLM-MUX outperforms Qwen 2.5 72B on GPQA and GSM8K, and matches its performance on MATH. We further provide theoretical analyses to substantiate the advantages of our method. In summary, we demonstrate that SLMs can be effectively orchestrated into more accurate and efficient systems through the proposed approach.
Prism: Unleashing GPU Sharing for Cost-Efficient Multi-LLM Serving
May 06, 2025



Serving large language models (LLMs) is expensive, especially for providers hosting many models, making cost reduction essential. The unique workload patterns of serving multiple LLMs (i.e., multi-LLM serving) create new opportunities and challenges for this task. The long-tail popularity of models and their long idle periods present opportunities to improve utilization through GPU sharing. However, existing GPU sharing systems lack the ability to adjust their resource allocation and sharing policies at runtime, making them ineffective at meeting latency service-level objectives (SLOs) under rapidly fluctuating workloads. This paper presents Prism, a multi-LLM serving system that unleashes the full potential of GPU sharing to achieve both cost efficiency and SLO attainment. At its core, Prism tackles a key limitation of existing systems$\unicode{x2014}$the lack of $\textit{cross-model memory coordination}$, which is essential for flexibly sharing GPU memory across models under dynamic workloads. Prism achieves this with two key designs. First, it supports on-demand memory allocation by dynamically mapping physical to virtual memory pages, allowing flexible memory redistribution among models that space- and time-share a GPU. Second, it improves memory efficiency through a two-level scheduling policy that dynamically adjusts sharing strategies based on models' runtime demands. Evaluations on real-world traces show that Prism achieves more than $2\times$ cost savings and $3.3\times$ SLO attainment compared to state-of-the-art systems.
Self-Generated In-Context Examples Improve LLM Agents for Sequential Decision-Making Tasks
May 02, 2025Many methods for improving Large Language Model (LLM) agents for sequential decision-making tasks depend on task-specific knowledge engineering--such as prompt tuning, curated in-context examples, or customized observation and action spaces. Using these approaches, agent performance improves with the quality or amount of knowledge engineering invested. Instead, we investigate how LLM agents can automatically improve their performance by learning in-context from their own successful experiences on similar tasks. Rather than relying on task-specific knowledge engineering, we focus on constructing and refining a database of self-generated examples. We demonstrate that even a naive accumulation of successful trajectories across training tasks boosts test performance on three benchmarks: ALFWorld (73% to 89%), Wordcraft (55% to 64%), and InterCode-SQL (75% to 79%)--matching the performance the initial agent achieves if allowed two to three attempts per task. We then introduce two extensions: (1) database-level selection through population-based training to identify high-performing example collections, and (2) exemplar-level selection that retains individual trajectories based on their empirical utility as in-context examples. These extensions further enhance performance, achieving 91% on ALFWorld--matching more complex approaches that employ task-specific components and prompts. Our results demonstrate that automatic trajectory database construction offers a compelling alternative to labor-intensive knowledge engineering.
AI Metropolis: Scaling Large Language Model-based Multi-Agent Simulation with Out-of-order Execution
Nov 05, 2024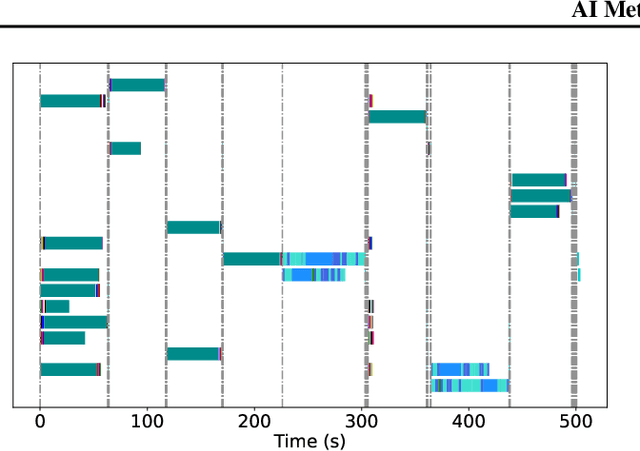
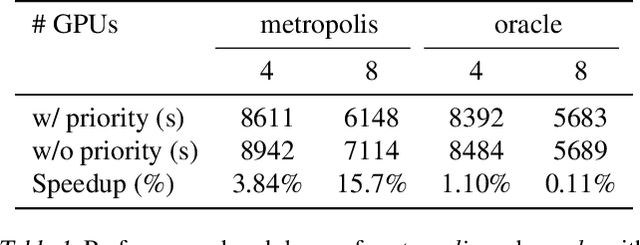
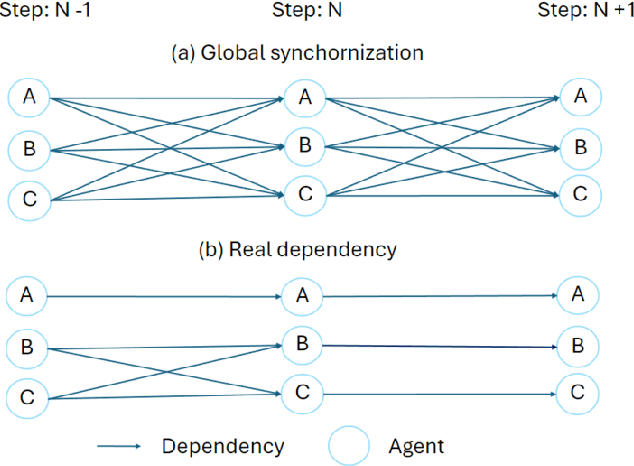
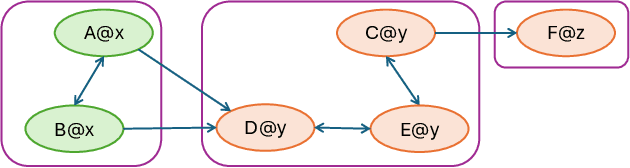
With more advanced natural language understanding and reasoning capabilities, large language model (LLM)-powered agents are increasingly developed in simulated environments to perform complex tasks, interact with other agents, and exhibit emergent behaviors relevant to social science and gaming. However, current multi-agent simulations frequently suffer from inefficiencies due to the limited parallelism caused by false dependencies, resulting in performance bottlenecks. In this paper, we introduce AI Metropolis, a simulation engine that improves the efficiency of LLM agent simulations by incorporating out-of-order execution scheduling. By dynamically tracking real dependencies between agents, AI Metropolis minimizes false dependencies, enhancing parallelism and enabling efficient hardware utilization. Our evaluations demonstrate that AI Metropolis achieves speedups from 1.3x to 4.15x over standard parallel simulation with global synchronization, approaching optimal performance as the number of agents increases.
RoboTwin: Dual-Arm Robot Benchmark with Generative Digital Twins (early version)
Sep 04, 2024



Effective collaboration of dual-arm robots and their tool use capabilities are increasingly important areas in the advancement of robotics. These skills play a significant role in expanding robots' ability to operate in diverse real-world environments. However, progress is impeded by the scarcity of specialized training data. This paper introduces RoboTwin, a novel benchmark dataset combining real-world teleoperated data with synthetic data from digital twins, designed for dual-arm robotic scenarios. Using the COBOT Magic platform, we have collected diverse data on tool usage and human-robot interaction. We present a innovative approach to creating digital twins using AI-generated content, transforming 2D images into detailed 3D models. Furthermore, we utilize large language models to generate expert-level training data and task-specific pose sequences oriented toward functionality. Our key contributions are: 1) the RoboTwin benchmark dataset, 2) an efficient real-to-simulation pipeline, and 3) the use of language models for automatic expert-level data generation. These advancements are designed to address the shortage of robotic training data, potentially accelerating the development of more capable and versatile robotic systems for a wide range of real-world applications. The project page is available at https://robotwin-benchmark.github.io/early-version/
Cloud Atlas: Efficient Fault Localization for Cloud Systems using Language Models and Causal Insight
Jul 11, 2024Runtime failure and performance degradation is commonplace in modern cloud systems. For cloud providers, automatically determining the root cause of incidents is paramount to ensuring high reliability and availability as prompt fault localization can enable faster diagnosis and triage for timely resolution. A compelling solution explored in recent work is causal reasoning using causal graphs to capture relationships between varied cloud system performance metrics. To be effective, however, systems developers must correctly define the causal graph of their system, which is a time-consuming, brittle, and challenging task that increases in difficulty for large and dynamic systems and requires domain expertise. Alternatively, automated data-driven approaches have limited efficacy for cloud systems due to the inherent rarity of incidents. In this work, we present Atlas, a novel approach to automatically synthesizing causal graphs for cloud systems. Atlas leverages large language models (LLMs) to generate causal graphs using system documentation, telemetry, and deployment feedback. Atlas is complementary to data-driven causal discovery techniques, and we further enhance Atlas with a data-driven validation step. We evaluate Atlas across a range of fault localization scenarios and demonstrate that Atlas is capable of generating causal graphs in a scalable and generalizable manner, with performance that far surpasses that of data-driven algorithms and is commensurate to the ground-truth baseline.
CRAB: Cross-environment Agent Benchmark for Multimodal Language Model Agents
Jul 01, 2024



The development of autonomous agents increasingly relies on Multimodal Language Models (MLMs) to perform tasks described in natural language with GUI environments, such as websites, desktop computers, or mobile phones. Existing benchmarks for MLM agents in interactive environments are limited by their focus on a single environment, lack of detailed and generalized evaluation methods, and the complexities of constructing tasks and evaluators. To overcome these limitations, we introduce Crab, the first agent benchmark framework designed to support cross-environment tasks, incorporating a graph-based fine-grained evaluation method and an efficient mechanism for task and evaluator construction. Our framework supports multiple devices and can be easily extended to any environment with a Python interface. Leveraging Crab, we developed a cross-platform Crab Benchmark-v0 comprising 100 tasks in computer desktop and mobile phone environments. We evaluated four advanced MLMs using different single and multi-agent system configurations on this benchmark. The experimental results demonstrate that the single agent with GPT-4o achieves the best completion ratio of 35.26%. All framework code, agent code, and task datasets are publicly available at https://github.com/camel-ai/crab.
Blockchain-enabled Trustworthy Federated Unlearning
Jan 29, 2024Federated unlearning is a promising paradigm for protecting the data ownership of distributed clients. It allows central servers to remove historical data effects within the machine learning model as well as address the "right to be forgotten" issue in federated learning. However, existing works require central servers to retain the historical model parameters from distributed clients, such that allows the central server to utilize these parameters for further training even, after the clients exit the training process. To address this issue, this paper proposes a new blockchain-enabled trustworthy federated unlearning framework. We first design a proof of federated unlearning protocol, which utilizes the Chameleon hash function to verify data removal and eliminate the data contributions stored in other clients' models. Then, an adaptive contribution-based retraining mechanism is developed to reduce the computational overhead and significantly improve the training efficiency. Extensive experiments demonstrate that the proposed framework can achieve a better data removal effect than the state-of-the-art frameworks, marking a significant stride towards trustworthy federated unlearning.
Efficiently Programming Large Language Models using SGLang
Dec 12, 2023Large language models (LLMs) are increasingly used for complex tasks requiring multiple chained generation calls, advanced prompting techniques, control flow, and interaction with external environments. However, efficient systems for programming and executing these applications are lacking. To bridge this gap, we introduce SGLang, a Structured Generation Language for LLMs. SGLang is designed for the efficient programming of LLMs and incorporates primitives for common LLM programming patterns. We have implemented SGLang as a domain-specific language embedded in Python, and we developed an interpreter, a compiler, and a high-performance runtime for SGLang. These components work together to enable optimizations such as parallelism, batching, caching, sharing, and other compilation techniques. Additionally, we propose RadixAttention, a novel technique that maintains a Least Recently Used (LRU) cache of the Key-Value (KV) cache for all requests in a radix tree, enabling automatic KV cache reuse across multiple generation calls at runtime. SGLang simplifies the writing of LLM programs and boosts execution efficiency. Our experiments demonstrate that SGLang can speed up common LLM tasks by up to 5x, while reducing code complexity and enhancing control.
High-throughput Generative Inference of Large Language Models with a Single GPU
Mar 13, 2023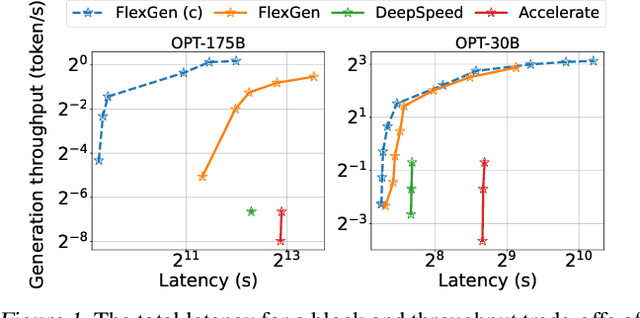

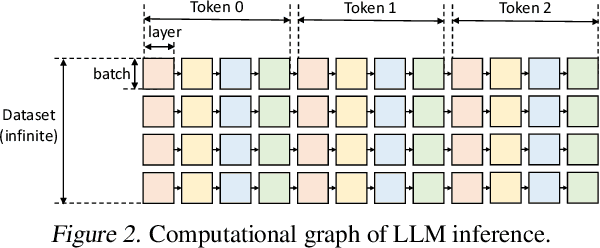
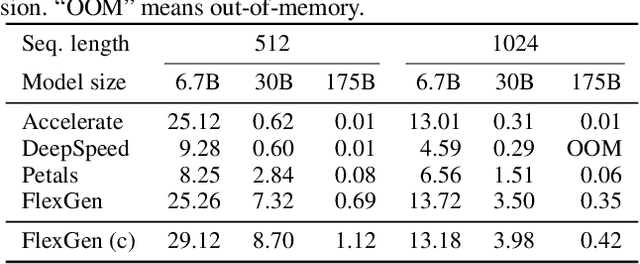
The high computational and memory requirements of large language model (LLM) inference traditionally make it feasible only with multiple high-end accelerators. Motivated by the emerging demand for latency-insensitive tasks with batched processing, this paper initiates the study of high-throughput LLM inference using limited resources, such as a single commodity GPU. We present FlexGen, a high-throughput generation engine for running LLMs with limited GPU memory. FlexGen can be flexibly configured under various hardware resource constraints by aggregating memory and computation from the GPU, CPU, and disk. Through a linear programming optimizer, it searches for efficient patterns to store and access tensors. FlexGen further compresses these weights and the attention cache to 4 bits with negligible accuracy loss. These techniques enable FlexGen to have a larger space of batch size choices and thus significantly increase maximum throughput. As a result, when running OPT-175B on a single 16GB GPU, FlexGen achieves significantly higher throughput compared to state-of-the-art offloading systems, reaching a generation throughput of 1 token/s for the first time with an effective batch size of 144. On the HELM benchmark, FlexGen can benchmark a 30B model with a 16GB GPU on 7 representative sub-scenarios in 21 hours. The code is available at https://github.com/FMInference/FlexGen