 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing-Aware Multimodal Fusion for Unified Microservice Incident Management
Mar 27, 2026Automated incident management is critical for microservice reliability. While recent unified frameworks leverage multimodal data for joint optimization, they unrealistically assume perfect data completeness. In practice, network fluctuations and agent failures frequently cause missing modalities. Existing approaches relying on static placeholders introduce imputation noise that masks anomalies and degrades performance. To address this, we propose ARMOR, a robust self-supervised framework designed for missing modality scenarios. ARMOR features: (i) a modality-specific asymmetric encoder that isolates distribution disparities among metrics, logs, and traces; and (ii) a missing-aware gated fusion mechanism utilizing learnable placeholders and dynamic bias compensation to prevent cross-modal interference from incomplete inputs. By employing self-supervised auto-regression with mask-guided reconstruction, ARMOR jointly optimizes anomaly detection (AD), failure triage (FT), and root cause localization (RCL). AD and RCL require no fault labels, while FT relies solely on failure-type annotations for the downstream classifier. Extensive experiments demonstrate that ARMOR achieves state-of-the-art performance under complete data conditions and maintains robust diagnostic accuracy even with severe modality loss.
Optimal Short Video Ordering and Transmission Scheduling for Reducing Video Delivery Cost in Peer-to-Peer CDNs
Mar 04, 2026The explosive growth of short video platforms has generated a massive surge in global traffic, imposing heavy financial burdens on content providers. While Peer-to-Peer Content Delivery Networks (PCDNs) offer a cost-effective alternative by leveraging resource-constrained edge nodes, the limited storage and concurrent service capacities of these peers struggle to absorb the intense temporal demand spikes characteristic of short video consumption. In this paper, we propose to minimize transmission costs by exploiting a novel degree of freedom, the inherent flexibility of server-driven playback sequences. We formulate the Optimal Video Ordering and Transmission Scheduling (OVOTS) problem as an Integer Linear Program to jointly optimize personalized video ordering and transmission scheduling. By strategically permuting playlists, our approach proactively smooths temporal traffic peaks, maximizing the offloading of requests to low-cost peer nodes. To solve the OVOTS problem, we provide a rigorous theoretical reduction of the OVOTS problem to an auxiliary Minimum Cost Maximum Flow (MCMF) formulation. Leveraging König's Edge Coloring Theorem, we prove the strict equivalence of these formulations and develop the Minimum-cost Maximum-flow with Edge Coloring (MMEC) algorithm, a globally optimal, polynomial-time solution. Extensive simulations demonstrate that MMEC significantly outperforms baseline strategies, achieving cost reductions of up to 67% compared to random scheduling and 36% compared to a simulated annealing approach. Our results establish playback sequence flexibility as a robust and highly effective paradigm for cost optimization in PCDN architectures.
Learner-Tailored Program Repair: A Solution Generator with Iterative Edit-Driven Retrieval Enhancement
Jan 13, 2026With the development of large language models (LLMs) in the field of programming, intelligent programming coaching systems have gained widespread attention. However, most research focuses on repairing the buggy code of programming learners without providing the underlying causes of the bugs. To address this gap, we introduce a novel task, namely \textbf{LPR} (\textbf{L}earner-Tailored \textbf{P}rogram \textbf{R}epair). We then propose a novel and effective framework, \textbf{\textsc{\MethodName{}}} (\textbf{L}earner-Tailored \textbf{S}olution \textbf{G}enerator), to enhance program repair while offering the bug descriptions for the buggy code. In the first stage, we utilize a repair solution retrieval framework to construct a solution retrieval database and then employ an edit-driven code retrieval approach to retrieve valuable solutions, guiding LLMs in identifying and fixing the bugs in buggy code. In the second stage, we propose a solution-guided program repair method, which fixes the code and provides explanations under the guidance of retrieval solutions. Moreover, we propose an Iterative Retrieval Enhancement method that utilizes evaluation results of the generated code to iteratively optimize the retrieval direction and explore more suitable repair strategies, improving performance in practical programming coaching scenarios. The experimental results show that our approach outperforms a set of baselines by a large margin, validating the effectiveness of our framework for the newly proposed LPR task.
Less is More: Adaptive Program Repair with Bug Localization and Preference Learning
Mar 09, 2025Automated Program Repair (APR) is a task to automatically generate patches for the buggy code. However, most research focuses on generating correct patches while ignoring the consistency between the fixed code and the original buggy code. How to conduct adaptive bug fixing and generate patches with minimal modifications have seldom been investigated. To bridge this gap, we first introduce a novel task, namely AdaPR (Adaptive Program Repair). We then propose a two-stage approach AdaPatcher (Adaptive Patch Generator) to enhance program repair while maintaining the consistency. In the first stage, we utilize a Bug Locator with self-debug learning to accurately pinpoint bug locations. In the second stage, we train a Program Modifier to ensure consistency between the post-modified fixed code and the pre-modified buggy code. The Program Modifier is enhanced with a location-aware repair learning strategy to generate patches based on identified buggy lines, a hybrid training strategy for selective reference and an adaptive preference learning to prioritize fewer changes. The experimental results show that our approach outperforms a set of baselines by a large margin, validating the effectiveness of our two-stage framework for the newly proposed AdaPR task.
MPCODER: Multi-user Personalized Code Generator with Explicit and Implicit Style Representation Learning
Jun 25, 2024


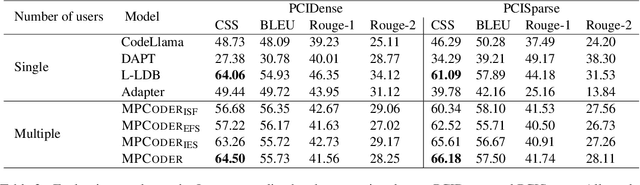
Large Language Models (LLMs) have demonstrated great potential for assisting developers in their daily development. However, most research focuses on generating correct code, how to use LLMs to generate personalized code has seldom been investigated. To bridge this gap, we proposed MPCoder (Multi-user Personalized Code Generator) to generate personalized code for multiple users. To better learn coding style features, we utilize explicit coding style residual learning to capture the syntax code style standards and implicit style learning to capture the semantic code style conventions. We train a multi-user style adapter to better differentiate the implicit feature representations of different users through contrastive learning, ultimately enabling personalized code generation for multiple users. We further propose a novel evaluation metric for estimating similarities between codes of different coding styles. The experimental results show the effectiveness of our approach for this novel task.
Scalable Federated Unlearning via Isolated and Coded Sharding
Jan 29, 2024

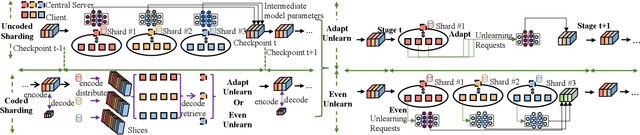

Federated unlearning has emerged as a promising paradigm to erase the client-level data effect without affecting the performance of collaborative learning models. However, the federated unlearning process often introduces extensive storage overhead and consumes substantial computational resources, thus hindering its implementation in practice. To address this issue, this paper proposes a scalable federated unlearning framework based on isolated sharding and coded computing. We first divide distributed clients into multiple isolated shards across stages to reduce the number of clients being affected. Then, to reduce the storage overhead of the central server, we develop a coded computing mechanism by compressing the model parameters across different shards. In addition, we provide the theoretical analysis of time efficiency and storage effectiveness for the isolated and coded sharding. Finally, extensive experiments on two typical learning tasks, i.e., classification and generation, demonstrate that our proposed framework can achieve better performance than three state-of-the-art frameworks in terms of accuracy, retraining time, storage overhead, and F1 scores for resisting membership inference attacks.
Blockchain-enabled Trustworthy Federated Unlearning
Jan 29, 2024Federated unlearning is a promising paradigm for protecting the data ownership of distributed clients. It allows central servers to remove historical data effects within the machine learning model as well as address the "right to be forgotten" issue in federated learning. However, existing works require central servers to retain the historical model parameters from distributed clients, such that allows the central server to utilize these parameters for further training even, after the clients exit the training process. To address this issue, this paper proposes a new blockchain-enabled trustworthy federated unlearning framework. We first design a proof of federated unlearning protocol, which utilizes the Chameleon hash function to verify data removal and eliminate the data contributions stored in other clients' models. Then, an adaptive contribution-based retraining mechanism is developed to reduce the computational overhead and significantly improve the training efficiency. Extensive experiments demonstrate that the proposed framework can achieve a better data removal effect than the state-of-the-art frameworks, marking a significant stride towards trustworthy federated unlearning.
FedSup: A Communication-Efficient Federated Learning Fatigue Driving Behaviors Supervision Framework
Apr 25, 2021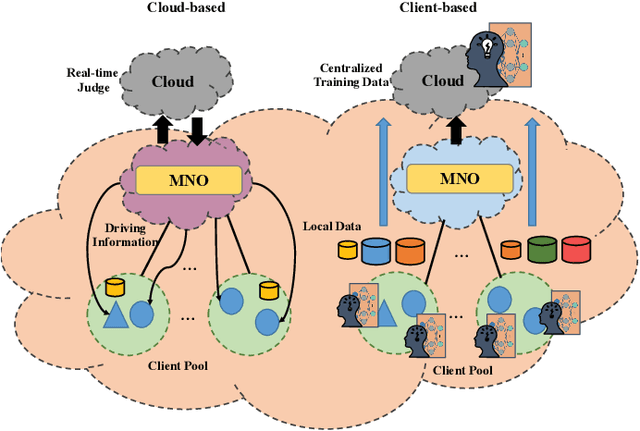
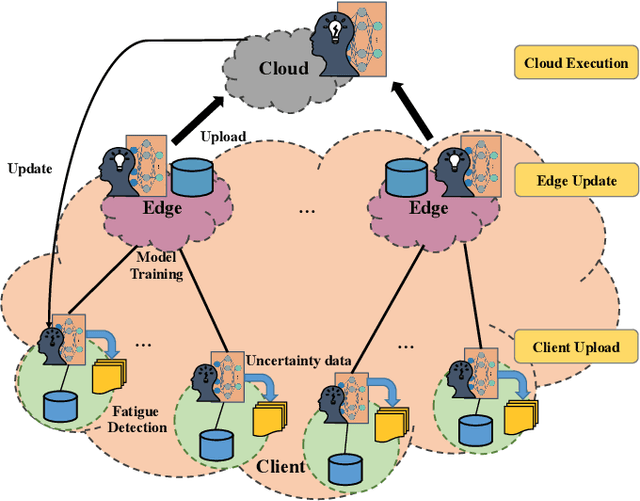
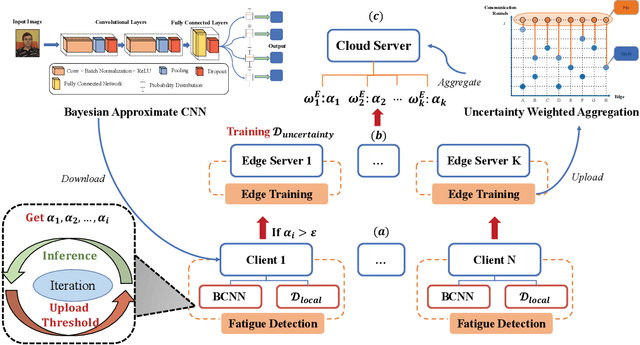
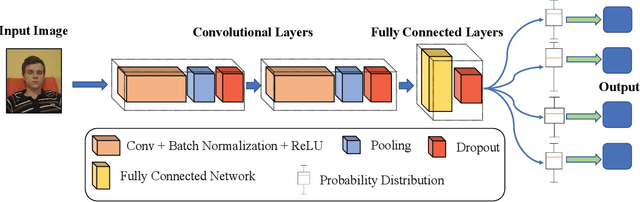
With the proliferation of edge smart devices and the Internet of Vehicles (IoV) technologies, intelligent fatigue detection has become one of the most-used methods in our daily driving. To improve the performance of the detection model, a series of techniques have been developed. However, existing work still leaves much to be desired, such as privacy disclosure and communication cost. To address these issues, we propose FedSup, a client-edge-cloud framework for privacy and efficient fatigue detection. Inspired by the federated learning technique, FedSup intelligently utilizes the collaboration between client, edge, and cloud server to realizing dynamic model optimization while protecting edge data privacy. Moreover, to reduce the unnecessary system communication overhead, we further propose a Bayesian convolutional neural network (BCNN) approximation strategy on the clients and an uncertainty weighted aggregation algorithm on the cloud to enhance the central model training efficiency. Extensive experiments demonstrate that the FedSup framework is suitable for IoV scenarios and outperforms other mainstream methods.