 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDE: Task-Isolated Diffusion for Unified Video Editing and Generation
Jun 06, 2026Recent advances in Diffusion Transformers have driven rapid progress in video generation and editing, yet these capabilities are still handled by separate, task-specific models. Building a unified framework that supports diverse video tasks remains an open challenge: existing unified attempts either require dedicated auxiliary encoders or lack explicit mechanisms to distinguish heterogeneous conditioning tokens, struggling when the number and type of visual conditions vary across tasks. We propose TIDE, a unified framework that integrates instruction-based editing, reference-guided editing, and multi-reference generation. At its core, we introduce per-token task embeddings that assign each input token a task-specific identifier, enabling the model to explicitly disambiguate target, source, and reference tokens. To simultaneously capture high-level semantic understanding and fine-grained structural fidelity, we design a dual-path conditioning scheme that couples a vision-language model with a VAE latent path for complementary signals. We further devise a multi-task progressive training strategy that incrementally introduces tasks of increasing complexity, effectively harmonizing diverse objectives and enabling smooth generalization across heterogeneous task distributions. Extensive experiments on multiple video editing and generation benchmarks demonstrate that TIDE achieves state-of-the-art performance across all evaluated tasks. Our project page is available at https://LittleWork123.github.io/tide.
A$_3$B$_2$: Adaptive Asymmetric Adapter for Alleviating Branch Bias in Vision-Language Image Classification with Few-Shot Learning
May 13, 2026Efficient transfer learning methods for large-scale vision-language models ($e.g.$, CLIP) enable strong few-shot transfer, yet existing adaptation methods follow a fixed fine-tuning paradigm that implicitly assumes a uniform importance of the image and text branches, which has not been systematically studied in image classification. Through extensive analysis, we reveal a Branch Bias issue in vision-language image classification: adapting the image encoder does not always improve performance under out-of-distribution settings. Motivated by this observation, we propose A$_3$B$_2$, an Adaptive Asymmetric Adapter that alleviates Branch Bias in few-shot learning. A$_3$B$_2$ introduces Uncertainty-Aware Adapter Dampening (UAAD), which automatically suppresses image-branch adaptation when prediction uncertainty is high, enabling soft and data-driven control without manual intervention. Architecturally, A$_3$B$_2$ adopts a lightweight asymmetric design inspired by mixture-of-experts with Load Balancing Regularization. Extensive experiments on three few-shot image classification tasks across 11 datasets demonstrate that A$_3$B$_2$ consistently outperforms 11 competitive prompt- and adapter-based baselines.
Enhancing Reinforcement Learning for Radiology Report Generation with Evidence-aware Rewards and Self-correcting Preference Learning
Apr 15, 2026Recent reinforcement learning (RL) approaches have advanced radiology report generation (RRG), yet two core limitations persist: (1) report-level rewards offer limited evidence-grounded guidance for clinical faithfulness; and (2) current methods lack an explicit self-improving mechanism to align with clinical preference. We introduce clinically aligned Evidence-aware Self-Correcting Reinforcement Learning (ESC-RL), comprising two key components. First, a Group-wise Evidence-aware Alignment Reward (GEAR) delivers group-wise, evidence-aware feedback. GEAR reinforces consistent grounding for true positives, recovers missed findings for false negatives, and suppresses unsupported content for false positives. Second, a Self-correcting Preference Learning (SPL) strategy automatically constructs a reliable, disease-aware preference dataset from multiple noisy observations and leverages an LLM to synthesize refined reports without human supervision. ESC-RL promotes clinically faithful, disease-aligned reward and supports continual self-improvement during training. Extensive experiments on two public chest X-ray datasets demonstrate consistent gains and state-of-the-art performance.
LLM-assisted Semantic Option Discovery for Facilitating Adaptive Deep Reinforcement Learning
Mar 02, 2026Despite achieving remarkable success in complex tasks, Deep Reinforcement Learning (DRL) is still suffering from critical issues in practical applications, such as low data efficiency, lack of interpretability, and limited cross-environment transferability. However, the learned policy generating actions based on states are sensitive to the environmental changes, struggling to guarantee behavioral safety and compliance. Recent research shows that integrating Large Language Models (LLMs) with symbolic planning is promising in addressing these challenges. Inspired by this, we introduce a novel LLM-driven closed-loop framework, which enables semantic-driven skill reuse and real-time constraint monitoring by mapping natural language instructions into executable rules and semantically annotating automatically created options. The proposed approach utilizes the general knowledge of LLMs to facilitate exploration efficiency and adapt to transferable options for similar environments, and provides inherent interpretability through semantic annotations. To validate the effectiveness of this framework, we conduct experiments on two domains, Office World and Montezuma's Revenge, respectively. The results demonstrate superior performance in data efficiency, constraint compliance, and cross-task transferability.
Learner-Tailored Program Repair: A Solution Generator with Iterative Edit-Driven Retrieval Enhancement
Jan 13, 2026With the development of large language models (LLMs) in the field of programming, intelligent programming coaching systems have gained widespread attention. However, most research focuses on repairing the buggy code of programming learners without providing the underlying causes of the bugs. To address this gap, we introduce a novel task, namely \textbf{LPR} (\textbf{L}earner-Tailored \textbf{P}rogram \textbf{R}epair). We then propose a novel and effective framework, \textbf{\textsc{\MethodName{}}} (\textbf{L}earner-Tailored \textbf{S}olution \textbf{G}enerator), to enhance program repair while offering the bug descriptions for the buggy code. In the first stage, we utilize a repair solution retrieval framework to construct a solution retrieval database and then employ an edit-driven code retrieval approach to retrieve valuable solutions, guiding LLMs in identifying and fixing the bugs in buggy code. In the second stage, we propose a solution-guided program repair method, which fixes the code and provides explanations under the guidance of retrieval solutions. Moreover, we propose an Iterative Retrieval Enhancement method that utilizes evaluation results of the generated code to iteratively optimize the retrieval direction and explore more suitable repair strategies, improving performance in practical programming coaching scenarios. The experimental results show that our approach outperforms a set of baselines by a large margin, validating the effectiveness of our framework for the newly proposed LPR task.
CoLA: Collaborative Low-Rank Adaptation
May 21, 2025The scaling law of Large Language Models (LLMs) reveals a power-law relationship, showing diminishing return on performance as model scale increases. While training LLMs from scratch is resource-intensive, fine-tuning a pre-trained model for specific tasks has become a practical alternative. Full fine-tuning (FFT) achieves strong performance; however, it is computationally expensive and inefficient. Parameter-efficient fine-tuning (PEFT) methods, like LoRA, have been proposed to address these challenges by freezing the pre-trained model and adding lightweight task-specific modules. LoRA, in particular, has proven effective, but its application to multi-task scenarios is limited by interference between tasks. Recent approaches, such as Mixture-of-Experts (MOE) and asymmetric LoRA, have aimed to mitigate these issues but still struggle with sample scarcity and noise interference due to their fixed structure. In response, we propose CoLA, a more flexible LoRA architecture with an efficient initialization scheme, and introduces three collaborative strategies to enhance performance by better utilizing the quantitative relationships between matrices $A$ and $B$. Our experiments demonstrate the effectiveness and robustness of CoLA, outperforming existing PEFT methods, especially in low-sample scenarios. Our data and code are fully publicly available at https://github.com/zyy-2001/CoLA.
Boosting MLLM Reasoning with Text-Debiased Hint-GRPO
Mar 31, 2025MLLM reasoning has drawn widespread research for its excellent problem-solving capability. Current reasoning methods fall into two types: PRM, which supervises the intermediate reasoning steps, and ORM, which supervises the final results. Recently, DeepSeek-R1 has challenged the traditional view that PRM outperforms ORM, which demonstrates strong generalization performance using an ORM method (i.e., GRPO). However, current MLLM's GRPO algorithms still struggle to handle challenging and complex multimodal reasoning tasks (e.g., mathematical reasoning). In this work, we reveal two problems that impede the performance of GRPO on the MLLM: Low data utilization and Text-bias. Low data utilization refers to that GRPO cannot acquire positive rewards to update the MLLM on difficult samples, and text-bias is a phenomenon that the MLLM bypasses image condition and solely relies on text condition for generation after GRPO training. To tackle these problems, this work proposes Hint-GRPO that improves data utilization by adaptively providing hints for samples of varying difficulty, and text-bias calibration that mitigates text-bias by calibrating the token prediction logits with image condition in test-time. Experiment results on three base MLLMs across eleven datasets demonstrate that our proposed methods advance the reasoning capability of original MLLM by a large margin, exhibiting superior performance to existing MLLM reasoning methods. Our code is available at https://github.com/hqhQAQ/Hint-GRPO.
Less is More: Adaptive Program Repair with Bug Localization and Preference Learning
Mar 09, 2025Automated Program Repair (APR) is a task to automatically generate patches for the buggy code. However, most research focuses on generating correct patches while ignoring the consistency between the fixed code and the original buggy code. How to conduct adaptive bug fixing and generate patches with minimal modifications have seldom been investigated. To bridge this gap, we first introduce a novel task, namely AdaPR (Adaptive Program Repair). We then propose a two-stage approach AdaPatcher (Adaptive Patch Generator) to enhance program repair while maintaining the consistency. In the first stage, we utilize a Bug Locator with self-debug learning to accurately pinpoint bug locations. In the second stage, we train a Program Modifier to ensure consistency between the post-modified fixed code and the pre-modified buggy code. The Program Modifier is enhanced with a location-aware repair learning strategy to generate patches based on identified buggy lines, a hybrid training strategy for selective reference and an adaptive preference learning to prioritize fewer changes. The experimental results show that our approach outperforms a set of baselines by a large margin, validating the effectiveness of our two-stage framework for the newly proposed AdaPR task.
CoDe: Communication Delay-Tolerant Multi-Agent Collaboration via Dual Alignment of Intent and Timeliness
Jan 09, 2025



Communication has been widely employed to enhance multi-agent collaboration. Previous research has typically assumed delay-free communication, a strong assumption that is challenging to meet in practice. However, real-world agents suffer from channel delays, receiving messages sent at different time points, termed {\it{Asynchronous Communication}}, leading to cognitive biases and breakdowns in collaboration. This paper first defines two communication delay settings in MARL and emphasizes their harm to collaboration. To handle the above delays, this paper proposes a novel framework, Communication Delay-tolerant Multi-Agent Collaboration (CoDe). At first, CoDe learns an intent representation as messages through future action inference, reflecting the stable future behavioral trends of the agents. Then, CoDe devises a dual alignment mechanism of intent and timeliness to strengthen the fusion process of asynchronous messages. In this way, agents can extract the long-term intent of others, even from delayed messages, and selectively utilize the most recent messages that are relevant to their intent. Experimental results demonstrate that CoDe outperforms baseline algorithms in three MARL benchmarks without delay and exhibits robustness under fixed and time-varying delays.
MPCODER: Multi-user Personalized Code Generator with Explicit and Implicit Style Representation Learning
Jun 25, 2024


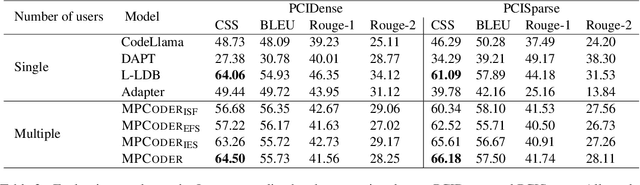
Large Language Models (LLMs) have demonstrated great potential for assisting developers in their daily development. However, most research focuses on generating correct code, how to use LLMs to generate personalized code has seldom been investigated. To bridge this gap, we proposed MPCoder (Multi-user Personalized Code Generator) to generate personalized code for multiple users. To better learn coding style features, we utilize explicit coding style residual learning to capture the syntax code style standards and implicit style learning to capture the semantic code style conventions. We train a multi-user style adapter to better differentiate the implicit feature representations of different users through contrastive learning, ultimately enabling personalized code generation for multiple users. We further propose a novel evaluation metric for estimating similarities between codes of different coding styles. The experimental results show the effectiveness of our approach for this novel task.