 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASTLE: A Comprehensive Benchmark for Evaluating Student-Tailored Personalized Safety in Large Language Models
Feb 05, 2026Large language models (LLMs) have advanced the development of personalized learning in education. However, their inherent generation mechanisms often produce homogeneous responses to identical prompts. This one-size-fits-all mechanism overlooks the substantial heterogeneity in students cognitive and psychological, thereby posing potential safety risks to vulnerable groups. Existing safety evaluations primarily rely on context-independent metrics such as factual accuracy, bias, or toxicity, which fail to capture the divergent harms that the same response might cause across different student attributes. To address this gap, we propose the concept of Student-Tailored Personalized Safety and construct CASTLE based on educational theories. This benchmark covers 15 educational safety risks and 14 student attributes, comprising 92,908 bilingual scenarios. We further design three evaluation metrics: Risk Sensitivity, measuring the model ability to detect risks; Emotional Empathy, evaluating the model capacity to recognize student states; and Student Alignment, assessing the match between model responses and student attributes. Experiments on 18 SOTA LLMs demonstrate that CASTLE poses a significant challenge: all models scored below an average safety rating of 2.3 out of 5, indicating substantial deficiencies in personalized safety assurance.
Learner-Tailored Program Repair: A Solution Generator with Iterative Edit-Driven Retrieval Enhancement
Jan 13, 2026With the development of large language models (LLMs) in the field of programming, intelligent programming coaching systems have gained widespread attention. However, most research focuses on repairing the buggy code of programming learners without providing the underlying causes of the bugs. To address this gap, we introduce a novel task, namely \textbf{LPR} (\textbf{L}earner-Tailored \textbf{P}rogram \textbf{R}epair). We then propose a novel and effective framework, \textbf{\textsc{\MethodName{}}} (\textbf{L}earner-Tailored \textbf{S}olution \textbf{G}enerator), to enhance program repair while offering the bug descriptions for the buggy code. In the first stage, we utilize a repair solution retrieval framework to construct a solution retrieval database and then employ an edit-driven code retrieval approach to retrieve valuable solutions, guiding LLMs in identifying and fixing the bugs in buggy code. In the second stage, we propose a solution-guided program repair method, which fixes the code and provides explanations under the guidance of retrieval solutions. Moreover, we propose an Iterative Retrieval Enhancement method that utilizes evaluation results of the generated code to iteratively optimize the retrieval direction and explore more suitable repair strategies, improving performance in practical programming coaching scenarios. The experimental results show that our approach outperforms a set of baselines by a large margin, validating the effectiveness of our framework for the newly proposed LPR task.
Collaborative Representation Learning for Alignment of Tactile, Language, and Vision Modalities
Nov 14, 2025Tactile sensing offers rich and complementary information to vision and language, enabling robots to perceive fine-grained object properties. However, existing tactile sensors lack standardization, leading to redundant features that hinder cross-sensor generalization. Moreover, existing methods fail to fully integrate the intermediate communication among tactile, language, and vision modalities. To address this, we propose TLV-CoRe, a CLIP-based Tactile-Language-Vision Collaborative Representation learning method. TLV-CoRe introduces a Sensor-Aware Modulator to unify tactile features across different sensors and employs tactile-irrelevant decoupled learning to disentangle irrelevant tactile features. Additionally, a Unified Bridging Adapter is introduced to enhance tri-modal interaction within the shared representation space. To fairly evaluate the effectiveness of tactile models, we further propose the RSS evaluation framework, focusing on Robustness, Synergy, and Stability across different methods. Experimental results demonstrate that TLV-CoRe significantly improves sensor-agnostic representation learning and cross-modal alignment, offering a new direction for multimodal tactile representation.
From Noisy to Native: LLM-driven Graph Restoration for Test-Time Graph Domain Adaptation
Oct 09, 2025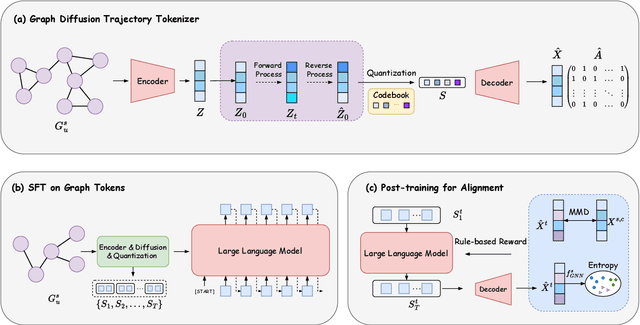
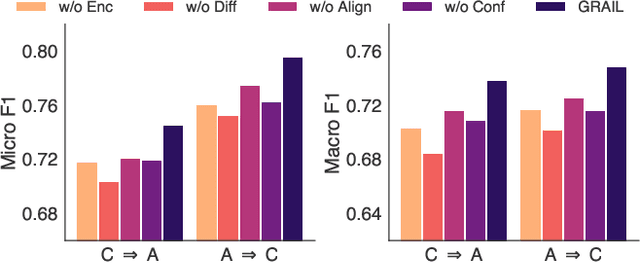
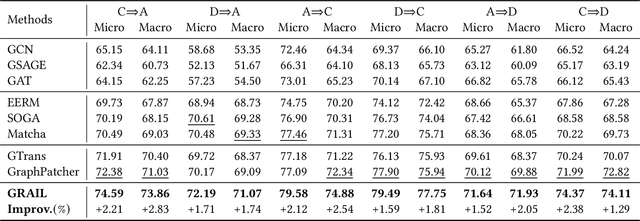
Graph domain adaptation (GDA) has achieved great attention due to its effectiveness in addressing the domain shift between train and test data. A significant bottleneck in existing graph domain adaptation methods is their reliance on source-domain data, which is often unavailable due to privacy or security concerns. This limitation has driven the development of Test-Time Graph Domain Adaptation (TT-GDA), which aims to transfer knowledge without accessing the source examples. Inspired by the generative power of large language models (LLMs), we introduce a novel framework that reframes TT-GDA as a generative graph restoration problem, "restoring the target graph to its pristine, source-domain-like state". There are two key challenges: (1) We need to construct a reasonable graph restoration process and design an effective encoding scheme that an LLM can understand, bridging the modality gap. (2) We need to devise a mechanism to ensure the restored graph acquires the intrinsic features of the source domain, even without access to the source data. To ensure the effectiveness of graph restoration, we propose GRAIL, that restores the target graph into a state that is well-aligned with the source domain. Specifically, we first compress the node representations into compact latent features and then use a graph diffusion process to model the graph restoration process. Then a quantization module encodes the restored features into discrete tokens. Building on this, an LLM is fine-tuned as a generative restorer to transform a "noisy" target graph into a "native" one. To further improve restoration quality, we introduce a reinforcement learning process guided by specialized alignment and confidence rewards. Extensive experiments demonstrate the effectiveness of our approach across various datasets.
Cuff-KT: Tackling Learners' Real-time Learning Pattern Adjustment via Tuning-Free Knowledge State Guided Model Updating
May 26, 2025



Knowledge Tracing (KT) is a core component of Intelligent Tutoring Systems, modeling learners' knowledge state to predict future performance and provide personalized learning support. Traditional KT models assume that learners' learning abilities remain relatively stable over short periods or change in predictable ways based on prior performance. However, in reality, learners' abilities change irregularly due to factors like cognitive fatigue, motivation, and external stress -- a task introduced, which we refer to as Real-time Learning Pattern Adjustment (RLPA). Existing KT models, when faced with RLPA, lack sufficient adaptability, because they fail to timely account for the dynamic nature of different learners' evolving learning patterns. Current strategies for enhancing adaptability rely on retraining, which leads to significant overfitting and high time overhead issues. To address this, we propose Cuff-KT, comprising a controller and a generator. The controller assigns value scores to learners, while the generator generates personalized parameters for selected learners. Cuff-KT controllably adapts to data changes fast and flexibly without fine-tuning. Experiments on five datasets from different subjects demonstrate that Cuff-KT significantly improves the performance of five KT models with different structures under intra- and inter-learner shifts, with an average relative increase in AUC of 10% and 4%, respectively, at a negligible time cost, effectively tackling RLPA task. Our code and datasets are fully available at https://github.com/zyy-2001/Cuff-KT.
Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents
May 26, 2025Large language models (LLMs) are revolutionizing education, with LLM-based agents playing a key role in simulating student behavior. A major challenge in student simulation is modeling the diverse learning patterns of students at various cognitive levels. However, current LLMs, typically trained as ``helpful assistants'', target at generating perfect responses. As a result, they struggle to simulate students with diverse cognitive abilities, as they often produce overly advanced answers, missing the natural imperfections that characterize student learning and resulting in unrealistic simulations. To address this issue, we propose a training-free framework for student simulation. We begin by constructing a cognitive prototype for each student using a knowledge graph, which captures their understanding of concepts from past learning records. This prototype is then mapped to new tasks to predict student performance. Next, we simulate student solutions based on these predictions and iteratively refine them using a beam search method to better replicate realistic mistakes. To validate our approach, we construct the \texttt{Student\_100} dataset, consisting of $100$ students working on Python programming and $5,000$ learning records. Experimental results show that our method consistently outperforms baseline models, achieving $100\%$ improvement in simulation accuracy.
CoLA: Collaborative Low-Rank Adaptation
May 21, 2025The scaling law of Large Language Models (LLMs) reveals a power-law relationship, showing diminishing return on performance as model scale increases. While training LLMs from scratch is resource-intensive, fine-tuning a pre-trained model for specific tasks has become a practical alternative. Full fine-tuning (FFT) achieves strong performance; however, it is computationally expensive and inefficient. Parameter-efficient fine-tuning (PEFT) methods, like LoRA, have been proposed to address these challenges by freezing the pre-trained model and adding lightweight task-specific modules. LoRA, in particular, has proven effective, but its application to multi-task scenarios is limited by interference between tasks. Recent approaches, such as Mixture-of-Experts (MOE) and asymmetric LoRA, have aimed to mitigate these issues but still struggle with sample scarcity and noise interference due to their fixed structure. In response, we propose CoLA, a more flexible LoRA architecture with an efficient initialization scheme, and introduces three collaborative strategies to enhance performance by better utilizing the quantitative relationships between matrices $A$ and $B$. Our experiments demonstrate the effectiveness and robustness of CoLA, outperforming existing PEFT methods, especially in low-sample scenarios. Our data and code are fully publicly available at https://github.com/zyy-2001/CoLA.
ScaleTrack: Scaling and back-tracking Automated GUI Agents
May 01, 2025Automated GUI agents aims to facilitate user interaction by automatically performing complex tasks in digital environments, such as web, mobile, desktop devices. It receives textual task instruction and GUI description to generate executable actions (\emph{e.g.}, click) and operation boxes step by step. Training a GUI agent mainly involves grounding and planning stages, in which the GUI grounding focuses on finding the execution coordinates according to the task, while the planning stage aims to predict the next action based on historical actions. However, previous work suffers from the limitations of insufficient training data for GUI grounding, as well as the ignorance of backtracking historical behaviors for GUI planning. To handle the above challenges, we propose ScaleTrack, a training framework by scaling grounding and backtracking planning for automated GUI agents. We carefully collected GUI samples of different synthesis criterions from a wide range of sources, and unified them into the same template for training GUI grounding models. Moreover, we design a novel training strategy that predicts the next action from the current GUI image, while also backtracking the historical actions that led to the GUI image. In this way, ScaleTrack explains the correspondence between GUI images and actions, which effectively describes the evolution rules of the GUI environment. Extensive experimental results demonstrate the effectiveness of ScaleTrack. Data and code will be available at url.
Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning
Apr 22, 2025Despite recent progress in video generation, producing videos that adhere to physical laws remains a significant challenge. Traditional diffusion-based methods struggle to extrapolate to unseen physical conditions (eg, velocity) due to their reliance on data-driven approximations. To address this, we propose to integrate symbolic reasoning and reinforcement learning to enforce physical consistency in video generation. We first introduce the Diffusion Timestep Tokenizer (DDT), which learns discrete, recursive visual tokens by recovering visual attributes lost during the diffusion process. The recursive visual tokens enable symbolic reasoning by a large language model. Based on it, we propose the Phys-AR framework, which consists of two stages: The first stage uses supervised fine-tuning to transfer symbolic knowledge, while the second stage applies reinforcement learning to optimize the model's reasoning abilities through reward functions based on physical conditions. Our approach allows the model to dynamically adjust and improve the physical properties of generated videos, ensuring adherence to physical laws. Experimental results demonstrate that PhysAR can generate videos that are physically consistent.
Boosting MLLM Reasoning with Text-Debiased Hint-GRPO
Mar 31, 2025MLLM reasoning has drawn widespread research for its excellent problem-solving capability. Current reasoning methods fall into two types: PRM, which supervises the intermediate reasoning steps, and ORM, which supervises the final results. Recently, DeepSeek-R1 has challenged the traditional view that PRM outperforms ORM, which demonstrates strong generalization performance using an ORM method (i.e., GRPO). However, current MLLM's GRPO algorithms still struggle to handle challenging and complex multimodal reasoning tasks (e.g., mathematical reasoning). In this work, we reveal two problems that impede the performance of GRPO on the MLLM: Low data utilization and Text-bias. Low data utilization refers to that GRPO cannot acquire positive rewards to update the MLLM on difficult samples, and text-bias is a phenomenon that the MLLM bypasses image condition and solely relies on text condition for generation after GRPO training. To tackle these problems, this work proposes Hint-GRPO that improves data utilization by adaptively providing hints for samples of varying difficulty, and text-bias calibration that mitigates text-bias by calibrating the token prediction logits with image condition in test-time. Experiment results on three base MLLMs across eleven datasets demonstrate that our proposed methods advance the reasoning capability of original MLLM by a large margin, exhibiting superior performance to existing MLLM reasoning methods. Our code is available at https://github.com/hqhQAQ/Hint-GRPO.