 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCRVerse: Towards Holistic OCR in End-to-End Vision-Language Models
Jan 29, 2026The development of large vision language models drives the demand for managing, and applying massive amounts of multimodal data, making OCR technology, which extracts information from visual images, increasingly popular. However, existing OCR methods primarily focus on recognizing text elements from images or scanned documents (\textbf{Text-centric OCR}), neglecting the identification of visual elements from visually information-dense image sources (\textbf{Vision-centric OCR}), such as charts, web pages and science plots. In reality, these visually information-dense images are widespread on the internet and have significant real-world application value, such as data visualization and web page analysis. In this technical report, we propose \textbf{OCRVerse}, the first holistic OCR method in end-to-end manner that enables unified text-centric OCR and vision-centric OCR. To this end, we constructe comprehensive data engineering to cover a wide range of text-centric documents, such as newspapers, magazines and books, as well as vision-centric rendered composites, including charts, web pages and scientific plots. Moreover, we propose a two-stage SFT-RL multi-domain training method for OCRVerse. SFT directly mixes cross-domain data to train and establish initial domain knowledge, while RL focuses on designing personalized reward strategies for the characteristics of each domain. Specifically, since different domains require various output formats and expected outputs, we provide sufficient flexibility in the RL stage to customize flexible reward signals for each domain, thereby improving cross-domain fusion and avoiding data conflicts. Experimental results demonstrate the effectiveness of OCRVerse, achieving competitive results across text-centric and vision-centric data types, even comparable to large-scale open-source and closed-source models.
UItron: Foundational GUI Agent with Advanced Perception and Planning
Aug 29, 2025GUI agent aims to enable automated operations on Mobile/PC devices, which is an important task toward achieving artificial general intelligence. The rapid advancement of VLMs accelerates the development of GUI agents, owing to their powerful capabilities in visual understanding and task planning. However, building a GUI agent remains a challenging task due to the scarcity of operation trajectories, the availability of interactive infrastructure, and the limitation of initial capabilities in foundation models. In this work, we introduce UItron, an open-source foundational model for automatic GUI agents, featuring advanced GUI perception, grounding, and planning capabilities. UItron highlights the necessity of systemic data engineering and interactive infrastructure as foundational components for advancing GUI agent development. It not only systematically studies a series of data engineering strategies to enhance training effects, but also establishes an interactive environment connecting both Mobile and PC devices. In training, UItron adopts supervised finetuning over perception and planning tasks in various GUI scenarios, and then develop a curriculum reinforcement learning framework to enable complex reasoning and exploration for online environments. As a result, UItron achieves superior performance in benchmarks of GUI perception, grounding, and planning. In particular, UItron highlights the interaction proficiency with top-tier Chinese mobile APPs, as we identified a general lack of Chinese capabilities even in state-of-the-art solutions. To this end, we manually collect over one million steps of operation trajectories across the top 100 most popular apps, and build the offline and online agent evaluation environments. Experimental results demonstrate that UItron achieves significant progress in Chinese app scenarios, propelling GUI agents one step closer to real-world application.
ScaleTrack: Scaling and back-tracking Automated GUI Agents
May 01, 2025Automated GUI agents aims to facilitate user interaction by automatically performing complex tasks in digital environments, such as web, mobile, desktop devices. It receives textual task instruction and GUI description to generate executable actions (\emph{e.g.}, click) and operation boxes step by step. Training a GUI agent mainly involves grounding and planning stages, in which the GUI grounding focuses on finding the execution coordinates according to the task, while the planning stage aims to predict the next action based on historical actions. However, previous work suffers from the limitations of insufficient training data for GUI grounding, as well as the ignorance of backtracking historical behaviors for GUI planning. To handle the above challenges, we propose ScaleTrack, a training framework by scaling grounding and backtracking planning for automated GUI agents. We carefully collected GUI samples of different synthesis criterions from a wide range of sources, and unified them into the same template for training GUI grounding models. Moreover, we design a novel training strategy that predicts the next action from the current GUI image, while also backtracking the historical actions that led to the GUI image. In this way, ScaleTrack explains the correspondence between GUI images and actions, which effectively describes the evolution rules of the GUI environment. Extensive experimental results demonstrate the effectiveness of ScaleTrack. Data and code will be available at url.
Revisiting Applicable and Comprehensive Knowledge Tracing in Large-Scale Data
Jan 24, 2025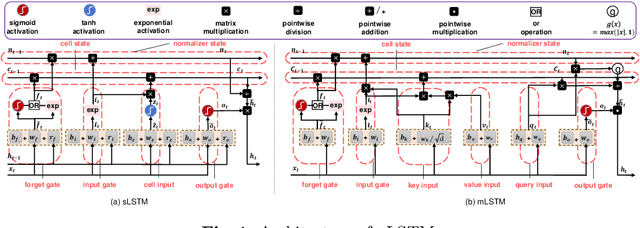

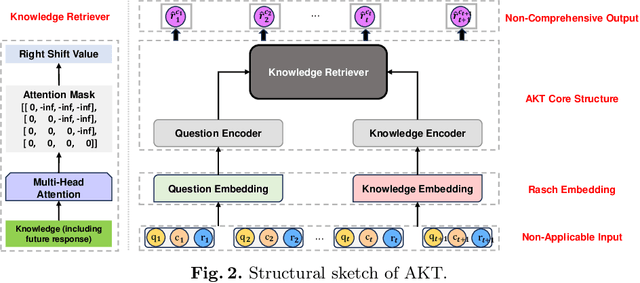
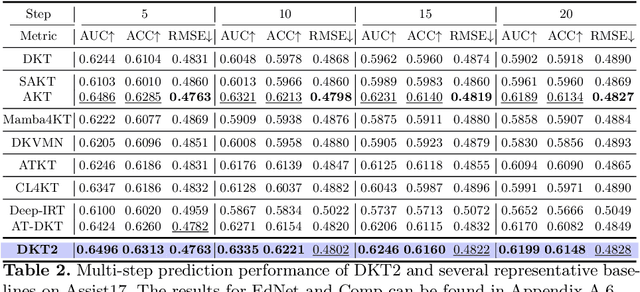
Knowledge Tracing (KT) is a fundamental component of Intelligent Tutoring Systems (ITS), enabling the modeling of students' knowledge states to predict future performance. The introduction of Deep Knowledge Tracing (DKT), the first deep learning-based KT (DLKT) model, has brought significant advantages in terms of applicability and comprehensiveness. However, recent DLKT models, such as Attentive Knowledge Tracing (AKT), have often prioritized predictive performance at the expense of these benefits. While deep sequential models like DKT have shown potential, they face challenges related to parallel computing, storage decision modification, and limited storage capacity. To address these limitations, we propose DKT2, a novel KT model that leverages the recently developed xLSTM architecture. DKT2 enhances input representation using the Rasch model and incorporates Item Response Theory (IRT) for interpretability, allowing for the decomposition of learned knowledge into familiar and unfamiliar knowledge. By integrating this knowledge with predicted questions, DKT2 generates comprehensive knowledge states. Extensive experiments conducted across three large-scale datasets demonstrate that DKT2 consistently outperforms 17 baseline models in various prediction tasks, underscoring its potential for real-world educational applications. This work bridges the gap between theoretical advancements and practical implementation in KT.Our code and datasets will be available at https://github.com/codebase-2025/DKT2.