 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCRVerse: Towards Holistic OCR in End-to-End Vision-Language Models
Jan 29, 2026The development of large vision language models drives the demand for managing, and applying massive amounts of multimodal data, making OCR technology, which extracts information from visual images, increasingly popular. However, existing OCR methods primarily focus on recognizing text elements from images or scanned documents (\textbf{Text-centric OCR}), neglecting the identification of visual elements from visually information-dense image sources (\textbf{Vision-centric OCR}), such as charts, web pages and science plots. In reality, these visually information-dense images are widespread on the internet and have significant real-world application value, such as data visualization and web page analysis. In this technical report, we propose \textbf{OCRVerse}, the first holistic OCR method in end-to-end manner that enables unified text-centric OCR and vision-centric OCR. To this end, we constructe comprehensive data engineering to cover a wide range of text-centric documents, such as newspapers, magazines and books, as well as vision-centric rendered composites, including charts, web pages and scientific plots. Moreover, we propose a two-stage SFT-RL multi-domain training method for OCRVerse. SFT directly mixes cross-domain data to train and establish initial domain knowledge, while RL focuses on designing personalized reward strategies for the characteristics of each domain. Specifically, since different domains require various output formats and expected outputs, we provide sufficient flexibility in the RL stage to customize flexible reward signals for each domain, thereby improving cross-domain fusion and avoiding data conflicts. Experimental results demonstrate the effectiveness of OCRVerse, achieving competitive results across text-centric and vision-centric data types, even comparable to large-scale open-source and closed-source models.
MobileDreamer: Generative Sketch World Model for GUI Agent
Jan 07, 2026Mobile GUI agents have shown strong potential in real-world automation and practical applications. However, most existing agents remain reactive, making decisions mainly from current screen, which limits their performance on long-horizon tasks. Building a world model from repeated interactions enables forecasting action outcomes and supports better decision making for mobile GUI agents. This is challenging because the model must predict post-action states with spatial awareness while remaining efficient enough for practical deployment. In this paper, we propose MobileDreamer, an efficient world-model-based lookahead framework to equip the GUI agents based on the future imagination provided by the world model. It consists of textual sketch world model and rollout imagination for GUI agent. Textual sketch world model forecasts post-action states through a learning process to transform digital images into key task-related sketches, and designs a novel order-invariant learning strategy to preserve the spatial information of GUI elements. The rollout imagination strategy for GUI agent optimizes the action-selection process by leveraging the prediction capability of world model. Experiments on Android World show that MobileDreamer achieves state-of-the-art performance and improves task success by 5.25%. World model evaluations further verify that our textual sketch modeling accurately forecasts key GUI elements.
UItron: Foundational GUI Agent with Advanced Perception and Planning
Aug 29, 2025GUI agent aims to enable automated operations on Mobile/PC devices, which is an important task toward achieving artificial general intelligence. The rapid advancement of VLMs accelerates the development of GUI agents, owing to their powerful capabilities in visual understanding and task planning. However, building a GUI agent remains a challenging task due to the scarcity of operation trajectories, the availability of interactive infrastructure, and the limitation of initial capabilities in foundation models. In this work, we introduce UItron, an open-source foundational model for automatic GUI agents, featuring advanced GUI perception, grounding, and planning capabilities. UItron highlights the necessity of systemic data engineering and interactive infrastructure as foundational components for advancing GUI agent development. It not only systematically studies a series of data engineering strategies to enhance training effects, but also establishes an interactive environment connecting both Mobile and PC devices. In training, UItron adopts supervised finetuning over perception and planning tasks in various GUI scenarios, and then develop a curriculum reinforcement learning framework to enable complex reasoning and exploration for online environments. As a result, UItron achieves superior performance in benchmarks of GUI perception, grounding, and planning. In particular, UItron highlights the interaction proficiency with top-tier Chinese mobile APPs, as we identified a general lack of Chinese capabilities even in state-of-the-art solutions. To this end, we manually collect over one million steps of operation trajectories across the top 100 most popular apps, and build the offline and online agent evaluation environments. Experimental results demonstrate that UItron achieves significant progress in Chinese app scenarios, propelling GUI agents one step closer to real-world application.
DocTron-Formula: Generalized Formula Recognition in Complex and Structured Scenarios
Aug 01, 2025

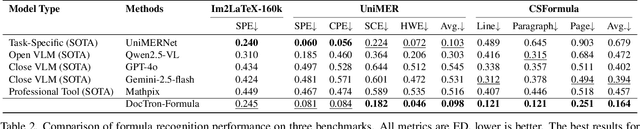
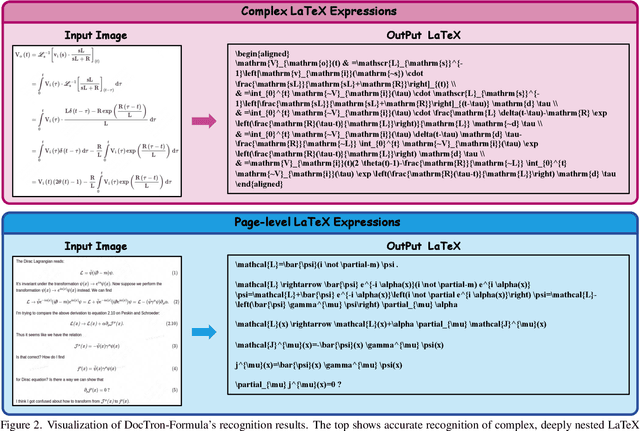
Optical Character Recognition (OCR) for mathematical formula is essential for the intelligent analysis of scientific literature. However, both task-specific and general vision-language models often struggle to handle the structural diversity, complexity, and real-world variability inherent in mathematical content. In this work, we present DocTron-Formula, a unified framework built upon general vision-language models, thereby eliminating the need for specialized architectures. Furthermore, we introduce CSFormula, a large-scale and challenging dataset that encompasses multidisciplinary and structurally complex formulas at the line, paragraph, and page levels. Through straightforward supervised fine-tuning, our approach achieves state-of-the-art performance across a variety of styles, scientific domains, and complex layouts. Experimental results demonstrate that our method not only surpasses specialized models in terms of accuracy and robustness, but also establishes a new paradigm for the automated understanding of complex scientific documents.
ScaleTrack: Scaling and back-tracking Automated GUI Agents
May 01, 2025Automated GUI agents aims to facilitate user interaction by automatically performing complex tasks in digital environments, such as web, mobile, desktop devices. It receives textual task instruction and GUI description to generate executable actions (\emph{e.g.}, click) and operation boxes step by step. Training a GUI agent mainly involves grounding and planning stages, in which the GUI grounding focuses on finding the execution coordinates according to the task, while the planning stage aims to predict the next action based on historical actions. However, previous work suffers from the limitations of insufficient training data for GUI grounding, as well as the ignorance of backtracking historical behaviors for GUI planning. To handle the above challenges, we propose ScaleTrack, a training framework by scaling grounding and backtracking planning for automated GUI agents. We carefully collected GUI samples of different synthesis criterions from a wide range of sources, and unified them into the same template for training GUI grounding models. Moreover, we design a novel training strategy that predicts the next action from the current GUI image, while also backtracking the historical actions that led to the GUI image. In this way, ScaleTrack explains the correspondence between GUI images and actions, which effectively describes the evolution rules of the GUI environment. Extensive experimental results demonstrate the effectiveness of ScaleTrack. Data and code will be available at url.
DataPlatter: Boosting Robotic Manipulation Generalization with Minimal Costly Data
Mar 25, 2025The growing adoption of Vision-Language-Action (VLA) models in embodied AI intensifies the demand for diverse manipulation demonstrations. However, high costs associated with data collection often result in insufficient data coverage across all scenarios, which limits the performance of the models. It is observed that the spatial reasoning phase (SRP) in large workspace dominates the failure cases. Fortunately, this data can be collected with low cost, underscoring the potential of leveraging inexpensive data to improve model performance. In this paper, we introduce the DataPlatter method, a framework that decouples training trajectories into distinct task stages and leverages abundant easily collectible SRP data to enhance VLA model's generalization. Through analysis we demonstrate that sub-task-specific training with additional SRP data with proper proportion can act as a performance catalyst for robot manipulation, maximizing the utilization of costly physical interaction phase (PIP) data. Experiments show that through introducing large proportion of cost-effective SRP trajectories into a limited set of PIP data, we can achieve a maximum improvement of 41\% on success rate in zero-shot scenes, while with the ability to transfer manipulation skill to novel targets.
RoboMM: All-in-One Multimodal Large Model for Robotic Manipulation
Dec 10, 2024



In recent years, robotics has advanced significantly through the integration of larger models and large-scale datasets. However, challenges remain in applying these models to 3D spatial interactions and managing data collection costs. To address these issues, we propose the multimodal robotic manipulation model, RoboMM, along with the comprehensive dataset, RoboData. RoboMM enhances 3D perception through camera parameters and occupancy supervision. Building on OpenFlamingo, it incorporates Modality-Isolation-Mask and multimodal decoder blocks, improving modality fusion and fine-grained perception. RoboData offers the complete evaluation system by integrating several well-known datasets, achieving the first fusion of multi-view images, camera parameters, depth maps, and actions, and the space alignment facilitates comprehensive learning from diverse robotic datasets. Equipped with RoboData and the unified physical space, RoboMM is the generalist policy that enables simultaneous evaluation across all tasks within multiple datasets, rather than focusing on limited selection of data or tasks. Its design significantly enhances robotic manipulation performance, increasing the average sequence length on the CALVIN from 1.7 to 3.3 and ensuring cross-embodiment capabilities, achieving state-of-the-art results across multiple datasets.
Contextual Modeling for 3D Dense Captioning on Point Clouds
Oct 08, 2022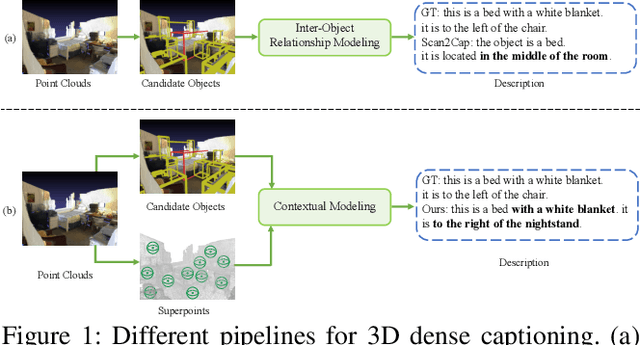
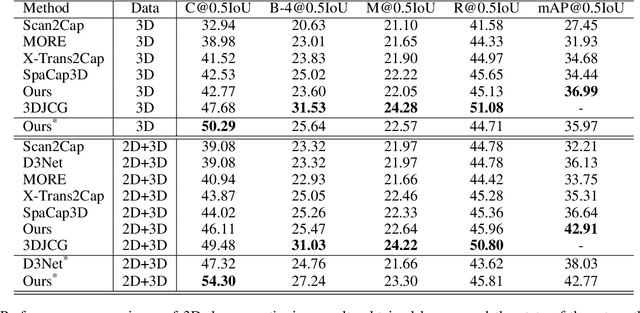
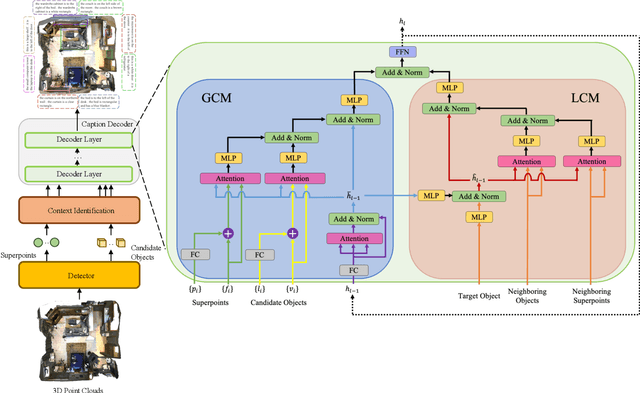
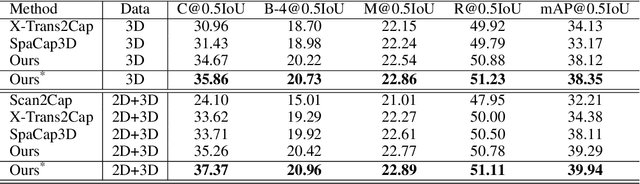
3D dense captioning, as an emerging vision-language task, aims to identify and locate each object from a set of point clouds and generate a distinctive natural language sentence for describing each located object. However, the existing methods mainly focus on mining inter-object relationship, while ignoring contextual information, especially the non-object details and background environment within the point clouds, thus leading to low-quality descriptions, such as inaccurate relative position information. In this paper, we make the first attempt to utilize the point clouds clustering features as the contextual information to supply the non-object details and background environment of the point clouds and incorporate them into the 3D dense captioning task. We propose two separate modules, namely the Global Context Modeling (GCM) and Local Context Modeling (LCM), in a coarse-to-fine manner to perform the contextual modeling of the point clouds. Specifically, the GCM module captures the inter-object relationship among all objects with global contextual information to obtain more complete scene information of the whole point clouds. The LCM module exploits the influence of the neighboring objects of the target object and local contextual information to enrich the object representations. With such global and local contextual modeling strategies, our proposed model can effectively characterize the object representations and contextual information and thereby generate comprehensive and detailed descriptions of the located objects. Extensive experiments on the ScanRefer and Nr3D datasets demonstrate that our proposed method sets a new record on the 3D dense captioning task, and verify the effectiveness of our raised contextual modeling of point clouds.