 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Modeling for 3D Dense Captioning on Point Clouds
Paper and Code
Oct 08, 2022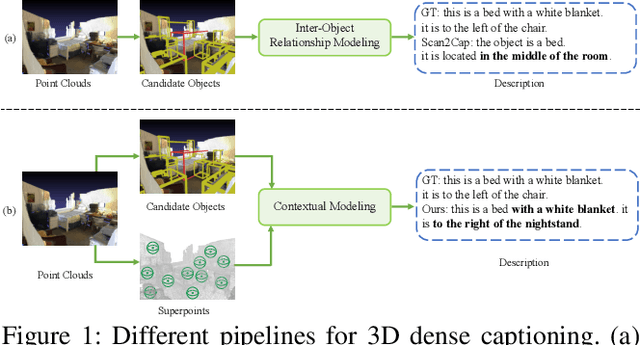
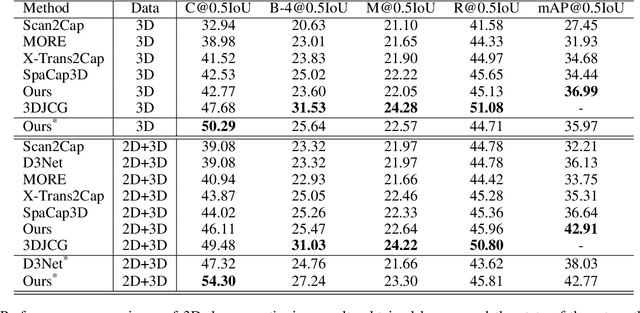
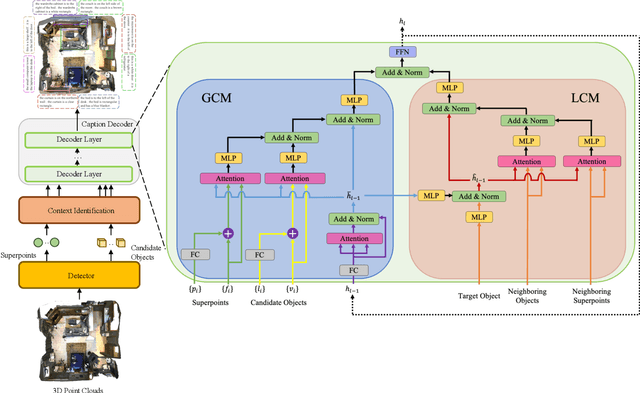
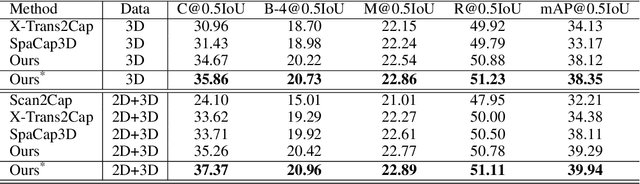
3D dense captioning, as an emerging vision-language task, aims to identify and locate each object from a set of point clouds and generate a distinctive natural language sentence for describing each located object. However, the existing methods mainly focus on mining inter-object relationship, while ignoring contextual information, especially the non-object details and background environment within the point clouds, thus leading to low-quality descriptions, such as inaccurate relative position information. In this paper, we make the first attempt to utilize the point clouds clustering features as the contextual information to supply the non-object details and background environment of the point clouds and incorporate them into the 3D dense captioning task. We propose two separate modules, namely the Global Context Modeling (GCM) and Local Context Modeling (LCM), in a coarse-to-fine manner to perform the contextual modeling of the point clouds. Specifically, the GCM module captures the inter-object relationship among all objects with global contextual information to obtain more complete scene information of the whole point clouds. The LCM module exploits the influence of the neighboring objects of the target object and local contextual information to enrich the object representations. With such global and local contextual modeling strategies, our proposed model can effectively characterize the object representations and contextual information and thereby generate comprehensive and detailed descriptions of the located objects. Extensive experiments on the ScanRefer and Nr3D datasets demonstrate that our proposed method sets a new record on the 3D dense captioning task, and verify the effectiveness of our raised contextual modeling of point clouds.