 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Fine-Tuning: Unlocking Hidden Capabilities in Vision-Language Models
Dec 28, 2025Explorations in fine-tuning Vision-Language Models (VLMs), such as Low-Rank Adaptation (LoRA) from Parameter Efficient Fine-Tuning (PEFT), have made impressive progress. However, most approaches rely on explicit weight updates, overlooking the extensive representational structures already encoded in pre-trained models that remain underutilized. Recent works have demonstrated that Mask Fine-Tuning (MFT) can be a powerful and efficient post-training paradigm for language models. Instead of updating weights, MFT assigns learnable gating scores to each weight, allowing the model to reorganize its internal subnetworks for downstream task adaptation. In this paper, we rethink fine-tuning for VLMs from a structural reparameterization perspective grounded in MFT. We apply MFT to the language and projector components of VLMs with different language backbones and compare against strong PEFT baselines. Experiments show that MFT consistently surpasses LoRA variants and even full fine-tuning, achieving high performance without altering the frozen backbone. Our findings reveal that effective adaptation can emerge not only from updating weights but also from reestablishing connections among the model's existing knowledge. Code available at: https://github.com/Ming-K9/MFT-VLM
ANNIE: Be Careful of Your Robots
Sep 03, 2025The integration of vision-language-action (VLA) models into embodied AI (EAI) robots is rapidly advancing their ability to perform complex, long-horizon tasks in humancentric environments. However, EAI systems introduce critical security risks: a compromised VLA model can directly translate adversarial perturbations on sensory input into unsafe physical actions. Traditional safety definitions and methodologies from the machine learning community are no longer sufficient. EAI systems raise new questions, such as what constitutes safety, how to measure it, and how to design effective attack and defense mechanisms in physically grounded, interactive settings. In this work, we present the first systematic study of adversarial safety attacks on embodied AI systems, grounded in ISO standards for human-robot interactions. We (1) formalize a principled taxonomy of safety violations (critical, dangerous, risky) based on physical constraints such as separation distance, velocity, and collision boundaries; (2) introduce ANNIEBench, a benchmark of nine safety-critical scenarios with 2,400 video-action sequences for evaluating embodied safety; and (3) ANNIE-Attack, a task-aware adversarial framework with an attack leader model that decomposes long-horizon goals into frame-level perturbations. Our evaluation across representative EAI models shows attack success rates exceeding 50% across all safety categories. We further demonstrate sparse and adaptive attack strategies and validate the real-world impact through physical robot experiments. These results expose a previously underexplored but highly consequential attack surface in embodied AI systems, highlighting the urgent need for security-driven defenses in the physical AI era. Code is available at https://github.com/RLCLab/Annie.
DataPlatter: Boosting Robotic Manipulation Generalization with Minimal Costly Data
Mar 25, 2025The growing adoption of Vision-Language-Action (VLA) models in embodied AI intensifies the demand for diverse manipulation demonstrations. However, high costs associated with data collection often result in insufficient data coverage across all scenarios, which limits the performance of the models. It is observed that the spatial reasoning phase (SRP) in large workspace dominates the failure cases. Fortunately, this data can be collected with low cost, underscoring the potential of leveraging inexpensive data to improve model performance. In this paper, we introduce the DataPlatter method, a framework that decouples training trajectories into distinct task stages and leverages abundant easily collectible SRP data to enhance VLA model's generalization. Through analysis we demonstrate that sub-task-specific training with additional SRP data with proper proportion can act as a performance catalyst for robot manipulation, maximizing the utilization of costly physical interaction phase (PIP) data. Experiments show that through introducing large proportion of cost-effective SRP trajectories into a limited set of PIP data, we can achieve a maximum improvement of 41\% on success rate in zero-shot scenes, while with the ability to transfer manipulation skill to novel targets.
RoboMM: All-in-One Multimodal Large Model for Robotic Manipulation
Dec 10, 2024



In recent years, robotics has advanced significantly through the integration of larger models and large-scale datasets. However, challenges remain in applying these models to 3D spatial interactions and managing data collection costs. To address these issues, we propose the multimodal robotic manipulation model, RoboMM, along with the comprehensive dataset, RoboData. RoboMM enhances 3D perception through camera parameters and occupancy supervision. Building on OpenFlamingo, it incorporates Modality-Isolation-Mask and multimodal decoder blocks, improving modality fusion and fine-grained perception. RoboData offers the complete evaluation system by integrating several well-known datasets, achieving the first fusion of multi-view images, camera parameters, depth maps, and actions, and the space alignment facilitates comprehensive learning from diverse robotic datasets. Equipped with RoboData and the unified physical space, RoboMM is the generalist policy that enables simultaneous evaluation across all tasks within multiple datasets, rather than focusing on limited selection of data or tasks. Its design significantly enhances robotic manipulation performance, increasing the average sequence length on the CALVIN from 1.7 to 3.3 and ensuring cross-embodiment capabilities, achieving state-of-the-art results across multiple datasets.
Corki: Enabling Real-time Embodied AI Robots via Algorithm-Architecture Co-Design
Jul 05, 2024



Embodied AI robots have the potential to fundamentally improve the way human beings live and manufacture. Continued progress in the burgeoning field of using large language models to control robots depends critically on an efficient computing substrate. In particular, today's computing systems for embodied AI robots are designed purely based on the interest of algorithm developers, where robot actions are divided into a discrete frame-basis. Such an execution pipeline creates high latency and energy consumption. This paper proposes Corki, an algorithm-architecture co-design framework for real-time embodied AI robot control. Our idea is to decouple LLM inference, robotic control and data communication in the embodied AI robots compute pipeline. Instead of predicting action for one single frame, Corki predicts the trajectory for the near future to reduce the frequency of LLM inference. The algorithm is coupled with a hardware that accelerates transforming trajectory into actual torque signals used to control robots and an execution pipeline that parallels data communication with computation. Corki largely reduces LLM inference frequency by up to 8.0x, resulting in up to 3.6x speed up. The success rate improvement can be up to 17.3%. Code is provided for re-implementation. https://github.com/hyy0613/Corki
RoboUniView: Visual-Language Model with Unified View Representation for Robotic Manipulaiton
Jun 27, 2024Utilizing Vision-Language Models (VLMs) for robotic manipulation represents a novel paradigm, aiming to enhance the model's ability to generalize to new objects and instructions. However, due to variations in camera specifications and mounting positions, existing methods exhibit significant performance disparities across different robotic platforms. To address this challenge, we propose RoboUniView in this paper, an innovative approach that decouples visual feature extraction from action learning. We first learn a unified view representation from multi-perspective views by pre-training on readily accessible data, and then derive actions from this unified view representation to control robotic manipulation. This unified view representation more accurately mirrors the physical world and is not constrained by the robotic platform's camera parameters. Thanks to this methodology, we achieve state-of-the-art performance on the demanding CALVIN benchmark, enhancing the success rate in the $D \to D$ setting from 88.7% to 96.2%, and in the $ABC \to D$ setting from 82.4% to 94.2%. Moreover, our model exhibits outstanding adaptability and flexibility: it maintains high performance under unseen camera parameters, can utilize multiple datasets with varying camera parameters, and is capable of joint cross-task learning across datasets. Code is provided for re-implementation. https://github.com/liufanfanlff/RoboUniview
Tight Bounds for Machine Unlearning via Differential Privacy
Sep 02, 2023We consider the formulation of "machine unlearning" of Sekhari, Acharya, Kamath, and Suresh (NeurIPS 2021), which formalizes the so-called "right to be forgotten" by requiring that a trained model, upon request, should be able to "unlearn" a number of points from the training data, as if they had never been included in the first place. Sekhari et al. established some positive and negative results about the number of data points that can be successfully unlearnt by a trained model without impacting the model's accuracy (the "deletion capacity"), showing that machine unlearning could be achieved by using differentially private (DP) algorithms. However, their results left open a gap between upper and lower bounds on the deletion capacity of these algorithms: our work fully closes this gap, obtaining tight bounds on the deletion capacity achievable by DP-based machine unlearning algorithms.
Invertible Mask Network for Face Privacy-Preserving
Apr 19, 2022
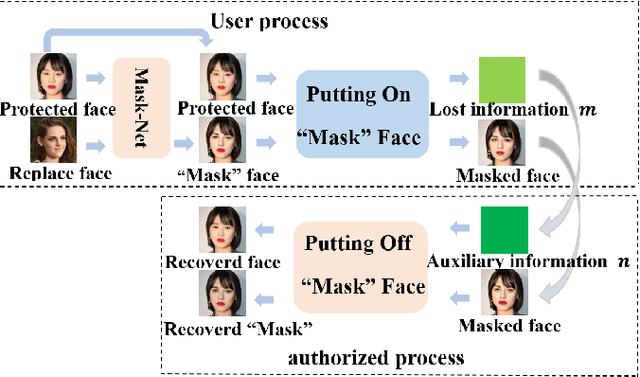
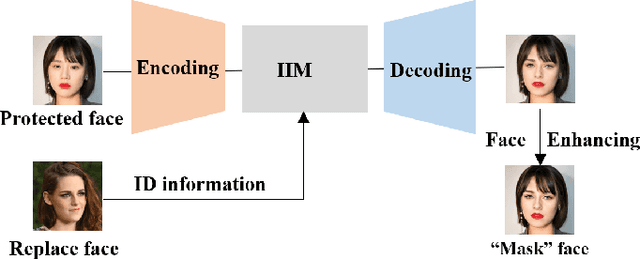
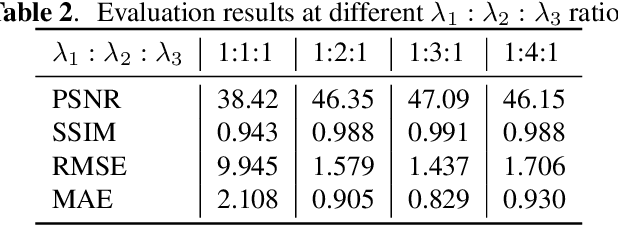
Face privacy-preserving is one of the hotspots that arises dramatic interests of research. However, the existing face privacy-preserving methods aim at causing the missing of semantic information of face and cannot preserve the reusability of original facial information. To achieve the naturalness of the processed face and the recoverability of the original protected face, this paper proposes face privacy-preserving method based on Invertible "Mask" Network (IMN). In IMN, we introduce a Mask-net to generate "Mask" face firstly. Then, put the "Mask" face onto the protected face and generate the masked face, in which the masked face is indistinguishable from "Mask" face. Finally, "Mask" face can be put off from the masked face and obtain the recovered face to the authorized users, in which the recovered face is visually indistinguishable from the protected face. The experimental results show that the proposed method can not only effectively protect the privacy of the protected face, but also almost perfectly recover the protected face from the masked face.