 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBareWave: Waveform-Native Flow-Matching Text-to-Speech
Jun 08, 2026Removing intermediate representations and separately trained decoding stages has become an important direction in generative modeling. In text-to-speech, however, high-quality systems are still commonly built through an intermediate acoustic representation before waveform synthesis. In this work, we present BareWave, a fully waveform-native framework for direct text-to-wave generation in flow-matching TTS. We consider this setting to raise three training challenges: raw-waveform modeling lacks a strong pretrained representational scaffold, different stages of training benefit from different noise schedules, and data-space perceptual objectives do not automatically share the temporal structure of the velocity-space flow objective. As a result, direct waveform training is hard to optimize efficiently, hard to push toward a strong final operating point with a fixed recipe, and hard to integrate effective perceptual refinement. Guided by this view, we develop a direct text-to-wave training framework that combines training-time representation alignment, staged noise scheduling, and velocity-aware perceptual alignment (VAPA), while preserving a single waveform-native inference path without pretrained components at test time. Experiments on zero-shot voice cloning show that strong intelligibility, speaker similarity, and naturalness can be achieved under a fully waveform-native inference path, supporting waveform-native flow-matching TTS as a practical direction. Project page with audio demos is available at https://barewave.github.io/.
Provably Secure Agent Guardrail
May 28, 2026As large language models transition from bounded generative engines to agents with expansive execution privileges, AI going out of control precipitates a fundamental crisis in artificial intelligence security. Existing defense architectures heavily rely on empirical semantic guardrails and probabilistic large model adjudicators, mechanisms that fail to provide deterministic security lower bounds when facing complex semantic symbol decoupling attacks. To overcome this empirical semantic guardrail dilemma, this paper proposes a new security paradigm for agents based on the fundamental limitations of logical reasoning. Based on this paradigm, we further introduce an executable Proof-Constrained Action (ePCA) framework with a neural symbolic isolation architecture. This framework abandons semantic trust in natural language, forcing agents to losslessly formalize their intentions into first-order logical mathematical constraints before performing physical operations. Empirical evaluations of macroscopic and microscopic two-dimensional dynamic adversarial systems demonstrate that our formal verification mechanism achieves zero attack success rate and zero false positive rate across the evaluated scenarios, with extremely low computational latency. This research provides a conditional formal foundation under explicit system assumptions and an engineering paradigm for constructing the underlying defense foundation for future intelligent systems.
SWIFT: Sliding Window Reconstruction for Few-Shot Training-Free Generated Video Attribution
Mar 09, 2026Recent advancements in video generation technologies have been significant, resulting in their widespread application across multiple domains. However, concerns have been mounting over the potential misuse of generated content. Tracing the origin of generated videos has become crucial to mitigate potential misuse and identify responsible parties. Existing video attribution methods require additional operations or the training of source attribution models, which may degrade video quality or necessitate large amounts of training samples. To address these challenges, we define for the first time the "few-shot training-free generated video attribution" task and propose SWIFT, which is tightly integrated with the temporal characteristics of the video. By leveraging the "Pixel Frames(many) to Latent Frame(one)" temporal mapping within each video chunk, SWIFT applies a fixed-length sliding window to perform two distinct reconstructions: normal and corrupted. The variation in the losses between two reconstructions is then used as an attribution signal. We conducted an extensive evaluation of five state-of-the-art (SOTA) video generation models. Experimental results show that SWIFT achieves over 90% average attribution accuracy with merely 20 video samples across all models and even enables zero-shot attribution for HunyuanVideo, EasyAnimate, and Wan2.2. Our source code is available at https://github.com/wangchao0708/SWIFT.
WMVLM: Evaluating Diffusion Model Image Watermarking via Vision-Language Models
Jan 29, 2026Digital watermarking is essential for securing generated images from diffusion models. Accurate watermark evaluation is critical for algorithm development, yet existing methods have significant limitations: they lack a unified framework for both residual and semantic watermarks, provide results without interpretability, neglect comprehensive security considerations, and often use inappropriate metrics for semantic watermarks. To address these gaps, we propose WMVLM, the first unified and interpretable evaluation framework for diffusion model image watermarking via vision-language models (VLMs). We redefine quality and security metrics for each watermark type: residual watermarks are evaluated by artifact strength and erasure resistance, while semantic watermarks are assessed through latent distribution shifts. Moreover, we introduce a three-stage training strategy to progressively enable the model to achieve classification, scoring, and interpretable text generation. Experiments show WMVLM outperforms state-of-the-art VLMs with strong generalization across datasets, diffusion models, and watermarking methods.
SemBind: Binding Diffusion Watermarks to Semantics Against Black-Box Forgery Attacks
Jan 28, 2026Latent-based watermarks, integrated into the generation process of latent diffusion models (LDMs), simplify detection and attribution of generated images. However, recent black-box forgery attacks, where an attacker needs at least one watermarked image and black-box access to the provider's model, can embed the provider's watermark into images not produced by the provider, posing outsized risk to provenance and trust. We propose SemBind, the first defense framework for latent-based watermarks that resists black-box forgery by binding latent signals to image semantics via a learned semantic masker. Trained with contrastive learning, the masker yields near-invariant codes for the same prompt and near-orthogonal codes across prompts; these codes are reshaped and permuted to modulate the target latent before any standard latent-based watermark. SemBind is generally compatible with existing latent-based watermarking schemes and keeps image quality essentially unchanged, while a simple mask-ratio parameter offers a tunable trade-off between anti-forgery strength and robustness. Across four mainstream latent-based watermark methods, our SemBind-enabled anti-forgery variants markedly reduce false acceptance under black-box forgery while providing a controllable robustness-security balance.
LiteUpdate: A Lightweight Framework for Updating AI-Generated Image Detectors
Nov 10, 2025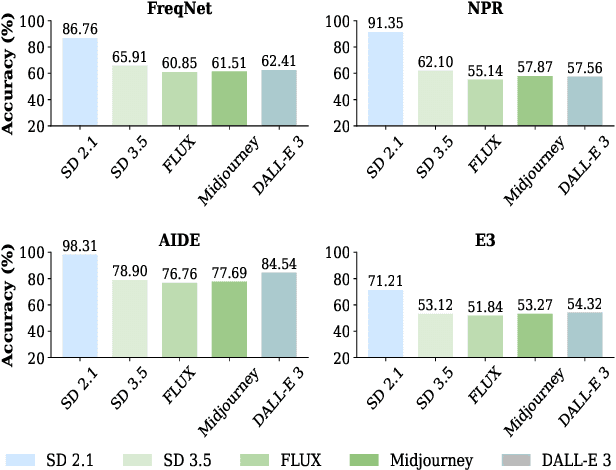
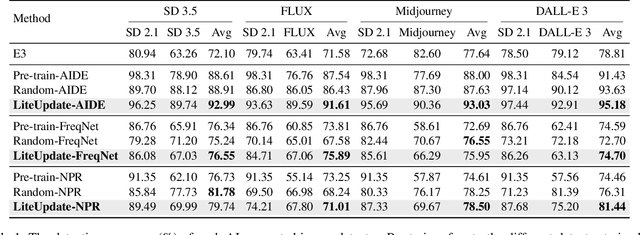
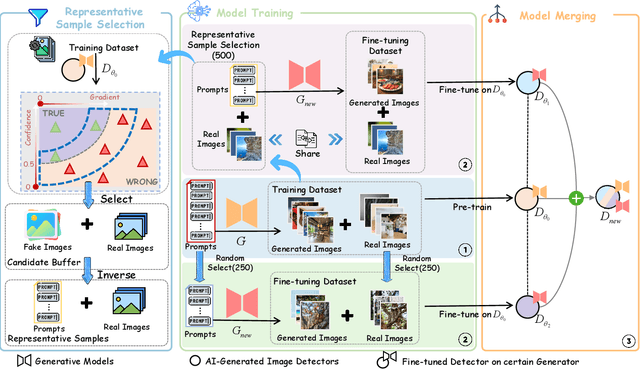
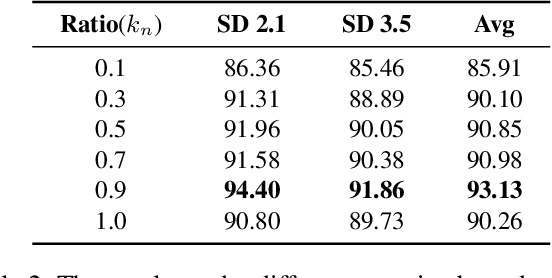
The rapid progress of generative AI has led to the emergence of new generative models, while existing detection methods struggle to keep pace, resulting in significant degradation in the detection performance. This highlights the urgent need for continuously updating AI-generated image detectors to adapt to new generators. To overcome low efficiency and catastrophic forgetting in detector updates, we propose LiteUpdate, a lightweight framework for updating AI-generated image detectors. LiteUpdate employs a representative sample selection module that leverages image confidence and gradient-based discriminative features to precisely select boundary samples. This approach improves learning and detection accuracy on new distributions with limited generated images, significantly enhancing detector update efficiency. Additionally, LiteUpdate incorporates a model merging module that fuses weights from multiple fine-tuning trajectories, including pre-trained, representative, and random updates. This balances the adaptability to new generators and mitigates the catastrophic forgetting of prior knowledge. Experiments demonstrate that LiteUpdate substantially boosts detection performance in various detectors. Specifically, on AIDE, the average detection accuracy on Midjourney improved from 87.63% to 93.03%, a 6.16% relative increase.
A high-capacity linguistic steganography based on entropy-driven rank-token mapping
Oct 27, 2025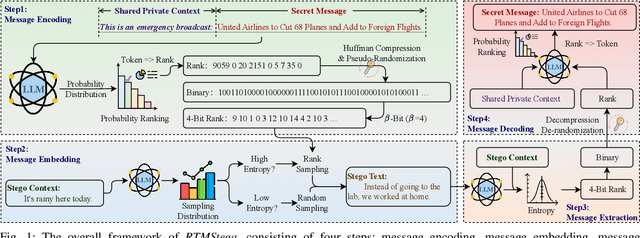
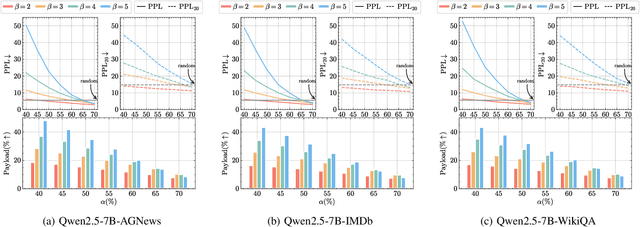
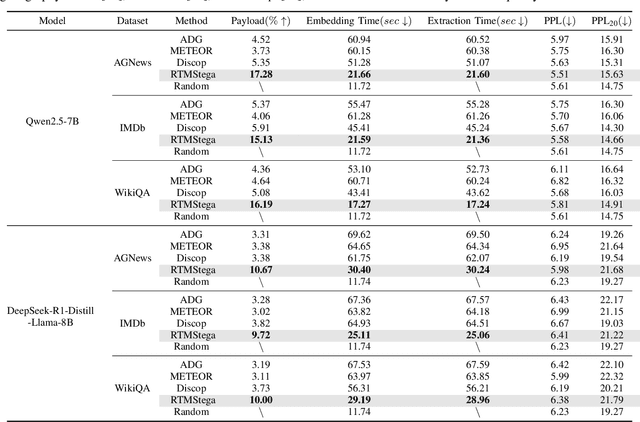

Linguistic steganography enables covert communication through embedding secret messages into innocuous texts; however, current methods face critical limitations in payload capacity and security. Traditional modification-based methods introduce detectable anomalies, while retrieval-based strategies suffer from low embedding capacity. Modern generative steganography leverages language models to generate natural stego text but struggles with limited entropy in token predictions, further constraining capacity. To address these issues, we propose an entropy-driven framework called RTMStega that integrates rank-based adaptive coding and context-aware decompression with normalized entropy. By mapping secret messages to token probability ranks and dynamically adjusting sampling via context-aware entropy-based adjustments, RTMStega achieves a balance between payload capacity and imperceptibility. Experiments across diverse datasets and models demonstrate that RTMStega triples the payload capacity of mainstream generative steganography, reduces processing time by over 50%, and maintains high text quality, offering a trustworthy solution for secure and efficient covert communication.
T2SMark: Balancing Robustness and Diversity in Noise-as-Watermark for Diffusion Models
Oct 25, 2025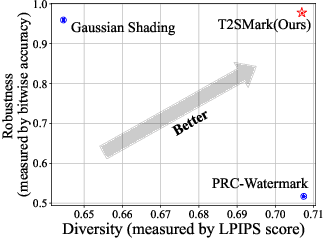
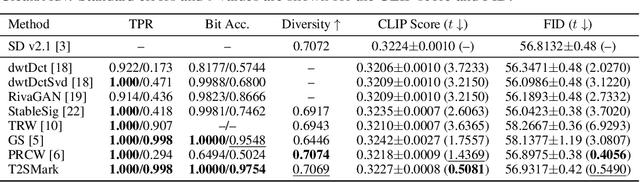
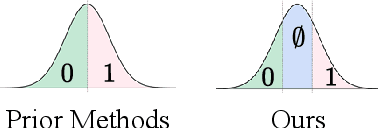
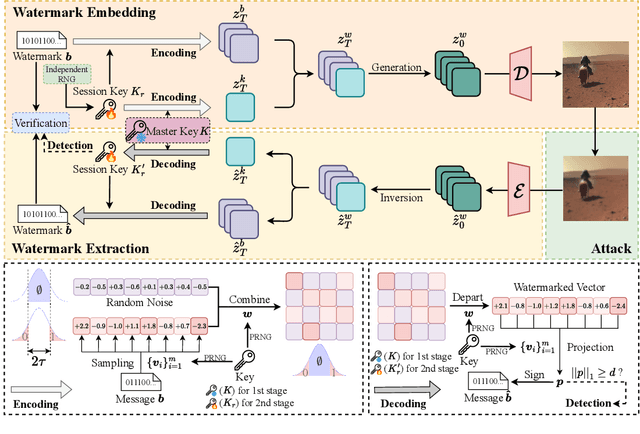
Diffusion models have advanced rapidly in recent years, producing high-fidelity images while raising concerns about intellectual property protection and the misuse of generative AI. Image watermarking for diffusion models, particularly Noise-as-Watermark (NaW) methods, encode watermark as specific standard Gaussian noise vector for image generation, embedding the infomation seamlessly while maintaining image quality. For detection, the generation process is inverted to recover the initial noise vector containing the watermark before extraction. However, existing NaW methods struggle to balance watermark robustness with generation diversity. Some methods achieve strong robustness by heavily constraining initial noise sampling, which degrades user experience, while others preserve diversity but prove too fragile for real-world deployment. To address this issue, we propose T2SMark, a two-stage watermarking scheme based on Tail-Truncated Sampling (TTS). Unlike prior methods that simply map bits to positive or negative values, TTS enhances robustness by embedding bits exclusively in the reliable tail regions while randomly sampling the central zone to preserve the latent distribution. Our two-stage framework then ensures sampling diversity by integrating a randomly generated session key into both encryption pipelines. We evaluate T2SMark on diffusion models with both U-Net and DiT backbones. Extensive experiments show that it achieves an optimal balance between robustness and diversity. Our code is available at \href{https://github.com/0xD009/T2SMark}{https://github.com/0xD009/T2SMark}.
De-AntiFake: Rethinking the Protective Perturbations Against Voice Cloning Attacks
Jul 03, 2025The rapid advancement of speech generation models has heightened privacy and security concerns related to voice cloning (VC). Recent studies have investigated disrupting unauthorized voice cloning by introducing adversarial perturbations. However, determined attackers can mitigate these protective perturbations and successfully execute VC. In this study, we conduct the first systematic evaluation of these protective perturbations against VC under realistic threat models that include perturbation purification. Our findings reveal that while existing purification methods can neutralize a considerable portion of the protective perturbations, they still lead to distortions in the feature space of VC models, which degrades the performance of VC. From this perspective, we propose a novel two-stage purification method: (1) Purify the perturbed speech; (2) Refine it using phoneme guidance to align it with the clean speech distribution. Experimental results demonstrate that our method outperforms state-of-the-art purification methods in disrupting VC defenses. Our study reveals the limitations of adversarial perturbation-based VC defenses and underscores the urgent need for more robust solutions to mitigate the security and privacy risks posed by VC. The code and audio samples are available at https://de-antifake.github.io.
Gaussian Shading++: Rethinking the Realistic Deployment Challenge of Performance-Lossless Image Watermark for Diffusion Models
Apr 21, 2025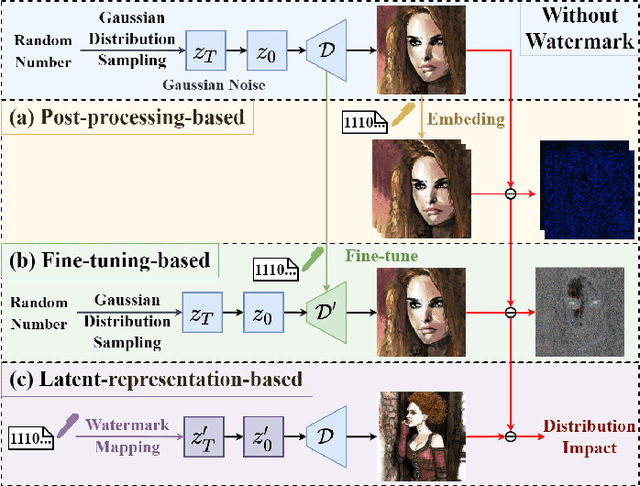


Ethical concerns surrounding copyright protection and inappropriate content generation pose challenges for the practical implementation of diffusion models. One effective solution involves watermarking the generated images. Existing methods primarily focus on ensuring that watermark embedding does not degrade the model performance. However, they often overlook critical challenges in real-world deployment scenarios, such as the complexity of watermark key management, user-defined generation parameters, and the difficulty of verification by arbitrary third parties. To address this issue, we propose Gaussian Shading++, a diffusion model watermarking method tailored for real-world deployment. We propose a double-channel design that leverages pseudorandom error-correcting codes to encode the random seed required for watermark pseudorandomization, achieving performance-lossless watermarking under a fixed watermark key and overcoming key management challenges. Additionally, we model the distortions introduced during generation and inversion as an additive white Gaussian noise channel and employ a novel soft decision decoding strategy during extraction, ensuring strong robustness even when generation parameters vary. To enable third-party verification, we incorporate public key signatures, which provide a certain level of resistance against forgery attacks even when model inversion capabilities are fully disclosed. Extensive experiments demonstrate that Gaussian Shading++ not only maintains performance losslessness but also outperforms existing methods in terms of robustness, making it a more practical solution for real-world deployment.