 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWMVLM: Evaluating Diffusion Model Image Watermarking via Vision-Language Models
Jan 29, 2026Digital watermarking is essential for securing generated images from diffusion models. Accurate watermark evaluation is critical for algorithm development, yet existing methods have significant limitations: they lack a unified framework for both residual and semantic watermarks, provide results without interpretability, neglect comprehensive security considerations, and often use inappropriate metrics for semantic watermarks. To address these gaps, we propose WMVLM, the first unified and interpretable evaluation framework for diffusion model image watermarking via vision-language models (VLMs). We redefine quality and security metrics for each watermark type: residual watermarks are evaluated by artifact strength and erasure resistance, while semantic watermarks are assessed through latent distribution shifts. Moreover, we introduce a three-stage training strategy to progressively enable the model to achieve classification, scoring, and interpretable text generation. Experiments show WMVLM outperforms state-of-the-art VLMs with strong generalization across datasets, diffusion models, and watermarking methods.
SemBind: Binding Diffusion Watermarks to Semantics Against Black-Box Forgery Attacks
Jan 28, 2026Latent-based watermarks, integrated into the generation process of latent diffusion models (LDMs), simplify detection and attribution of generated images. However, recent black-box forgery attacks, where an attacker needs at least one watermarked image and black-box access to the provider's model, can embed the provider's watermark into images not produced by the provider, posing outsized risk to provenance and trust. We propose SemBind, the first defense framework for latent-based watermarks that resists black-box forgery by binding latent signals to image semantics via a learned semantic masker. Trained with contrastive learning, the masker yields near-invariant codes for the same prompt and near-orthogonal codes across prompts; these codes are reshaped and permuted to modulate the target latent before any standard latent-based watermark. SemBind is generally compatible with existing latent-based watermarking schemes and keeps image quality essentially unchanged, while a simple mask-ratio parameter offers a tunable trade-off between anti-forgery strength and robustness. Across four mainstream latent-based watermark methods, our SemBind-enabled anti-forgery variants markedly reduce false acceptance under black-box forgery while providing a controllable robustness-security balance.
Gaussian Shading++: Rethinking the Realistic Deployment Challenge of Performance-Lossless Image Watermark for Diffusion Models
Apr 21, 2025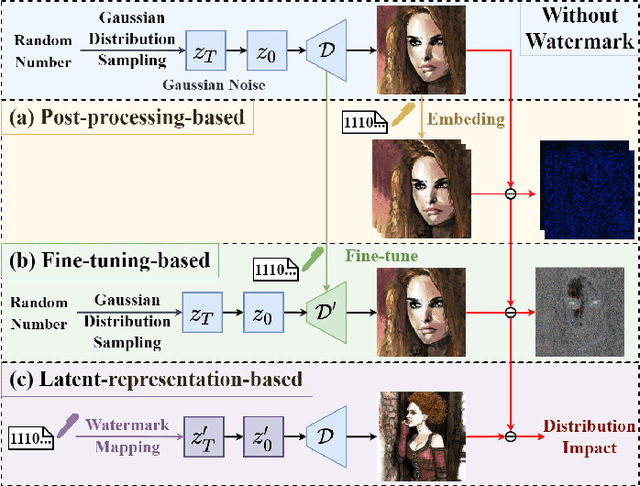


Ethical concerns surrounding copyright protection and inappropriate content generation pose challenges for the practical implementation of diffusion models. One effective solution involves watermarking the generated images. Existing methods primarily focus on ensuring that watermark embedding does not degrade the model performance. However, they often overlook critical challenges in real-world deployment scenarios, such as the complexity of watermark key management, user-defined generation parameters, and the difficulty of verification by arbitrary third parties. To address this issue, we propose Gaussian Shading++, a diffusion model watermarking method tailored for real-world deployment. We propose a double-channel design that leverages pseudorandom error-correcting codes to encode the random seed required for watermark pseudorandomization, achieving performance-lossless watermarking under a fixed watermark key and overcoming key management challenges. Additionally, we model the distortions introduced during generation and inversion as an additive white Gaussian noise channel and employ a novel soft decision decoding strategy during extraction, ensuring strong robustness even when generation parameters vary. To enable third-party verification, we incorporate public key signatures, which provide a certain level of resistance against forgery attacks even when model inversion capabilities are fully disclosed. Extensive experiments demonstrate that Gaussian Shading++ not only maintains performance losslessness but also outperforms existing methods in terms of robustness, making it a more practical solution for real-world deployment.
Provably Secure Robust Image Steganography via Cross-Modal Error Correction
Dec 15, 2024

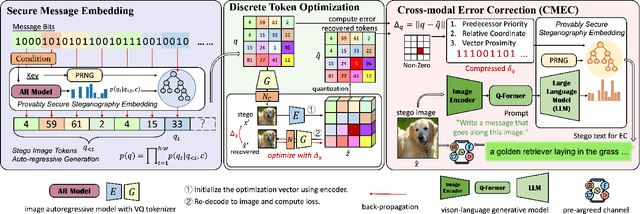
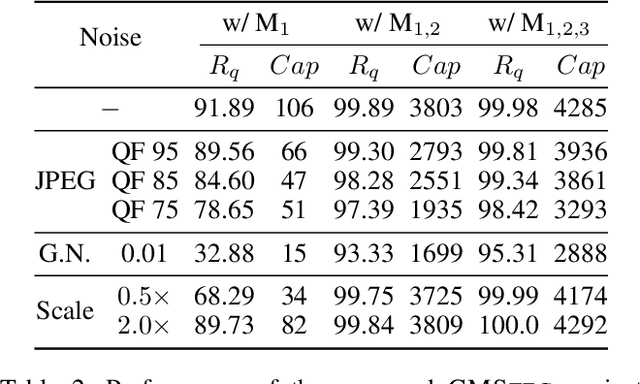
The rapid development of image generation models has facilitated the widespread dissemination of generated images on social networks, creating favorable conditions for provably secure image steganography. However, existing methods face issues such as low quality of generated images and lack of semantic control in the generation process. To leverage provably secure steganography with more effective and high-performance image generation models, and to ensure that stego images can accurately extract secret messages even after being uploaded to social networks and subjected to lossy processing such as JPEG compression, we propose a high-quality, provably secure, and robust image steganography method based on state-of-the-art autoregressive (AR) image generation models using Vector-Quantized (VQ) tokenizers. Additionally, we employ a cross-modal error-correction framework that generates stego text from stego images to aid in restoring lossy images, ultimately enabling the extraction of secret messages embedded within the images. Extensive experiments have demonstrated that the proposed method provides advantages in stego quality, embedding capacity, and robustness, while ensuring provable undetectability.
Gaussian Shading: Provable Performance-Lossless Image Watermarking for Diffusion Models
Apr 07, 2024Ethical concerns surrounding copyright protection and inappropriate content generation pose challenges for the practical implementation of diffusion models. One effective solution involves watermarking the generated images. However, existing methods often compromise the model performance or require additional training, which is undesirable for operators and users. To address this issue, we propose Gaussian Shading, a diffusion model watermarking technique that is both performance-lossless and training-free, while serving the dual purpose of copyright protection and tracing of offending content. Our watermark embedding is free of model parameter modifications and thus is plug-and-play. We map the watermark to latent representations following a standard Gaussian distribution, which is indistinguishable from latent representations obtained from the non-watermarked diffusion model. Therefore we can achieve watermark embedding with lossless performance, for which we also provide theoretical proof. Furthermore, since the watermark is intricately linked with image semantics, it exhibits resilience to lossy processing and erasure attempts. The watermark can be extracted by Denoising Diffusion Implicit Models (DDIM) inversion and inverse sampling. We evaluate Gaussian Shading on multiple versions of Stable Diffusion, and the results demonstrate that Gaussian Shading not only is performance-lossless but also outperforms existing methods in terms of robustness.