 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWIFT: Sliding Window Reconstruction for Few-Shot Training-Free Generated Video Attribution
Mar 09, 2026Recent advancements in video generation technologies have been significant, resulting in their widespread application across multiple domains. However, concerns have been mounting over the potential misuse of generated content. Tracing the origin of generated videos has become crucial to mitigate potential misuse and identify responsible parties. Existing video attribution methods require additional operations or the training of source attribution models, which may degrade video quality or necessitate large amounts of training samples. To address these challenges, we define for the first time the "few-shot training-free generated video attribution" task and propose SWIFT, which is tightly integrated with the temporal characteristics of the video. By leveraging the "Pixel Frames(many) to Latent Frame(one)" temporal mapping within each video chunk, SWIFT applies a fixed-length sliding window to perform two distinct reconstructions: normal and corrupted. The variation in the losses between two reconstructions is then used as an attribution signal. We conducted an extensive evaluation of five state-of-the-art (SOTA) video generation models. Experimental results show that SWIFT achieves over 90% average attribution accuracy with merely 20 video samples across all models and even enables zero-shot attribution for HunyuanVideo, EasyAnimate, and Wan2.2. Our source code is available at https://github.com/wangchao0708/SWIFT.
Clean Image May be Dangerous: Data Poisoning Attacks Against Deep Hashing
Mar 27, 2025Large-scale image retrieval using deep hashing has become increasingly popular due to the exponential growth of image data and the remarkable feature extraction capabilities of deep neural networks (DNNs). However, deep hashing methods are vulnerable to malicious attacks, including adversarial and backdoor attacks. It is worth noting that these attacks typically involve altering the query images, which is not a practical concern in real-world scenarios. In this paper, we point out that even clean query images can be dangerous, inducing malicious target retrieval results, like undesired or illegal images. To the best of our knowledge, we are the first to study data \textbf{p}oisoning \textbf{a}ttacks against \textbf{d}eep \textbf{hash}ing \textbf{(\textit{PADHASH})}. Specifically, we first train a surrogate model to simulate the behavior of the target deep hashing model. Then, a strict gradient matching strategy is proposed to generate the poisoned images. Extensive experiments on different models, datasets, hash methods, and hash code lengths demonstrate the effectiveness and generality of our attack method.
Provably Secure Robust Image Steganography via Cross-Modal Error Correction
Dec 15, 2024

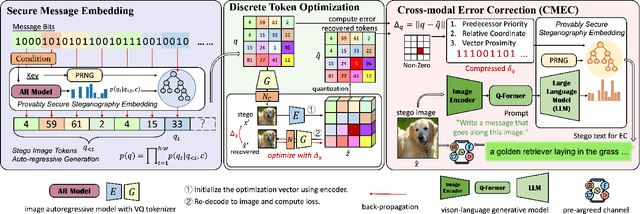
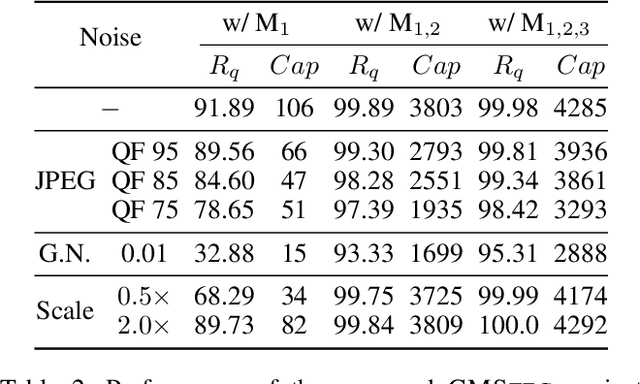
The rapid development of image generation models has facilitated the widespread dissemination of generated images on social networks, creating favorable conditions for provably secure image steganography. However, existing methods face issues such as low quality of generated images and lack of semantic control in the generation process. To leverage provably secure steganography with more effective and high-performance image generation models, and to ensure that stego images can accurately extract secret messages even after being uploaded to social networks and subjected to lossy processing such as JPEG compression, we propose a high-quality, provably secure, and robust image steganography method based on state-of-the-art autoregressive (AR) image generation models using Vector-Quantized (VQ) tokenizers. Additionally, we employ a cross-modal error-correction framework that generates stego text from stego images to aid in restoring lossy images, ultimately enabling the extraction of secret messages embedded within the images. Extensive experiments have demonstrated that the proposed method provides advantages in stego quality, embedding capacity, and robustness, while ensuring provable undetectability.
Provably Secure Disambiguating Neural Linguistic Steganography
Mar 26, 2024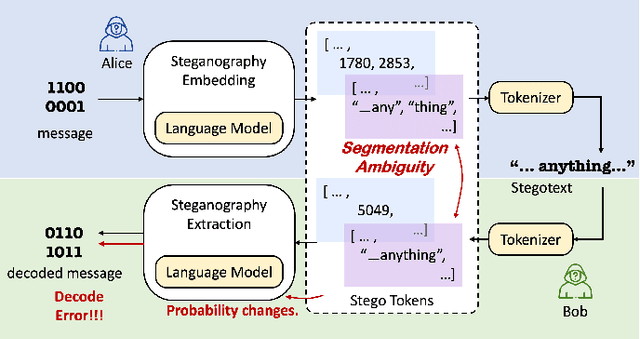
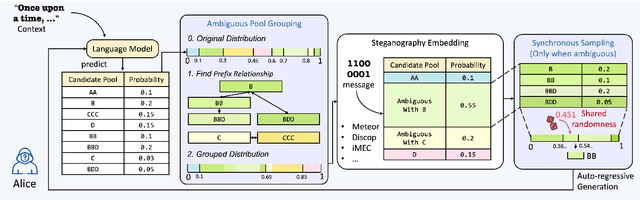
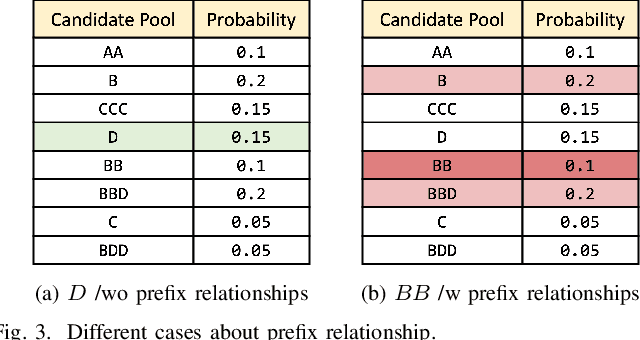
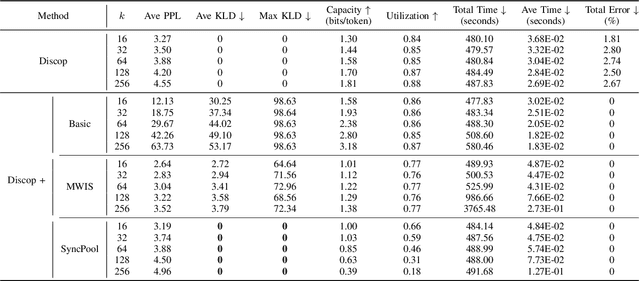
Recent research in provably secure neural linguistic steganography has overlooked a crucial aspect: the sender must detokenize stegotexts to avoid raising suspicion from the eavesdropper. The segmentation ambiguity problem, which arises when using language models based on subwords, leads to occasional decoding failures in all neural language steganography implementations based on these models. Current solutions to this issue involve altering the probability distribution of candidate words, rendering them incompatible with provably secure steganography. We propose a novel secure disambiguation method named SyncPool, which effectively addresses the segmentation ambiguity problem. We group all tokens with prefix relationships in the candidate pool before the steganographic embedding algorithm runs to eliminate uncertainty among ambiguous tokens. To enable the receiver to synchronize the sampling process of the sender, a shared cryptographically-secure pseudorandom number generator (CSPRNG) is deployed to select a token from the ambiguity pool. SyncPool does not change the size of the candidate pool or the distribution of tokens and thus is applicable to provably secure language steganography methods. We provide theoretical proofs and experimentally demonstrate the applicability of our solution to various languages and models, showing its potential to significantly improve the reliability and security of neural linguistic steganography systems.
GPT Paternity Test: GPT Generated Text Detection with GPT Genetic Inheritance
May 21, 2023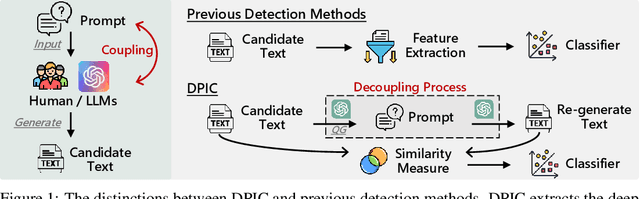
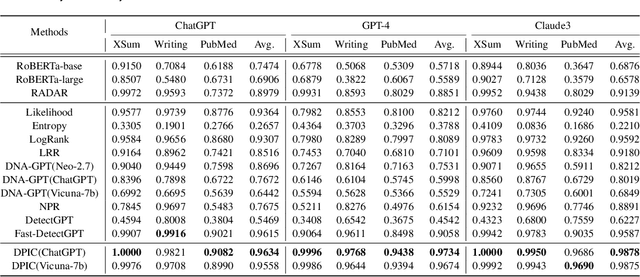
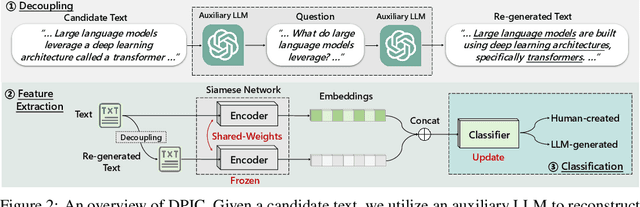
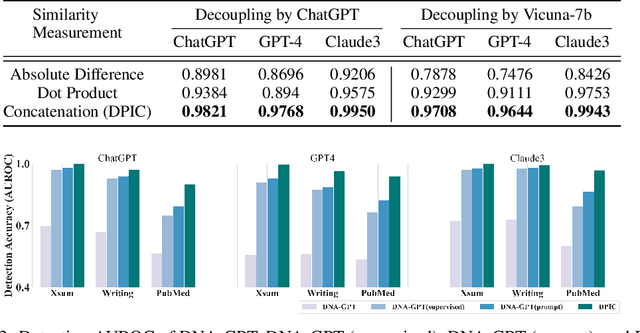
Large Language Models (LLMs) can generate texts that carry the risk of various misuses, including plagiarism, planting fake reviews on e-commerce platforms, or creating fake social media postings that can sway election results. Detecting whether a text is machine-generated has thus become increasingly important. While machine-learning-based detection strategies exhibit superior performance, they often lack generalizability, limiting their practicality. In this work, we introduce GPT Paternity Test (GPT-Pat), which reliably detects machine-generated text across varied datasets. Given a text under scrutiny, we leverage ChatGPT to generate a corresponding question and provide a re-answer to the question. By comparing the similarity between the original text and the generated re-answered text, it can be determined whether the text is machine-generated. GPT-Pat consists of a Siamese network to compute the similarity between the original text and the generated re-answered text and a binary classifier. Our method achieved an average accuracy of 94.57% on four generalization test sets, surpassing the state-of-the-art RoBERTa-based method by 12.34%. The accuracy drop of our method is only about half of that of the RoBERTa-based method when it is attacked by re-translation and polishing.
Watermarking Text Generated by Black-Box Language Models
May 14, 2023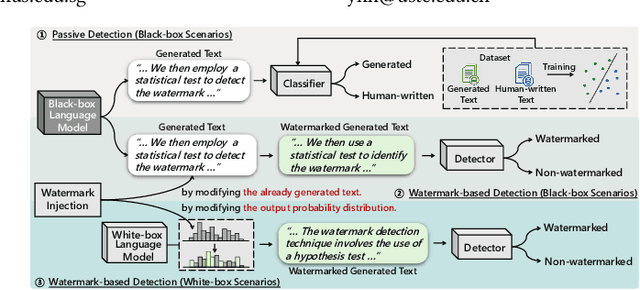
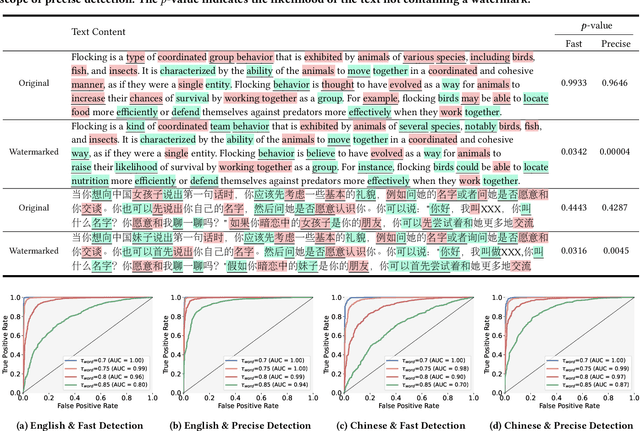
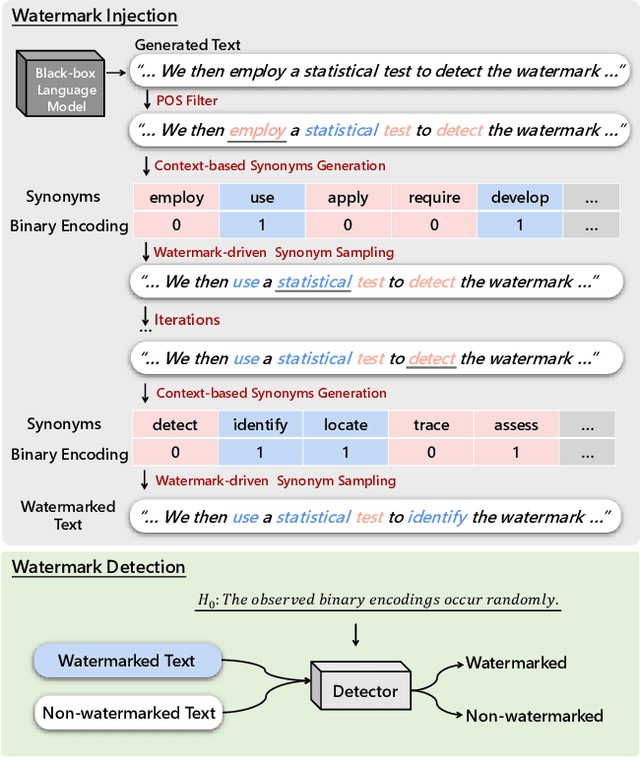

LLMs now exhibit human-like skills in various fields, leading to worries about misuse. Thus, detecting generated text is crucial. However, passive detection methods are stuck in domain specificity and limited adversarial robustness. To achieve reliable detection, a watermark-based method was proposed for white-box LLMs, allowing them to embed watermarks during text generation. The method involves randomly dividing the model vocabulary to obtain a special list and adjusting the probability distribution to promote the selection of words in the list. A detection algorithm aware of the list can identify the watermarked text. However, this method is not applicable in many real-world scenarios where only black-box language models are available. For instance, third-parties that develop API-based vertical applications cannot watermark text themselves because API providers only supply generated text and withhold probability distributions to shield their commercial interests. To allow third-parties to autonomously inject watermarks into generated text, we develop a watermarking framework for black-box language model usage scenarios. Specifically, we first define a binary encoding function to compute a random binary encoding corresponding to a word. The encodings computed for non-watermarked text conform to a Bernoulli distribution, wherein the probability of a word representing bit-1 being approximately 0.5. To inject a watermark, we alter the distribution by selectively replacing words representing bit-0 with context-based synonyms that represent bit-1. A statistical test is then used to identify the watermark. Experiments demonstrate the effectiveness of our method on both Chinese and English datasets. Furthermore, results under re-translation, polishing, word deletion, and synonym substitution attacks reveal that it is arduous to remove the watermark without compromising the original semantics.